
某麦最新 analysis 算法逆向分析(多种语言实现)
共 15196字,需浏览 31分钟
·
2022-10-24 11:42
“
阅读本文大概需要 13 分钟。
特别声明:本公众号文章只作为学术研究,不作为其它不法用途;如有侵权请联系作者删除。
趣味模块
小明是一名工程师,最近小明遇到了一个棘手的问题:小明发现自己曾经熬了几个通宵搞定的某麦算法居然升级了。小明惆怅进行中....,按照之前的套路进行加密定位和还原,发现都不好使了。这篇文章中,将解决小明遇到的困境,让我们一起去看小明遇到的问题并通过多种语言去实现算法还原吧!
一、前言介绍
前言: 想必 大家都了解什么是JS逆向吧?我们在以往的文章中涉及到JS逆向的网站,采用的方式都是去还原JS代码,然后使用Python去调用JS源码传递参数返回结果。这个过程虽然没有问题,但是对于爬取效率的提升、代码的性能都会受到影响。虽然爬虫的职责是首先确保能不能拿到数据,但是我觉得还有一个问题,那就是爬取效率。如果这两者都具备了,那将是最完美的!对于一些加密逻辑不是太复杂的网站,我们完全可以进行源码跨语言还原。耐心看完本文,你会受益匪浅的!
二、参数分析
备注
:如果想看旧版文章的,可以点击此链接:某麦analysis参数算法分析
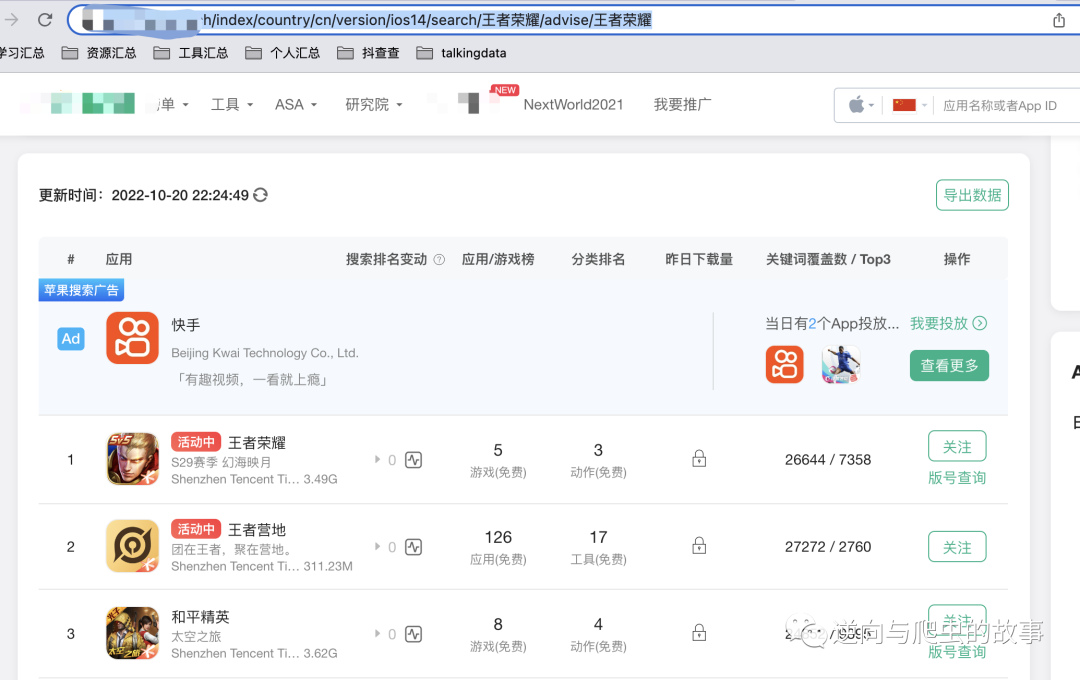
1、首先打开我们今天要模拟的网站,刷新当前页面,首页截图如下:
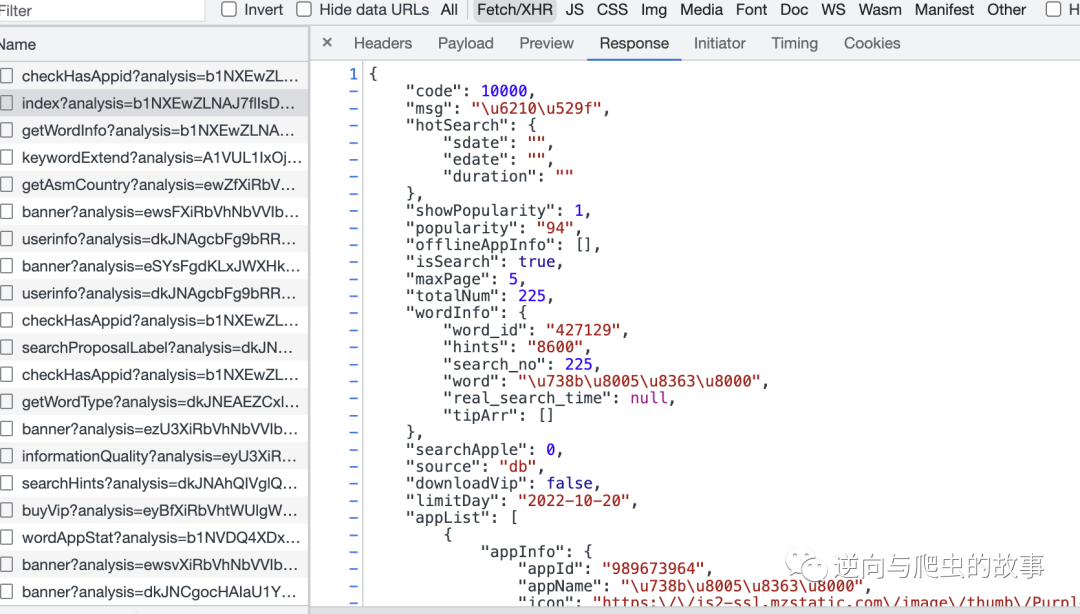
2、然后打开开发者工具,查找指定的XHR请求数据包,截图如下所示:
3、接下来,我们对该接口参数进行初判断及整理分析:
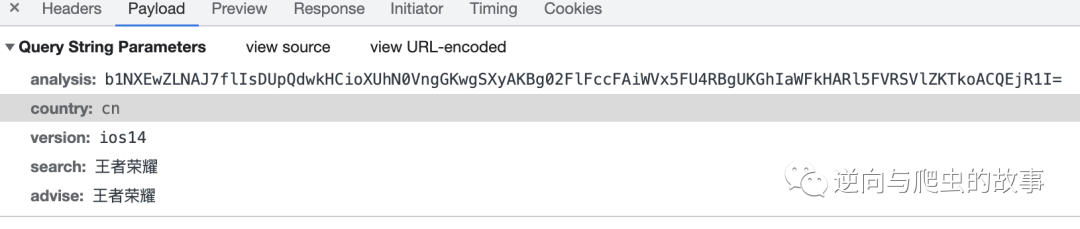
params参数分析:
-
analysis 初步怀疑是base64加密
-
country 固定值
-
version 搜索版本
-
search、advise 搜索关键字
headers参数分析:
说明: 由于headers参数没有重要参数影响,故不作说明。
三、断点调试
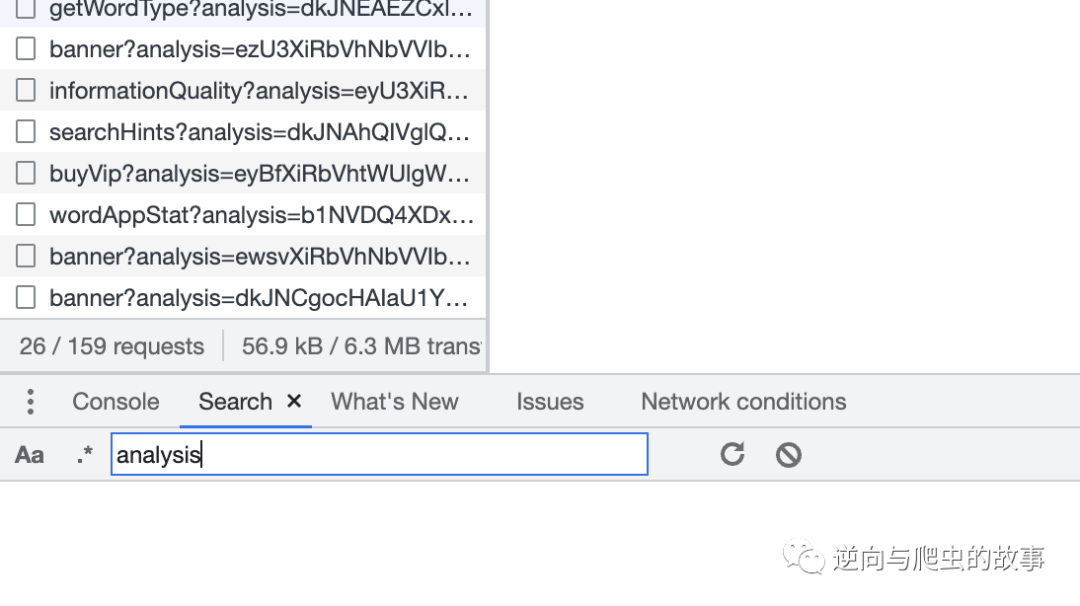
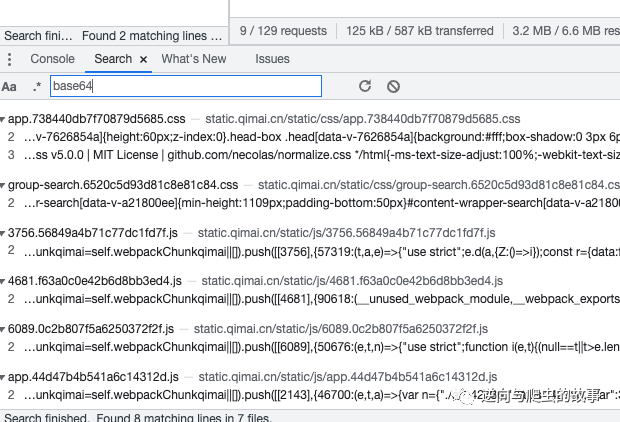
1、使用最简单的方式,查询指定关键字、加密方法,定位加密参数具体坐标文件,截图如下:
说明:
经过查询,我们可以肯定的是代码中没有用到这个变量名,然后我们去搜索加密方法,发现能搜到结果,但是和我们的加密参数关联不大,截图如下:
3、接下来,我们还是使用XHR打断点,回溯堆栈的方式查找吧,截图如下:
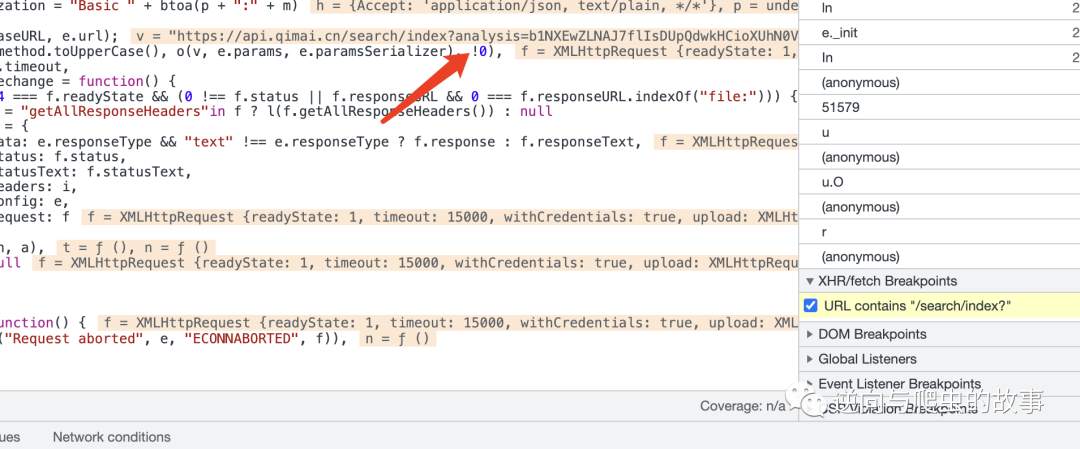
说明:查看断点发包的请求函数,我们发现标红的地方已经计算出了加密参数,显然我们的断点是置后的,不过没有关系,我们查看函数执行堆栈进行回溯查找。
4、由于需要堆栈调试,过滤掉一些没用的流程,我们直接定位到加密地方,截图如下:

总结:此时上图中参数e即为我们想要还原的加密参数,整个流程贯通后,我们只需要对js算法进行还原即可。
四、算法还原
1、JS版本算法还原
var n = {};
function i(e) {
var t, a = (t = "",
["66", "52", "6d", "6d", "43", "68", "61", "72", "43", "6f", "64", "65"].forEach((function (e) {
t += unescape("%u00" + e)
}
)),
t);
return String[a](e)
}
function h(e) {
return function (e) {
try {
return btoa(e)
} catch (t) {
return Buffer.from(e).toString("base64")
}
}(encodeURIComponent(e).replace(/%([0-9A-F]{2})/g, (function (e, t) {
return i("0x" + t)
}
)))
}
function g(e, t) {
t || (t = s());
for (var a = (e = e.split("")).length, n = t.length, o = "charCodeAt", r = 0; r < a; r++)
e[r] = i(e[r][o](0) ^ t[(r + 10) % n][o](0));
return e.join("")
}
n.cv = h;
n.oZ = g;
function get_enCdata(keyword, path) {
var l = "xyz517cda96abcd";
var d = "@#";
var s = 687;
var o = +new Date - (s || 0) - 1661224081041;
var r = ["cn", "ios14", keyword, keyword];
r = r.sort().join("");
r = n.cv(r);
r += d + path + d + o + d + 3;
a = (0,
n.cv)((0,
n.oZ)(r, l));
console.log(a);
return a
}
get_enCdata("王者荣耀", "/search/index")
console打印结果如下:

Python执行JS代码编写如下:
def js_load():
with open('encrypt.js', 'r', encoding='UTF-8') as f:
lines = f.read()
ctx = execjs.compile(lines)
return ctx
headers = {
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
'accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-site': 'same-site',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'accept-language': 'zh-CN,zh;q=0.9',
}
ctx = js_load()
