谷歌开源能翻译101种语言的AI模型,只比Facebook多一种
共 2114字,需浏览 5分钟
·
2020-11-07 03:31

大数据文摘出品
来源:VB
10月底,Facebook发布了一款可翻译100种语言的机器学习模型,微软发布了一款能翻译94种语言的模型,谷歌自然也不甘示弱。
继Facebook和微软后,谷歌开源了一种名为MT5的模型,称该模型在一系列英语自然语言处理任务上取得了最先进的效果。
MT5是谷歌的T5模型的多语言变体,已在包含101种语言的数据集中进行了预训练,就比Facebook多了一种。
Github地址:
MT5包含3亿到130亿个参数,可直接适用于多种语言环境
MT5包含3亿到130亿个参数,可直接适用于多种语言环境
MT5包含3亿到130亿个参数,据悉,它能够学习100多种语言而不会受到干扰。
MT5是在MC4上训练的,MC4是C4的一个子集,MC4包含大约750GB的英文文本,这些文本来自Common Crawl存储库(Common Crawl 包含从互联网上抓取的数十亿个网页)。虽然C4数据集被明确地设计为只使用英语,但MC4覆盖了107种语言,包含10,000个或更多的网页。
不过,数据集仍存在一定的偏差,谷歌研究人员试图通过删除MC4文档中的重复行和过滤含有错误单词的页面来减轻MT5的偏差。他们还使用工具检测了每个页面的主要语言,并删除了可信度低于70%的页面。
谷歌表示,最大的MT5型号有130亿个参数,超过了2020年10月测试的所有基准。当然,基准是否充分反映了模型的真实表现,这是一个值得争论的话题。
一些研究表明,开放域问答模型(Open-Domain Question-Answering,理论上能够用新颖答案回答新颖问题的模型)通常只是根据数据集简单地记住在训练数据中找到的答案。但是谷歌的研究人员断言MT5是迈向功能强大的模型的一步,这些功能不需要具有挑战性的建模技术。
谷歌的研究人员在一篇描述MT5的论文中写道,“总的来说,我们的研究结果突出了模型能力在跨语言表征学习中的重要性,并表明,通过依赖于过滤、并行数据或中间任务,扩大简单的预训练配方是一个可行的替代方案。”“我们演示了T5配方直接适用于多语言设置,并在不同的基准测试集上实现了强大的性能。”
相比Facebook和微软,谷歌的MT5似乎略胜一筹
相比Facebook和微软,谷歌的MT5似乎略胜一筹
Facebook的新模型被称作M2M-100,Facebook宣称它是第一个多语言机器翻译模型,可以直接在100种语言中的任何一对之间来回翻译。Facebook AI构建了一个共计由100种语言的75亿个句子组成的庞大数据集。使用这个数据集,研究团队训练了一个拥有超过150亿个参数的通用翻译模型,据Facebook的一篇博客描述,该模型可以“获取相关语言的信息,并反映出更多样化的语言文本和语言形态”。
而微软推出的这款机器学习翻译模型叫做T-ULRv2,可以翻译94种语言。微软声称,T-ULRv2在XTREME(谷歌创建的一种自然语言处理基准测试)中获得了最好的搜索结果,并将使用它来改进Word中的语义搜索、Outlook和team中的回复建议等功能。
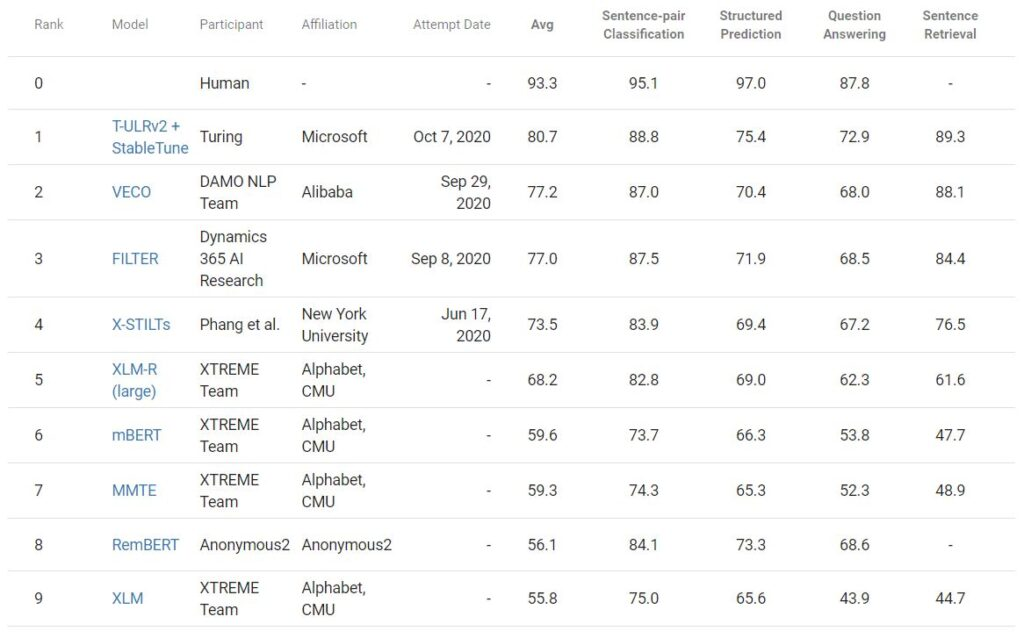
T-ULRv2在XTREME中处在榜首
T-ULRv2是微软研究院和图灵团队的联合研究出品的,包含5.5亿个参数,模型利用这些参数进行预测。微软研究人员在一个多语言数据语料库上训练了T-ULRv2,该数据语料库来自由94种语言组成的网页。在训练过程中,T-ULRv2通过预测不同语言句子中隐藏的单词来进行翻译,偶尔也会从英语和法语等成对翻译中获得上下文线索。
总之,从翻译的语言数量来说,谷歌的MT5似乎略胜一筹,但数量多并不意味着准确性高,就谷歌和Facebook的两款翻译模型来说,在某些低资源语种的翻译上仍有提升空间,比如沃洛夫语、马拉地语。此外,每款机器学习模型都会存在一定的偏差,正如艾伦AI研究所的科研人员所说,“现有的机器学习技术都没办法避免这一缺陷,人们急需更好的训练模式和模型建构”。
相关报道:
https://venturebeat.com/2020/10/26/google-open-sources-mt5-a-multilingual-model-trained-on-over-101-languages/
https://venturebeat.com/2020/10/20/microsoft-details-t-urlv2-model-that-can-translate-between-94-languages/
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn