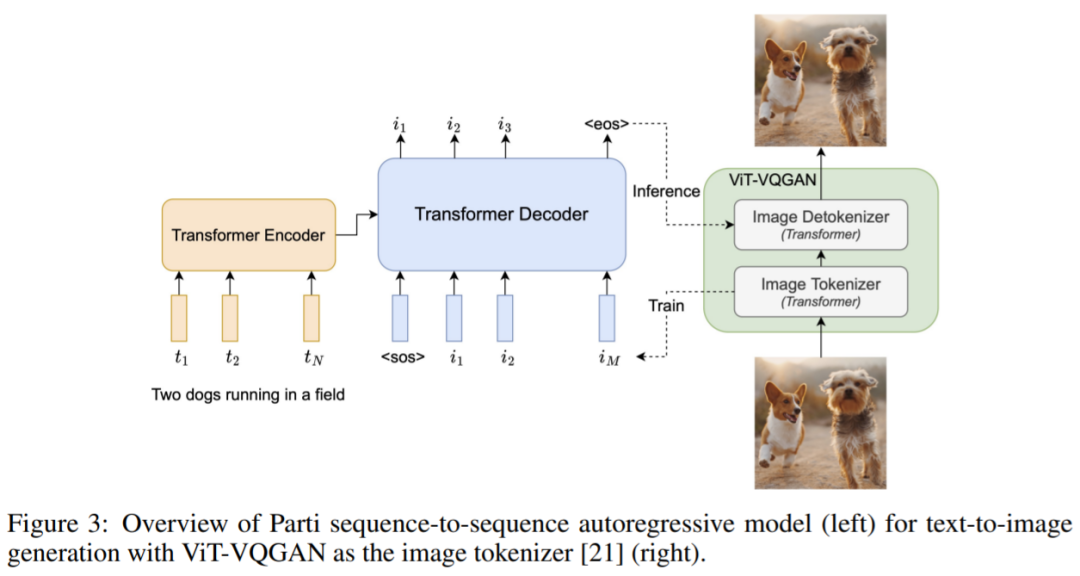
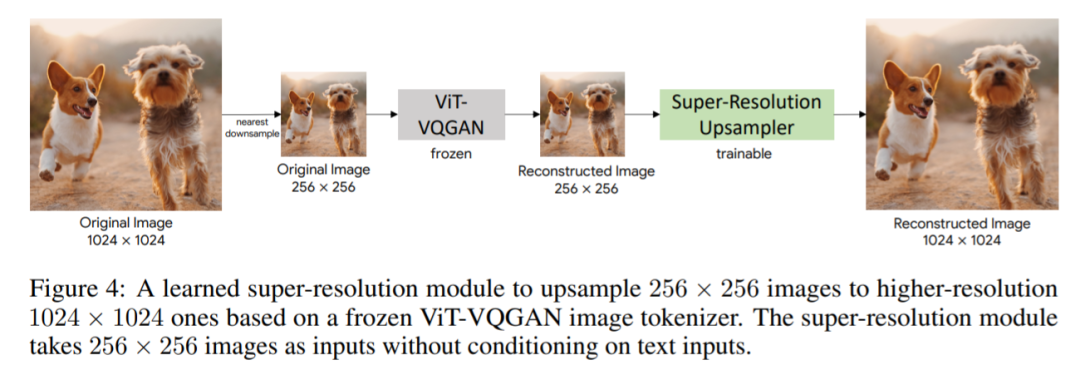
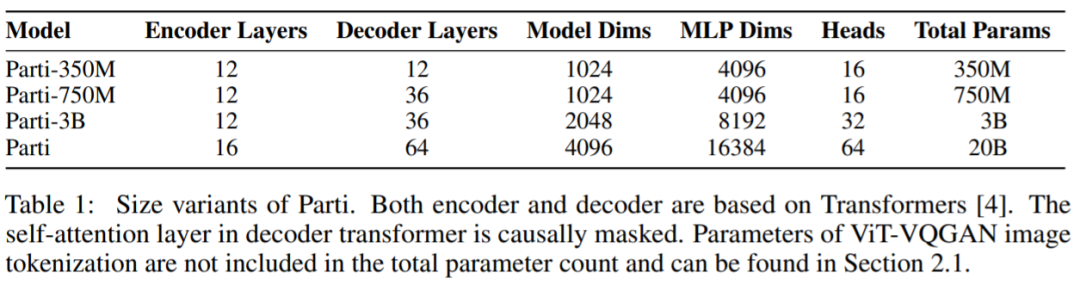
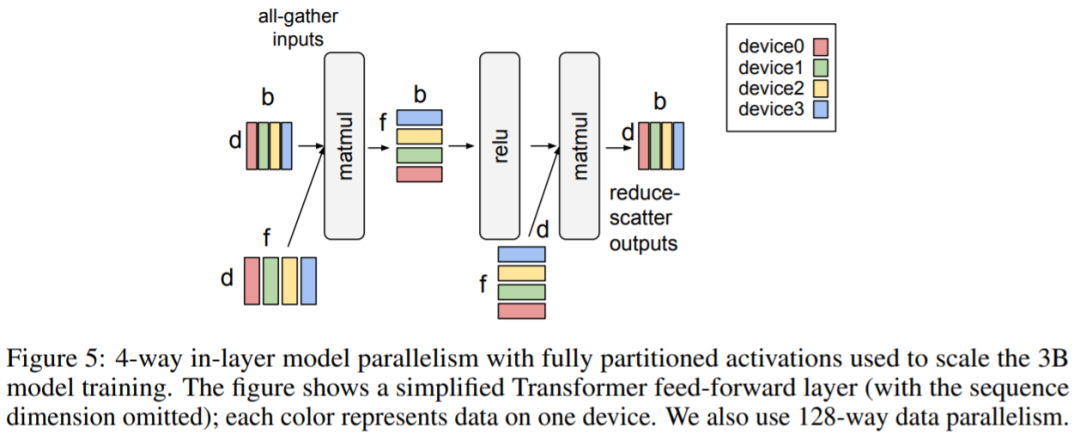
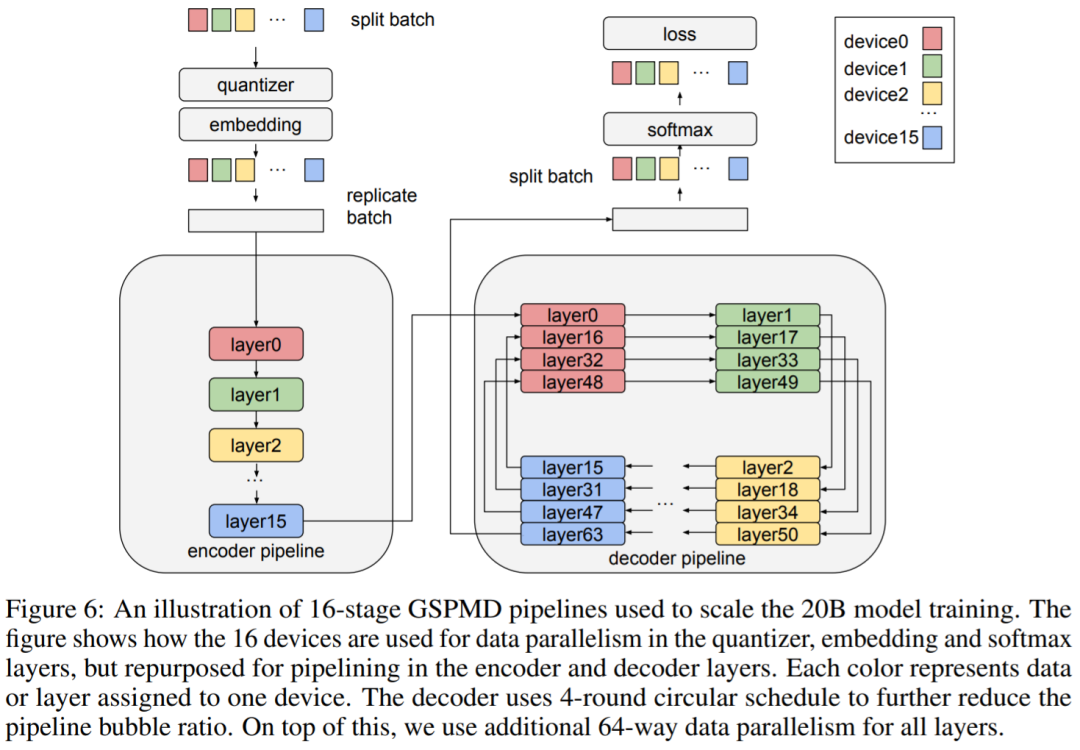
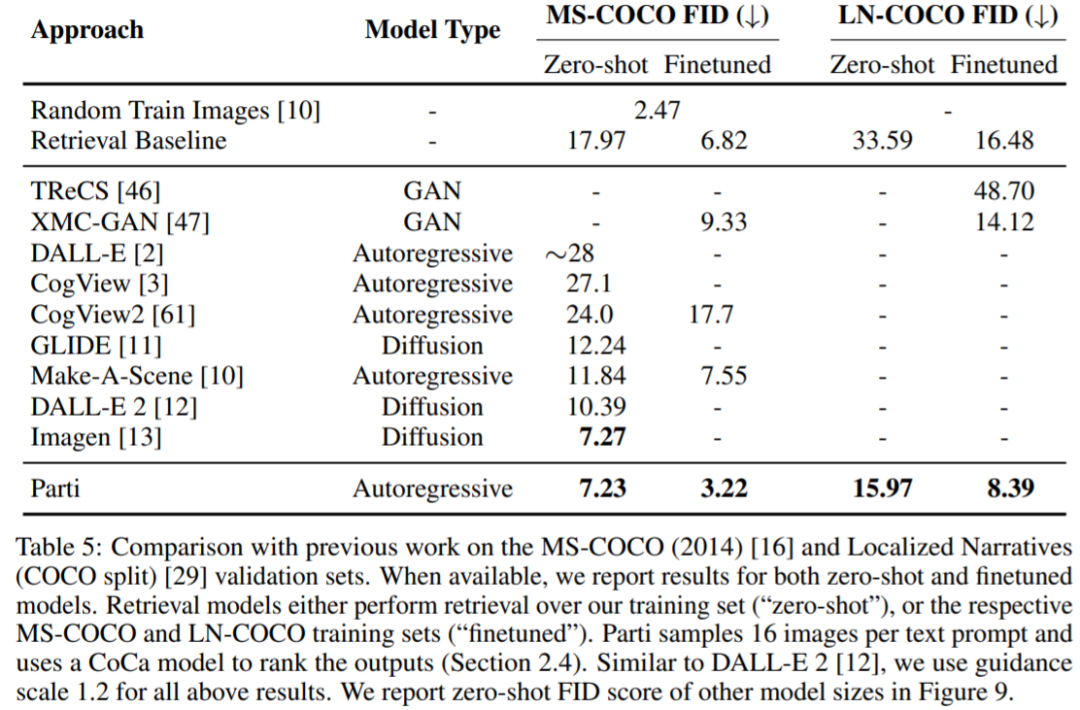
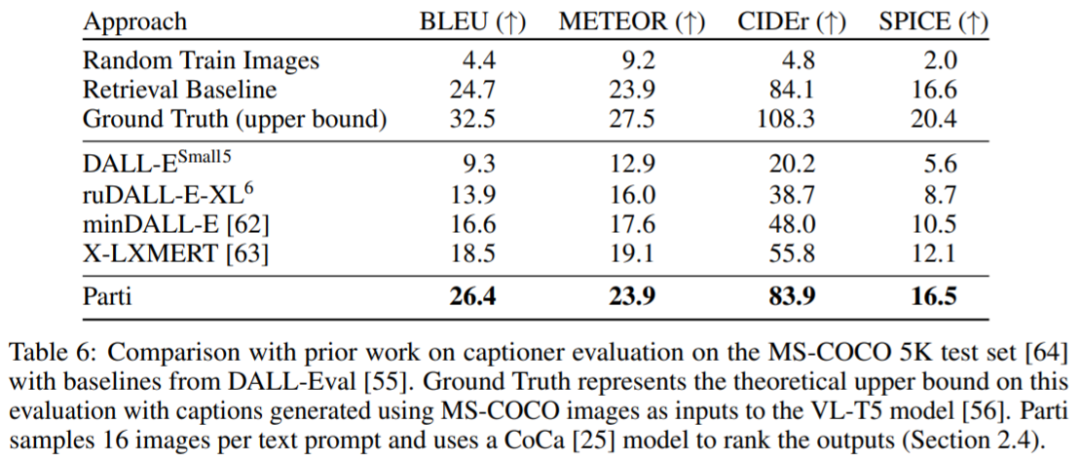
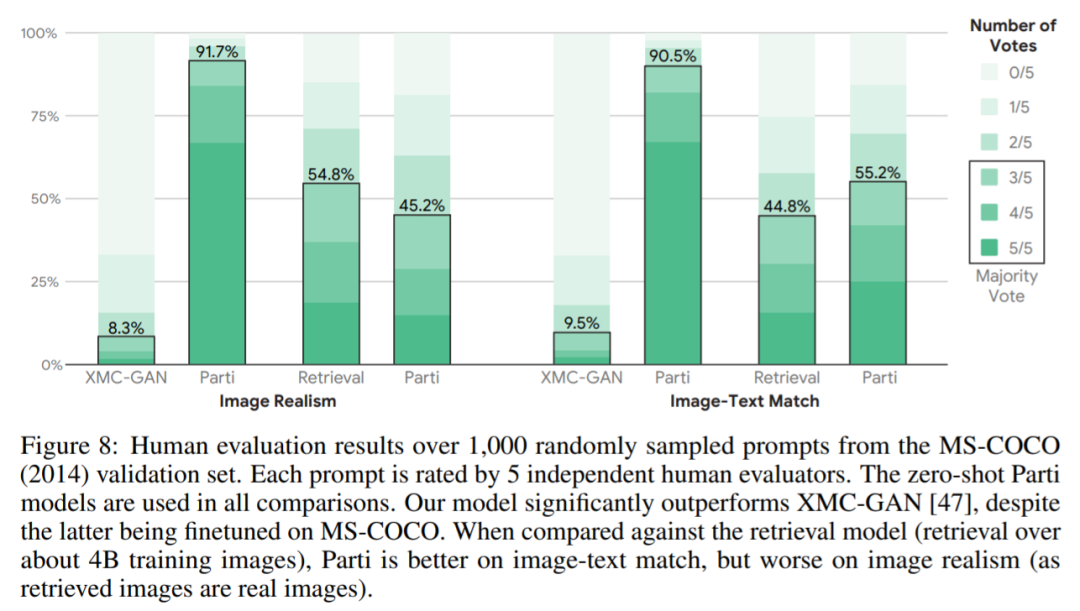
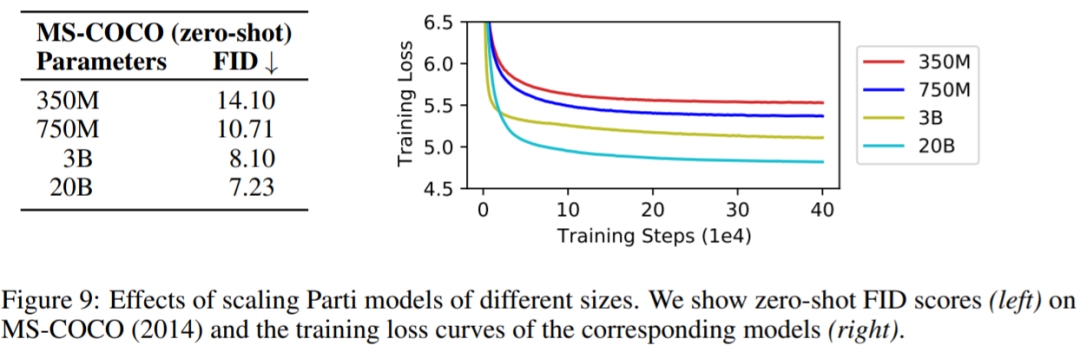
谷歌开始卷自己,AI架构Pathways加持,推出200亿生成模型视学算法关注共 2678字,需浏览 6分钟 ·2022-06-27 16:51 视学算法报道机器之心编辑部继 Imagen 后,谷歌又推出了文本 - 图像生成模型 Parti。你见过一只小狗破壳而出吗?或者用飞艇俯瞰蒸汽朋克中的城市?又或者两个机器人在电影院像人类一样看电影…… 这些听起来可能有些天马行空,但一种名为「文本到图像生成」的新型机器学习技术使这些成为可能。谷歌研究院的科学家和工程师一直致力于探索使用各种 AI 技术生成文本到图像的方法。