keyword = "王者荣耀"
url = "https://xxxxxx/search/index"
analysis = ctx.call("get_enCdata", keyword, urlparse(url).path)
params = (
('country', 'cn'),
('search', keyword),
('advise', keyword),
('version', 'ios14'),
)
params = dict(params)
params.update({
"analysis":analysis,
})
response = requests.get(url, headers=headers, params=params)
print(response.text)
打印结果如下:
2、Python版本算法还原完整代码:
import time
import requests
import base64
from urllib.parse import urlparse
def get_analysis(params, path):
salt = "xyz517cda96abcd"
data = list(dict(params).values())
data.sort()
first_ba64 = base64.b64encode("".join(data).encode()).decode()
first_ba64 += f"@#{path}@#{int(time.time()) * 1000 - 687 - 1661224081041}@#3"
base_chr = ''.join(chr(ord(v) ^ ord(salt[(r + 10) % len(salt)])) for r, v in enumerate(first_ba64))
analysis = base64.b64encode(base_chr.encode()).decode()
return analysis
def start_requests(keyword):
headers = {
'authority': 'api.qimai.cn',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
'accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-site': 'same-site',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'accept-language': 'zh-CN,zh;q=0.9',
}
url = "https://xxxxx/search/index"
params = (
('country', 'cn'),
('search', keyword),
('advise', keyword),
('version', 'ios14'),
)
analysis = get_analysis(params, urlparse(url).path)
params = dict(params)
