本文约3500字,建议阅读14分钟
本文文章简要介绍了研究人员在图像识别算法和图像数据方面的演变,并总结了现在的一些热门话题。
三十多年来,许多研究人员在图像识别算法和图像数据方面积累了丰富的知识。如果你对图像训练感兴趣但不知道从哪里开始,这篇文章会是一个很好的开始。这篇文章简要介绍了过去的演变,并总结了现在的一些热门话题。ImageNet 的起源
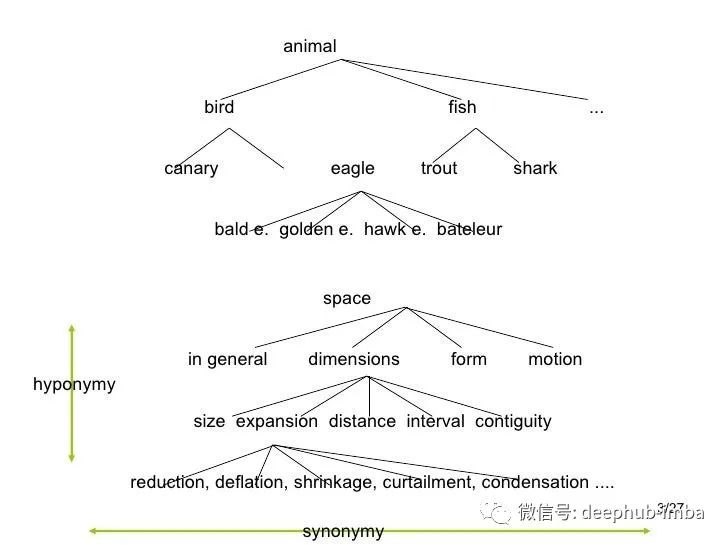
在 2000 年代初期,大多数 AI 研究人员都专注于图像分类问题的模型算法,但缺乏数据样本,研究人员需要大量图像和相应的标签来训练模型。这激发了 ImageNet 的创建。ImageNet 由斯坦福大学的人工智能研究员李飞飞老师构思和带头组建。2007 年,当她开始构思 ImageNet 的想法时,她会见了普林斯顿大学教授 Christiane Fellbaum(WordNet 的创建者之一),并讨论了该项目。WordNet 是用于名词、动词、形容词和副词之间语义关系的词汇自然语言处理 (NLP) 数据库。它有 155,327 个词,组织在 175,979 个同义词组中,称为同义词组(有些词只有一个同义词组,有些词有几个同义词组)。如果在 WordNet 中将图像附加到单词上不是很好吗?这就是 ImageNet 的起源。ImageNet 将成百上千的图像与 WordNet 中的同义词集相关联。从那时起,ImageNet 在计算机视觉和深度学习的进步中发挥了重要作用。这些数据可供研究人员免费用于非商业用途。ImageNet 数据库有超过 1400 万张图像 (14,197,122),分为 21,841 个子类别。数据集中的每张图像都由人工注释,并通过多年的工作进行质量控制。ImageNet 中的大多数同义词集是名词(80,000+),总共有超过 100,000 个同义词集。因此,ImageNet 是一个组织良好的层次结构,可用于监督机器学习任务。可以通过 ImageNet 网站注册自己免费访问 ImageNet。借助庞大的图像数据库,研究人员可以随意开发他们的算法。著名的 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 来了。这是 2010 年至 2017 年间举办的年度计算机视觉竞赛。它也被称为 ImageNet 挑战赛。挑战中的训练数据是 ImageNet 的一个子集:1,000 个同义词集(类别)和 120 万张图像。这也就是我们常看到的ImageNet 1K或者说为什么我们看到的预训练模型的类别都是1000,这就是原因。什么是预训练模型?