今年 5 月底,谷歌推出 AI 创作神器 Imagen,它结合了 Transformer 语言模型和高保真扩散模型的强大功能,在文本到图像的合成中提供前所未有的逼真度和语言理解能力。与仅使用图像 - 文本数据进行模型训练的先前工作相比,Imagen 的关键突破在于:谷歌的研究者发现在纯文本语料库上预训练的大型 LM 的文本嵌入对文本到图像的合成显著有效。Imagen 的文本到图像生成可谓天马行空,能生成多种奇幻却逼真的有趣图像。Imagen 生成效果是这样的,比如正在户外享受骑行的柴犬(下图左)以及狗狗照镜子发现自己是只猫(下图右):时隔没多久,谷歌又推出了 Parti(Pathways Autoregressive Text-to-Image),该模型最高可扩展至 200 亿参数,并且随着可使用参数数量的增长,其输出的图像也能够更加逼真。值得一提的是,这是谷歌大牛 Jeff Dean 提出的多任务 AI 大模型蓝图 Pathways 的一部分。我们先来看下 Parti 效果,袋熊在瀑布旁,背着书包,拄着拐杖眺望着远方:埃及阿努比斯肖像,在洛杉矶背景下,戴着飞行员护目镜,穿着白色 t 恤和黑色皮夹克:一只熊猫戴着一顶巫师帽骑在马上:下面我们介绍一下 Parti 的实现原理。Parti 模型与 DALL-E、CogView 和 Make-A-Scene 类似,Parti 是一个两阶段模型,由图像 tokenizer 和自回归模型组成,如下图 3 所示。