
ACCV2020国际细粒度网络图像识别亚军方案总结

极市导读
作者为ACCV2020细粒度图像分类分析竞赛第二名,本文分享了比赛各阶段的准备以及需要注意的要点和经验,分享给大家作为参考。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
细粒度图像分类竞赛分析总结

大赛官网:https://www.cvmart.net/race/9917/base
背景介绍
ACCV大会(Asian Conference on Computer Vision)是由亚洲计算机视觉联合会举办的两年一次的计算机视觉领域国际重要会议。该会议为研究者、开发者以及参与者提供了一个重要的论坛,以展示和讨论计算机视觉及相关领域的新问题、新方法和新技术。
ACCV 2020 国际细粒度网络图像识别竞赛,是由南京理工大学、英国爱丁堡大学、南京大学、阿德莱德大学、日本早稻田大学等研究机构主办,极市平台提供技术支持的国际性赛事。该赛事主要关注网络图像监督条件下的细粒度级别图像识别问题。
官方提供的训练数据是55W+的网络数据,其中存在大量的噪声样本。对于计算资源以及人工成本要求都很高。
成绩

数据分析
在竞赛刚开始的时候,我们对训练数据进行了详细的分析。我们发现:
训练数据集中存在大量噪声样本,比如地图,表格,文本,人物特写等(noisetype1)。
测试数据集比训练数据集干净很多。
很多动物类别的图片中都会包含植物,但是绝大多数的植物类别的图片中都不包含动物。
small animal problem,一些动物在图片中的占比非常小。
这些结论对本次竞赛起到了很大的作用。
比赛中也有通过数据分析一招制胜的例子:[1]
作者发现数据中存在二义性图片,比赛数据量很小,这些图对模型效果影响很大,最后通过knowledge distillation方式对数据进行soft label 处理。个人理解这种二义性图片还是能够给模型提供有用信息的,通过软标签的方式能够减弱他们对模型训练的影响,让模型能够去学习更有用的信息。这种方法在大数据集上操作起来时间成本很高,但是相对于删除这些数据而言,我理解保留不处理可能更好一些。另外这个比赛也是大型B榜翻车现场,刺激又酸爽。
数据清洗
在数据处理阶段,我们通过主动学习的方法删除了约5000张左右的噪声数据。具体的,我们把测试集作为正样本,训练集中的噪声数据作为负样本,训练一个efficientnet-b2二分类网络,然后在训练集全量数据打分。在分数低的图片中人工挑选噪声数据,迭代三次。清洗数据真的是枯燥无味而又非常有效,是对人的体力耐力的考验。
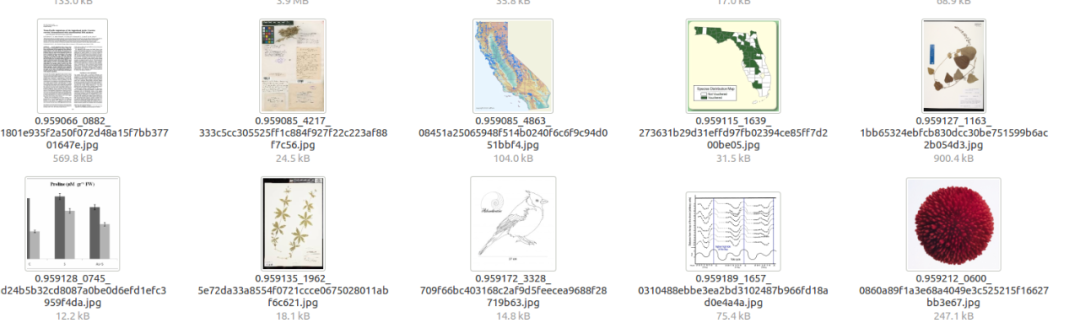
另外一个版本的数据我们删除了50000左右的图片,不过没有人工校验,可能包含一部分正确的样本。这里主要是想制作一个与google landmark recognization(GLR) 比赛一样的数据环境,先在clean数据训再全量数据训练。GLR top solution中有的队伍在全量数据训练得到了更好的结果。由于时间原因我们不可能在两组数据中完成模型的训练,最终选择相信更多的数据,没有针对这份数据进行实验。
模型
在本次竞赛中,我们选择了efficientnet-b4/b5 with noise student pretrained model 作为我们base model, 细粒度比赛中有人提出ns的预训练参数更好[2][3]
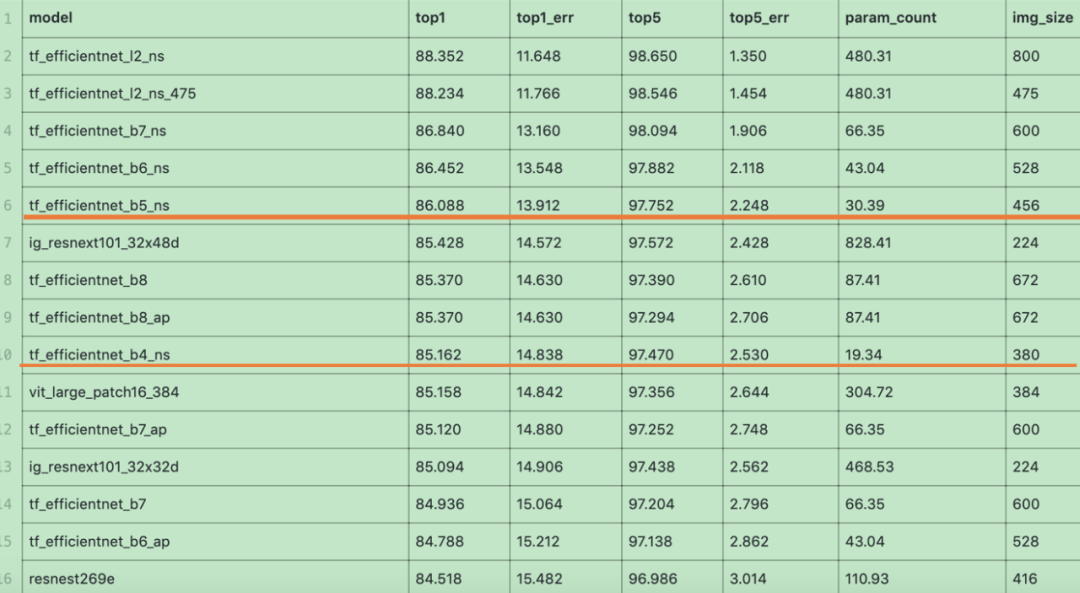
timm模型库efficient-ns经常出现在各大比赛的top solution中,在选模型的时候直接用的ns weights。另外timm 作者还有一个关于efficientdet-pytorch的复现工作,性能非常给力。
由于训练数据和测试数据差异巨大以及对计算资源的自信,我们是不可能训练多个fold的。所以没有在本地划分验证集,使用全部数据进行模型训练,并通过A榜 来判断模型效果。训练过程中,我们使用了cut-mix,auto-augment等数据增强方式,label smooth在我训过的大部分数据上不会变差,默认配置。以及大幅度借鉴imagenet模型训练技巧。我们使用了 very large image-size 来解决small animal problem。其实我们也尝试过B7,训得太慢两天后放弃了。关于focal loss,从来没有在分类模型中提分成功过,而且训练数据噪声那么大,没试也没在todolist。
其实图像尺寸在分类问题中很多是越大越好的[2][4],增加分辨率带来的性能收益比很多技巧来的更实在。但是在公开的解决方案中关于图像尺寸的说明都不是很明确。
我们最优的efficientnet-b4 在leadboard A 上取得了63.91%的成绩。在整个比赛期间,我们没有发现任何的过拟合现象 before 100 epochs,larger image size,more complex model and more training epochs always get better result。继续往后训可能还有提升。
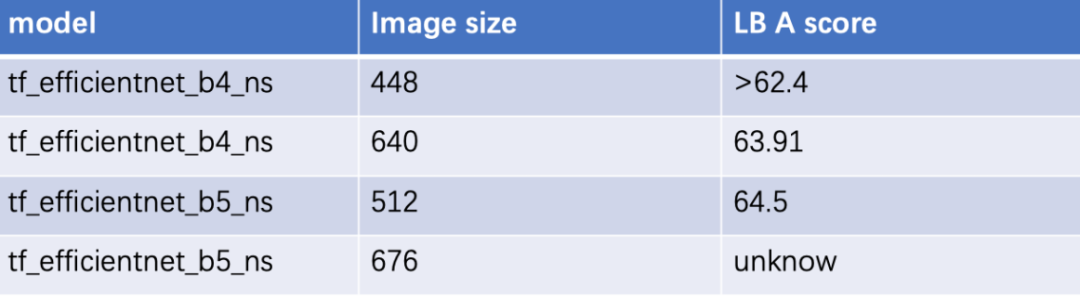
在该赛题中,模型融合带来的性能提升非常明显(细粒度分类问题的特色?)。在融合了4个模型后,我们在leadboard A获得了67.275的分数。
TopK Strategy
我们发现测试集每个类别的样本数量基本相同。至于怎么发现的也不难。一般来说测试集分布是均匀的要么和训练集差不多,但是这个赛题是均匀分布的概率更大,再加上100000/5000=20基本就知道了,最后在老测试集验证确实是这样。
知道了这条规律后,我们统计模型预测到各个类别的图片数量,并用top1分数排序。从图片数量最多的类别(该类别图片数要超过20的),这个类别top1分数最低的图片(排在20之后的)开始,将它移到top2的类别,如果top2类别图像数量已经超过20张,那么就移到top3... 这里我也做了不少的实验,包括这个20改成一个大一点的数,包括每个类别从所有的图片中抽20张。但是都没有与直接一次简单的移动比显著提分。
其实类似的想法在很多其他的比赛中都有用到。[3][5]
Plabel
大多数情况下伪标签是稳定上分的,有些solution 会采取多轮伪标签上分。[6][7]
长尾分布
我没有试过bbn,但是常见的处理训练数据长尾分布的方法是2stage 训练[3][4],我们觉得这次比赛的数据分布还算好,没有进行额外处理。
END
以上是我认为比较有用的东西。最后,我只是个小菜鸡,但是很多时候自己动手可能学到的更多,再说别人写的东西也不一定对。如果不敢用'年'做单位去学习长进,我们又凭什么去祈求回报。
[1]https://www.kaggle.com/c/plant-pathology-2020-fgvc7/discussion/154056
[2] https://www.kaggle.com/c/plant-pathology-2020-fgvc7/discussion/154045
[3] https://www.kaggle.com/c/herbarium-2020-fgvc7/discussion/154351
[4] https://www.kaggle.com/c/landmark-recognition-2020/discussion/187757
[5] https://www.kaggle.com/c/herbarium-2020-fgvc7/discussion/154186
[6] https://www.kaggle.com/c/plant-pathology-2020-fgvc7/discussion/155929
[7] https://www.kaggle.com/c/global-wheat-detection/discussion/172418
推荐阅读