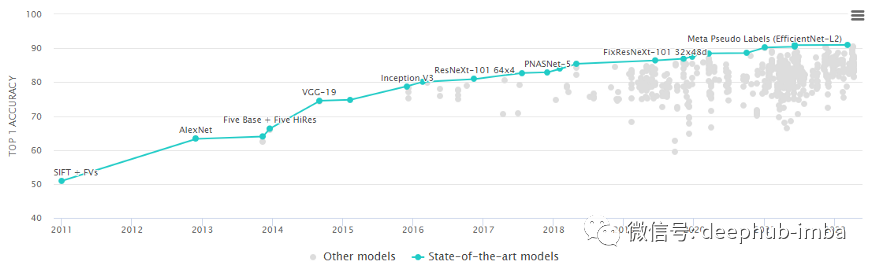
这个竞赛激励并奖励了许多出色的图像分类模型。这些模型的训练都需要非常大规模、耗时且 CPU/GPU 密集型的计算。 每个模型都包含代表 ImageNet 中图像特征的权重和偏差。它们被称为预训练模型,因为其他研究人员可以使用它们来解决类似的问题。LeNet-5 (1989):经典的 CNN 框架LeNet-5 是最早的卷积神经网络。该框架很简单,因此许多类将其用作引入 CNN 的第一个模型。1989 年,Yann LeCun 等人。在贝尔实验室结合了一个由反向传播算法训练的卷积神经网络来读取手写数字,并成功地将其应用于识别美国邮政服务提供的手写邮政编码号码。所以此处应该有一张LeCun老师的照片 AlexNet 在 2012 年 ImageNet 挑战赛中上台,因为它以非常大的优势获胜。它实现了 17% 的top5错误率,而第二名的错误率为 26%。它的架构与 LeNet-5 非常相似。它由 Alex Krizhevsky ,Ilya Sutskever ,以及Krizhevsky 的博士导师 Geoffrey Hinton 合作设计。 该模型有 6000 万个参数和 500,000 个神经元。可以将他看作是一个大号的LeNet。它是由 Christian Szegedy 等人开发的。来自谷歌研究。这个模型的参数比 AlexNet 少 10 倍,大约 600 万。在牛津大学的 K. Simonyan 和 A. Zisserman 的带领下,VGG-16 模型在他们的论文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出。他们使用非常小的 (3x3) 卷积滤波器将深度增加到 16 层和 19 层。这种架构显示出显着的改进。VGG-16 名称中的“16”指的是 CNN 的“16”层。它有大约 1.38 亿个参数。显然 VGG-19 比 VGG-16 大。VGG-19 只提供比 VGG-16 稍微好一些的精度,所以很多人使用 VGG-16。深度神经网络的层通常旨在学习尽可能多的特征。Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun 在他们的论文“Deep Residual Learning for Image Recognition”中提出了一种新的架构。他们提出了一个残差学习框架。这些层被公式化为参考层输入的学习残差函数,而不是学习未参考的函数。他们表明,这些残差网络更容易优化,并且可以从显着增加的深度中获得准确性。ResNet-50 中的“50”指的是 50 层。ResNet 模型在 ImageNet 挑战赛中仅以 3.57% 的错误率赢得了比赛。VIT等新技术,想必大家也都熟悉了,这里就不多介绍了
AlexNet 在 2012 年 ImageNet 挑战赛中上台,因为它以非常大的优势获胜。它实现了 17% 的top5错误率,而第二名的错误率为 26%。它的架构与 LeNet-5 非常相似。它由 Alex Krizhevsky ,Ilya Sutskever ,以及Krizhevsky 的博士导师 Geoffrey Hinton 合作设计。 该模型有 6000 万个参数和 500,000 个神经元。可以将他看作是一个大号的LeNet。它是由 Christian Szegedy 等人开发的。来自谷歌研究。这个模型的参数比 AlexNet 少 10 倍,大约 600 万。在牛津大学的 K. Simonyan 和 A. Zisserman 的带领下,VGG-16 模型在他们的论文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出。他们使用非常小的 (3x3) 卷积滤波器将深度增加到 16 层和 19 层。这种架构显示出显着的改进。VGG-16 名称中的“16”指的是 CNN 的“16”层。它有大约 1.38 亿个参数。显然 VGG-19 比 VGG-16 大。VGG-19 只提供比 VGG-16 稍微好一些的精度,所以很多人使用 VGG-16。深度神经网络的层通常旨在学习尽可能多的特征。Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun 在他们的论文“Deep Residual Learning for Image Recognition”中提出了一种新的架构。他们提出了一个残差学习框架。这些层被公式化为参考层输入的学习残差函数,而不是学习未参考的函数。他们表明,这些残差网络更容易优化,并且可以从显着增加的深度中获得准确性。ResNet-50 中的“50”指的是 50 层。ResNet 模型在 ImageNet 挑战赛中仅以 3.57% 的错误率赢得了比赛。VIT等新技术,想必大家也都熟悉了,这里就不多介绍了迁移学习技术
人类善于学习知识并将知识转移到类似的任务中。当我们遇到新任务时,我们会识别并应用以前学习经验中的相关知识。迁移学习技术是一项伟大的发明。它“转移”在先前模型中学习的知识,以改进当前模型中的学习。考虑任何具有数百万个参数的预训练模型。他们在模型参数中学习了图像的特征。如果其他的任务相似,那么利用预训练模型中的知识(参数)。迁移学习技术不需要重复训练大型模型的轮子,可以利用预训练模型来完成类似的任务,并且可以依赖更少的数据。如果有一组新图像并且需要构建自己的图像识别模型,可以在神经网络模型中包含一个预先训练好的模型。因此,迁移学习技术成为近年来的热门话题。可以预见两个研究前沿:(i)预训练模型将继续发展,(ii)将产生越来越多的迁移学习模型以满足特定需求。使用预训练模型识别未知图像