params.update({
"analysis": analysis,
})
response = requests.get(url, headers=headers, params=params)
print(response.text)
if __name__ == '__main__':
start_requests("王者荣耀")
Pycharm打印结果如下:
3、GoLang版本算法还原完整代码:
// Package main ------------------
// @author : 逆向与爬虫故事公众号
// -------------------------------
package main
import (
"encoding/base64"
"fmt"
"io/ioutil"
"log"
"net/http"
"time"
)
func getAnalysis(keyword, path string) string {
salt := "xyz517cda96abcd"
baseStr := fmt.Sprintf("cnios14%s%s", keyword, keyword)
baseBase64 := base64.StdEncoding.EncodeToString([]byte(baseStr))
baseBase64 += fmt.Sprintf("@#%s@#%d@#3", path, time.Now().Unix()*1000-687-1661224081041)
dataStr := ""
for i := 0; i < len(baseBase64); i++ {
dataStr += string(baseBase64[i] ^ salt[(i+10)%len(salt)])
}
analysis := base64.StdEncoding.EncodeToString([]byte(dataStr))
return analysis
}
func main() {
client := &http.Client{}
keyword := "王者荣耀"
path := "/search/index"
analysis := getAnalysis(keyword, path)
fmt.Println(analysis)
req, err := http.NewRequest("GET", "https://xxxx/search/index?analysis="+analysis+"&country=cn&version=ios14&search="+keyword+"&advise="+keyword+"", nil)
if err != nil {
log.Fatal(err)
}
req.Header.Set("accept", "application/json, text/plain, */*")
req.Header.Set("accept-language", "zh-CN,zh;q=0.9")
req.Header.Set("cache-control", "no-cache")
