
一文搞懂 SAE 日志采集架构
日志,对于一个程序的重要程度不言而喻。无论是作为排查问题的手段,记录关键节点信息,或者是预警,配置监控大盘等等,都扮演着至关重要的角色。是每一类,甚至每一个应用程序都需要记录和查看的重要内容。
而在云原生时代,日志采集无论是在采集方案,还是在采集架构上,都会和传统的日志采集有一些差异。我们汇总了一下在日志的采集过程中,经常会遇到一些实际的通用问题,例如:
部署在 K8s 的应用,磁盘大小会远远低于物理机,无法把所有日志长期存储,又有查询历史数据的诉求
日志数据非常关键,不允许丢失,即使是在应用重启实例重建后
希望对日志做一些关键字等信息的报警,以及监控大盘
权限管控非常严格,不能使用或者查询例如 SLS 等日志系统,需要导入到自己的日志采集系统
JAVA,PHP 等应用的异常堆栈会产生换行,把堆栈异常打印成多行,如何汇总查看呢?
那么在实际生产环境中,用户是如何使用日志功能采集的呢?面对不同的业务场景,不同的业务诉求时,采用哪种采集方案更佳呢?
Serverless 应用引擎 SAE(Serverless App Engine)作为一个全托管、免运维、高弹性的通用 PaaS 平台,提供了 SLS 采集、挂载 NAS 采集、Kafka 采集等多种采集方式,供用户在不同的场景下使用。本文将着重介绍各种日志采集方式的特点,最佳使用场景,帮助大家来设计合适的采集架构,并规避一些常见的问题。
SAE 的日志采集方式
SLS 采集架构
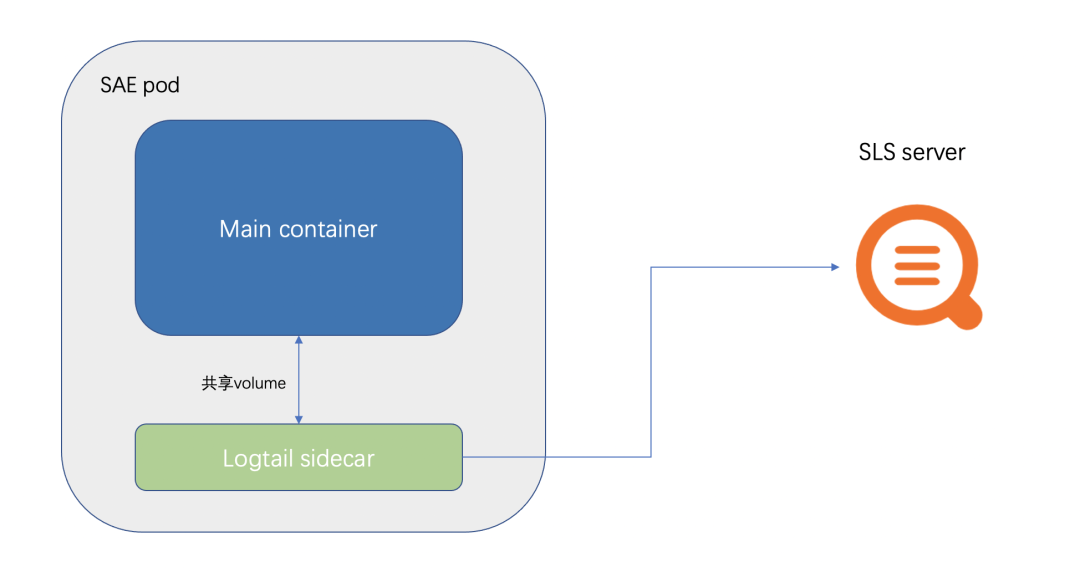
SAE 会在 pod 中,挂载一个 logtail (SLS 的采集器)的 Sidecar。
然后将客户配置的,需要采集的文件或者路径,用 volume 的形式,给业务 Container 和 logtail Sidecar 共享。这也是 SAE 日志采集不能配置/home/admin 的原因。因为服务的启动容器是放在/home/admin 中,挂载 volume 会覆盖掉启动容器。
同时 logtail 的数据上报,是通过 SLS 内网地址去上报,因此无需开通外网。
SLS 的 Sidecar 采集,为了不影响业务 Container 的运行,会设置资源的限制,例如 CPU 限制在 0.25C ,内存限制在 100M。
SLS 适合大部分的业务场景,并且支持配置告警和监控图。绝大多数适合直接选择 SLS 就可以了。
NAS 采集架构
Kafka 采集架构
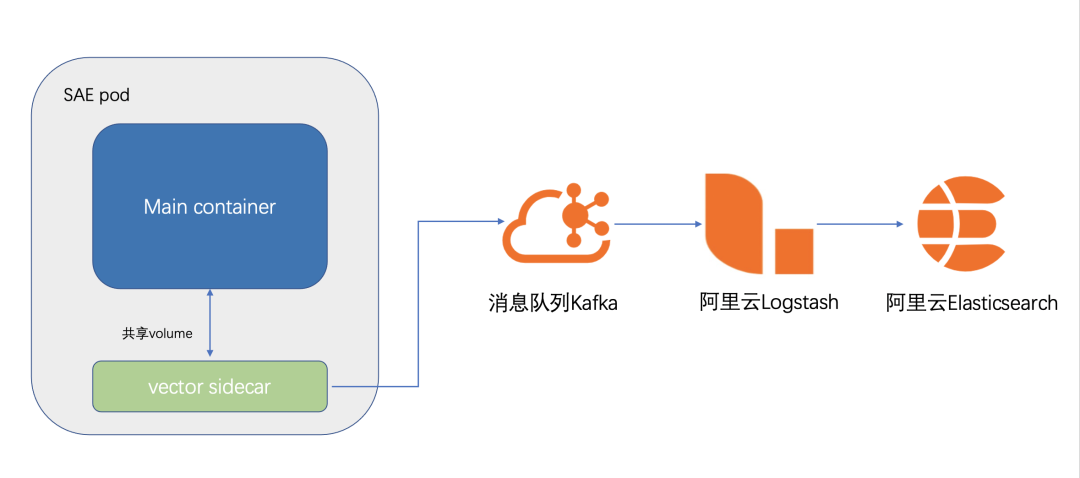