第一阶段训练一个 tokenizer,该 tokenizer 可以将图像转换为一系列离散的视觉 token,用于训练并在推理时重建图像。第二阶段训练从文本 token 生成图像 token 的自回归序列到序列模型。图像 Tokenizer首先,该研究训练了一个 ViT-VQGAN-Small 模型(8 个块,8 个头,模型维度 512,隐藏维度 2048,总参数约为 30M),并且学习了 8192 张图像 token 类别用于代码本。为了进一步提高第二阶段编码器 - 解码器训练后重建图像的视觉灵敏度,该研究冻结了 tokenizer 的编码器和代码本,并微调更大尺寸的 tokenizer 解码器(32 个块,16 个头,模型维度 1280,隐藏维度 5120, 总参数约 600M)。图像 tokenizer 的输入和输出使用 256×256 分辨率。最后,虽然分辨率为 256×256 的图像捕获了大部分内容、结构和纹理,但更高分辨率的图像具有更大的视觉冲击力。为此,该研究在图像 tokenizer 上采用了一个简单的超分辨率模块,如下图 4 所示。文本到图像生成的编码器 - 解码器架构如上图 3 所示,该研究第二阶段训练了一种标准的编码器 - 解码器 Transformer 模型,将文本到图像视为序列到序列建模问题。该模型将文本作为输入,并使用从第一阶段图像 tokenizer 生成的光栅化图像潜在代码的下一个 token 预测进行训练。对于文本编码,该研究构建了一个 sentence-piece 模型,词汇量为 16000。在推理时,模型对图像 token 进行自回归采样,随后使用 ViT-VQGAN 解码器将其解码为像素。该研究使用的文本 token 最大为 128,图像 token 的长度固定为 1024。所有模型都使用 conv-shaped 掩码稀疏注意力。该研究训练了四种变体,参数量从 3.5 亿到 200 亿不等,如下表 1 所示。以下为对 Parti 模型四种大小比较结果,可以观察到:模型性能和输出图像质量在持续地提高;20B 模型尤其擅长于那些抽象的、需要世界知识的、特定视角的、或符号渲染的 prompt。在悉尼歌剧院前的草地上,一只袋鼠穿着橙色卫衣,戴着蓝色墨镜,胸前挂着「欢迎朋友」的牌子。松鼠把苹果送给了小鸟。文本编码器预训练该研究在两个数据集上预训练文本编码器:具有 BERT [36] 预训练目标的 Colossal Clean Crawled Corpus (C4) [35],以及具有对比学习目标的图像文本数据。预训练后,该研究继续训练编码器和解码器,在 8192 个离散图像 token 的词汇表上使用 softmax 交叉熵损失生成文本到图像。预训练后的文本编码器在 GLUE 上的性能与 BERT 相当;然而,在文本到图像生成的完整编码器 - 解码器训练过程之后,文本编码器会降级。扩展该研究在 Lingvo 上来实现模型,并在 CloudTPUv4 硬件上使用 GSPMD 进行扩展,以用于训练和推理。