req.Header.Set("cookie", "gr_user_id=6326ec0c-e4bb-40f4-80fa-f136f53ec138; qm_check=A1sdRUIQChtxen8tJ0NMOQkKWVIeEHhARFQEQi5VVFk1RVJcd3UQABZQS0FIWhoSUFRZEgMSBBRRTlNISFVKF0o%3D; Hm_lvt_ff3eefaf44c797b33945945d0de0e370=1665841750,1665843752,1665999455,1666149354; tgw_l7_route=d09474674af82c17375cfcdd775c0c28; PHPSESSID=c8sbl02kml6qbdktrgkf2l7iia; ada35577182650f1_gr_session_id=25228f5f-bbba-4660-86f5-d45ebd688bb6; ada35577182650f1_gr_session_id_25228f5f-bbba-4660-86f5-d45ebd688bb6=true; synct=1666149373.597; Hm_lpvt_ff3eefaf44c797b33945945d0de0e370=1666149374; syncd=-1222")
req.Header.Set("pragma", "no-cache")
req.Header.Set("sec-ch-ua", `"Chromium";v="106", "Google Chrome";v="106", "Not;A=Brand";v="99"`)
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("sec-ch-ua-platform", `"macOS"`)
req.Header.Set("sec-fetch-dest", "empty")
//req.Header.Set("sec-fetch-mode", "cors")
req.Header.Set("sec-fetch-site", "same-site")
req.Header.Set("user-agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", bodyText)
}
GoLand打印结果如下:
五、思路总结
回顾整个分析流程,本次难点主要概括为以下几点:
- 如何快速定位加密参数的位置
-
堆栈回溯如何过滤无用代码
-
如何扣JS代码并能run起来
- Python还原加密算法实现
- GoLang还原加密算法实现
-
熟练掌握数据类型及逻辑运算

End
崔庆才的新书《Python3网络爬虫开发实战(第二版)》已经正式上市了!书中详细介绍了零基础用 Python 开发爬虫的各方面知识,同时相比第一版新增了 JavaScript 逆向、Android 逆向、异步爬虫、深度学习、Kubernetes 相关内容,同时本书已经获得 Python 之父 Guido 的推荐,目前本书正在七折促销中!
内容介绍:《Python3网络爬虫开发实战(第二版)》内容介绍

扫码购买
点个在看你最好看