SAE 会在 pod 中,挂载一个 logtail(vector 采集器)的 Sidecar。
然后将客户配置的,需要采集的文件或者路径,用 volume 的形式,给业务 Container 和 vector Sidecar 共享
vector 会将采集到的日志数据定时发送到 Kafka。vector 本身有比较丰富的参数设置,可以设置采集数据压缩,数据发送间隔,采集指标等等。
Kafka 采集算是对 SLS 采集的一种补充完善。实际生产环境下,有些客户对权限的控制非常严格,可能只有 SAE 的权限,却没有 SLS 的权限,因此需要把日志采集到 Kafka 做后续的查看,或者本身有需求对日志做二次处理加工等场景,也可以选择 Kafka 日志采集方案。
下面是一份基础的 vector.toml 配置:
data_dir = "/etc/vector"[sinks.sae_logs_to_kafka]type = "kafka"bootstrap_servers = "kafka_endpoint"encoding.codec = "json"encoding.except_fields = ["source_type","timestamp"]inputs = ["add_tags_0"]topic = "{{ topic }}"[sources.sae_logs_0]type = "file"read_from = "end"max_line_bytes = 1048576max_read_bytes = 1048576multiline.start_pattern = '^[^\s]'multiline.mode = "continue_through"multiline.condition_pattern = '(?m)^[\s|\W].*$|(?m)^(Caused|java|org|com|net).+$|(?m)^\}.*$'multiline.timeout_ms = 1000include = ["/sae-stdlog/kafka-select/0.log"][transforms.add_tags_0]type = "remap"inputs = ["sae_logs_0"]source = '.topic = "test1"'[sources.internal_metrics]scrape_interval_secs = 15type = "internal_metrics_ext"[sources.internal_metrics.tags]host_key = "host"pid_key = "pid"[transforms.internal_metrics_filter]type = "filter"inputs = [ "internal_metrics"]condition = '.tags.component_type == "file" || .tags.component_type == "kafka" || starts_with!(.name, "vector")'[sinks.internal_metrics_to_prom]type = "prometheus_remote_write"inputs = [ "internal_metrics_filter"]endpoint = "prometheus_endpoint"
重要的参数解析:
multiline.start_pattern 是当检测到符合这个正则的行时,会当作一条新的数据处
multiline.condition_pattern 是检测到符合这个正则的行时,会和上一行做行合并,当作一条处理
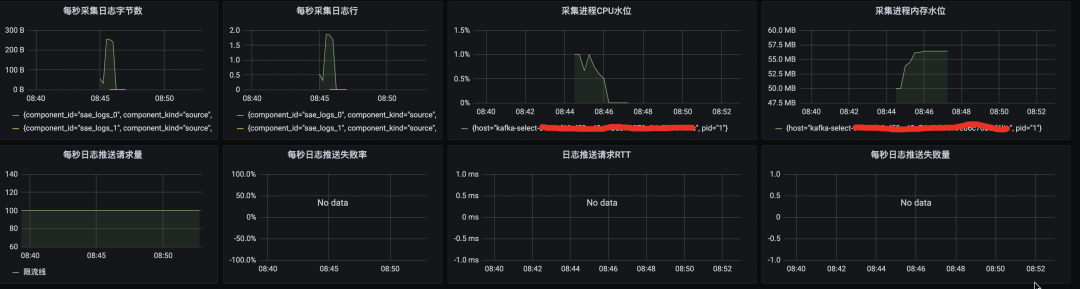
sinks.internal_metrics_to_prom 配置了之后,会将配置一些 vector 的采集元数据上报到 prometheus
下面是配置了 vector 采集的元数据到 Prometheus,在 Grafana 的监控大盘处配置了 vector 的元数据的一些采集监控图:
最佳实践
在实际使用中,可以根据自身的业务诉求选择不同的日志采集方式。本身 logback 的日志采集策略,需要对文件大小和文件数量做一下限制,不然比较容易把 pod 的磁盘打满。以 JAVA 为例,下面这段配置,会保留最大 7 个文件,每个文件大小最大 100M。
<appender name="TEST"class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${user.home}/logs/test/test.log</file><rollingPolicy class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy"><fileNamePattern>${user.home}/logs/test/test.