GSPMD 是一个基于 XLA 编译器的模型分布系统,它允许将 TPU 集群视为单个虚拟设备,并在几个张量上使用 sharding annotations 来指示编译器自动分发数据并在数千个设备上进行计算。该研究用数据并行性训练 350M 和 750M 模型。对于 3B 模型,该研究使用 4 路内层模型并行(参见下图 5)和 128 路数据并行。下图 6 为分布式训练策略整体架构图:实验下表 5 给出了自动图像质量评估的主要结果。与基于扩散的 Imagen 模型相比,Parti 获得了相媲美的零样本 FID 分数。下表 6 为 Parti 字幕评估结果(captioner evaluation [55]),Parti 优于其他模型:下图 8 显示,尽管 Parti 没有接受过 MS-COCO 字幕或图像方面的训练,但表现更好。下图 9 总结了 MS-COCO 零样本 FID 分数:更多内容,请参考原论文。参考链接:https://blog.google/technology/research/how-ai-creates-photorealistic-images-from-text/© THE END 转载请联系原公众号获得授权点个在看 paper不断! 浏览 42点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 谷歌开始卷自己,AI架构Pathways加持,推出200亿生成模型数据派THU0一张草图直接生成视频游戏,谷歌推出生成交互大模型人工智能和大数据0谷歌称之为“下一代 AI框架”, Pathways真有那么强吗?大数据文摘0「深呼吸」让大模型表现更佳!谷歌DeepMind利用大语言模型生成Prompt,还是AI更懂AI新智元0智谱AI推出第三代基座大模型人工智能与算法学习0谷歌AI发布稀疏模型高效设计指南!机器学习算法工程师0AI生成视频(上)- AI生成图片2024.03.23 晚上9点,我邀请AI产品专家免费给大家分享:AI生成视频(上)- AI生成图片(Stable Diffusion 模型 生成 图片 原理介绍),为了不错过直播,可长按识别下方二维码预约。Mistral AI推出基于Mamba2的Code开源模型,代码方面优于TF架构“欧洲OpenAI”和“Transformer挑战者”强强联合了!Mistral AI刚刚推出了其第一个基于Mamba2架构的开源模型——Codestral Mamba(7B),专搞代码生成。与Transformer架构不同,Mamba架构可进行“线性时间推理”,理论上能够支持无限长度输入。Mist英伟达推出”生成式AI专业认证“,帮你成为大模型开发专家!人工智能和大数据0深入Netty逻辑架构,从Reactor线程模型开始阿丸笔记0点赞 评论 收藏 分享 手机扫一扫分享分享 举报








 下载APP
下载APP