在本节中,将展示如何使用 VGG-16 预训练模型来识别图像,包括 (i) 如何加载图像,(ii) 如何格式化预训练模型所需的图像,以及 (iii) 如何应用预训练模型。在图像建模中,PyTorch 或 TensorFlow 或 Keras 已被研究人员广泛使用。PyTorch 是 Facebook 的 AI 研究实验室基于 Torch 库开发的基于 Python 的开源机器学习库。由于其最大的灵活性和速度,它以深度学习计算而闻名。其应用包括图像识别、计算机视觉和自然语言处理。它是 NumPy 的替代品,可以使用 GPU 的强大运算能力。Google 的 TensorFlow 是另一个著名的开源深度学习库,用于跨一系列任务的数据流和可微分编程。PyTorch 或 TensorFlow 都非常适合 GPU 计算。PyTorch 在其库中包含了许多预训练模型。从这个长长的 Pytorch 模型列表中选择一个预训练模型。下面我选择 VGG-16 并称之为“vgg16”。import ioimport torchfrom PIL import Imageimport requestsfrom torch.autograd import Variableimport torchvision.models as modelsimport torchvision.transforms as transforms
vgg16 = models.vgg16(pretrained=True) vgg16
上面的第 10 行加载了 VGG-16 模型。可以将其打印出来以查看其架构,如下所示:如前所述,VGG-16 在 ImageNet 挑战赛中使用了 1,000 个类别和 120 万张图像的训练。下面我将它保存到本地目录“/downloads”并加载到一个名为“labels”的列表中。
with open("/Downloads/imagenet_classes.txt", "r") as f: labels = [s.strip() for s in f.readlines()]
在下面的第 2 行中,我用搜索了“金鱼”,并从图片中随机选择了一张金鱼图片。在第 3 行中,我还搜索了老鹰,并随机选择了一张带有图片地址的老鹰图片。import urlliburl, filename = ("https://cff2.earth.com/uploads/2022/01/06080341/Goldfish.jpg?raw=true", "goldfish.jpg")url, filename = ("https://cdn.britannica.com/92/152292-050-EAF28A45/Bald-eagle.jpg?raw=true", "eagle.jpg")
try: urllib.URLopener().retrieve(url, filename)except: urllib.request.urlretrieve(url, filename)
from PIL import Imagefrom torchvision import transformsinput_image = Image.open(filename).convert('RGB')print(input_image.size)input_image.show()
图像可以由 Python Imaging Library(缩写为 PIL,或称为 Pillow 的较新版本)加载。第 13 行:图像的大小为 (1600,1071)。这意味着图像是一个 1,600 x 1,071 像素的文件。preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])input_tensor = preprocess(input_image)input_tensor.shape input_batch = input_tensor.unsqueeze(0) input_tensor.shape
if torch.cuda.is_available(): input_batch = input_batch.to('cuda') model.to('cuda')
所有预训练模型都期望输入图像以相同的方式归一化,即形状为 (3 x H x W) 的 3 通道 RGB 图像的小批量,其中 H 和 W 至少为 224。第 2、3 行:将图像尺寸标准化为 [3,224,224]。第 5 行:使用 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 对图像进行归一化。output = vgg16(input_batch)
probabilities = torch.nn.functional.softmax(output[0], dim=0)
第1行是最重要的一步。它预测图像是什么。输出是包含 1,000 个 ImageNet 同义词集的 1,000 个值的列表。top5_prob, top5_catid = torch.topk(probabilities, 5)for i in range(top5_prob.size(0)): print(labels[top5_catid[i]], top5_prob[i].item())
上面的代码打印前五个概率和标签。我们输入了一个鹰的形象。VGG-16 模型将图像识别为“鹰”的概率为 0.9969。总结
这篇文章总结了图像与训练模型的起源并且包含了一个使用的入门级示例,如果你对代码感兴趣,请在这里下载:https://github.com/dataman-git/codes_for_articles/blob/master/VGG-16.ipynb