%i.log</fileNamePattern><minIndex>1</minIndex><maxIndex>7</maxIndex></rollingPolicy><triggeringPolicyclass="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy"><maxFileSize>100MB</maxFileSize></triggeringPolicy><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><charset>UTF-8</charset><pattern>%d{yyyy-MM-dd HH:mm:ss}|%msg%n</pattern></encoder></appender>
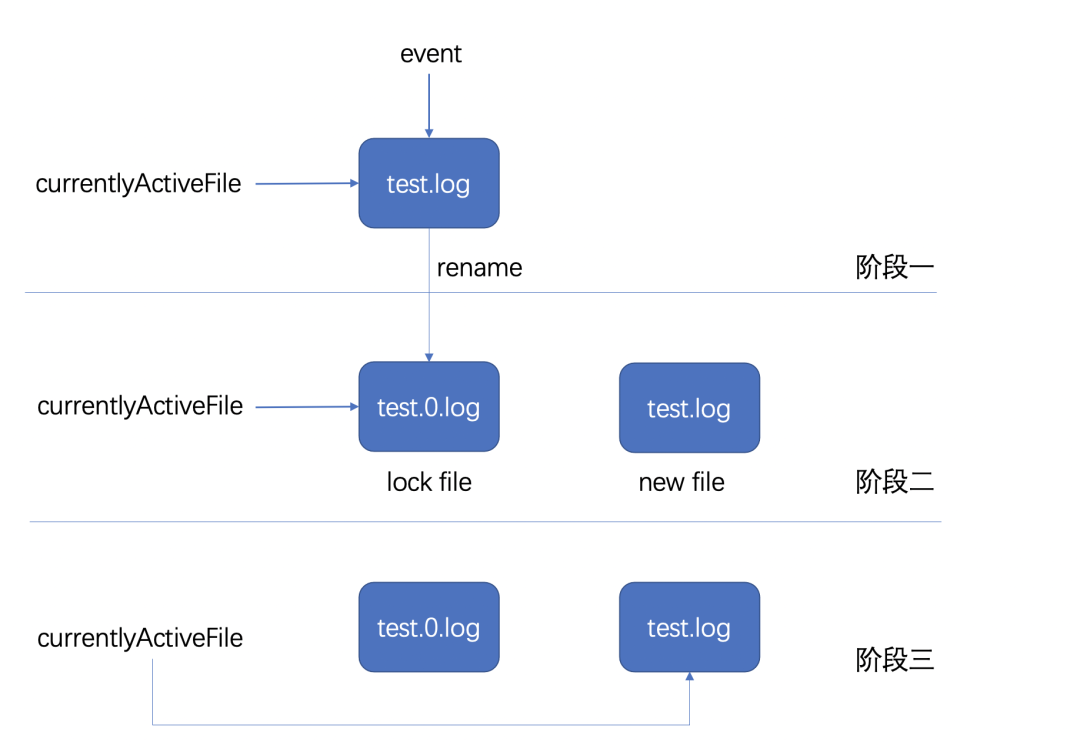
当日志的 event log 写入前会判断是否达到文件设置最大容量,如果没达到,则完成写入,如果达到了,则会进入阶段二;
首先关闭当前 currentlyActiveFile 指向的文件,之后对原文件进行重命名,并新建一个文件,这个文件的名字和之前 currentlyActiveFile 指向的名字一致;
把 currentlyActiveFile 指向的文件变为阶段二新创建的文件。
copytruncate 模式的思路是把正在输出的日志拷(copy)一份出来,再清空(trucate)原来的日志。
目前主流组件的支持程度如下:

实际案例演示

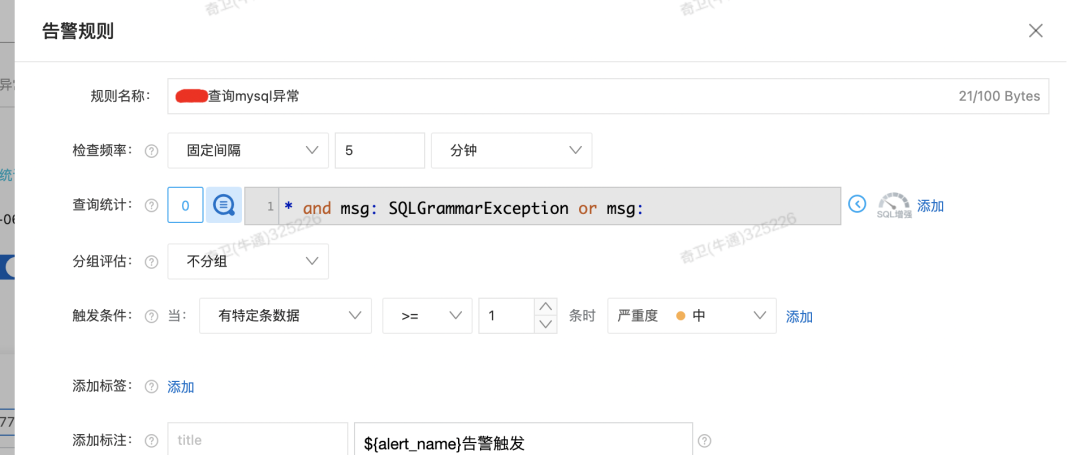
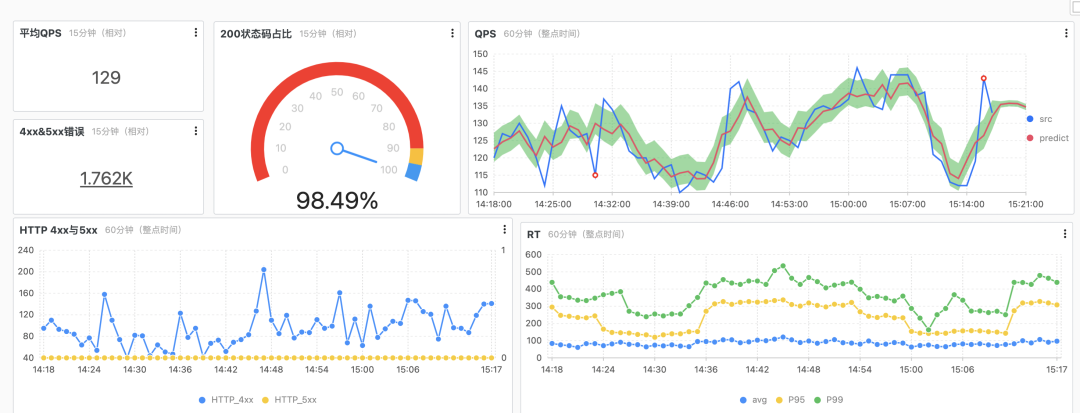
常见问题
日志合并介绍
日志采集丢失分析
总结
SLS 采集适配性强,实用大多数场景 NAS 采集任何场景下都不会丢失,适合对日志要求非常严格的场景 Kafka 采集是对 SLS 采集的一种补充,有对日志需要二次加工处理,或者因为权限等原因无法使用 SLS 的场景,可以选择将日志采集到 Kafka 自己做搜集处理。
阿里云重磅推出 SAE Job,支持 XXL-JOB、ElasticJob 任务的全托管,零改造迁移。目前火热公测中,2022 年 9 月 1 日正式商业化收费,欢迎大家使用!
SAE Job 作为面向任务的 Serverless PaaS 平台,重点解决用户的效率和成本问题。根据业务数据处理需求,能在短时间内快速创建大量计算任务,并且在任务完成后快速释放计算资源。支持单机、广播、并行计算、分片任务模型,定时、超时重试、阻塞策略等任务核心特性,比开源任务框架使用更方便(对代码无侵入)、更节省(任务运行完立即释放资源)、更稳定(失败自动重试)、更透明(可视化监控报警)、更省心(免运维)。
 更多产品内容,点击阅读原文查看~
更多产品内容,点击阅读原文查看~