
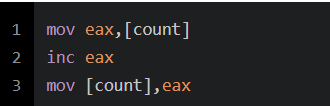
对int变量赋值的操作是原子的吗?为什么?

前言

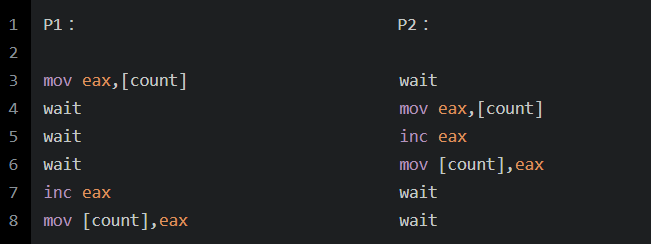

X86架构

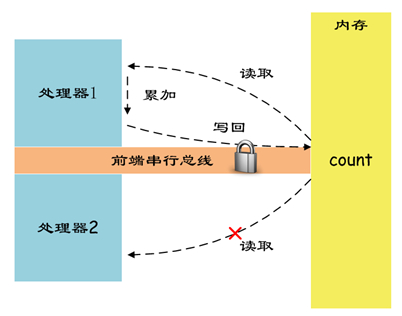
Description Causes the processor’s LOCK# signal to be asserted during execution of the accompanying instruction (turns the instruction into an atomic instruction). In a multiprocessor environment, the LOCK# signal ensures that the processor has exclusive use of any shared memory while the signal is asserted. The LOCK prefix can be prepended only to the following instructions and only to those forms of the instructions where the destination operand is a memory operand: ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG. If the LOCK prefix is used with one of these instructions and the source operand is a memory operand, an undefined opcode exception (#UD) may be generated. An undefined opcode exception will also be generated if the LOCK prefix is used with any instruction not in the above list. The XCHG instruction always asserts the LOCK# signal regardless of the presence or absence of the LOCK prefix. The LOCK prefix is typically used with the BTS instruction to perform a read-modify-write operation on a memory location in shared memory environment. The integrity of the LOCK prefix is not affected by the alignment of the memory field. Memory locking is observed for arbitrarily misaligned fields.
操作系统中的实现

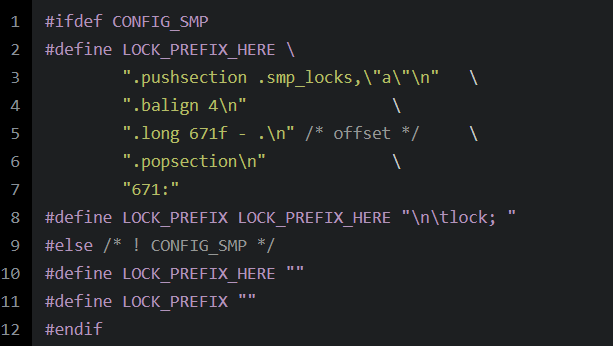
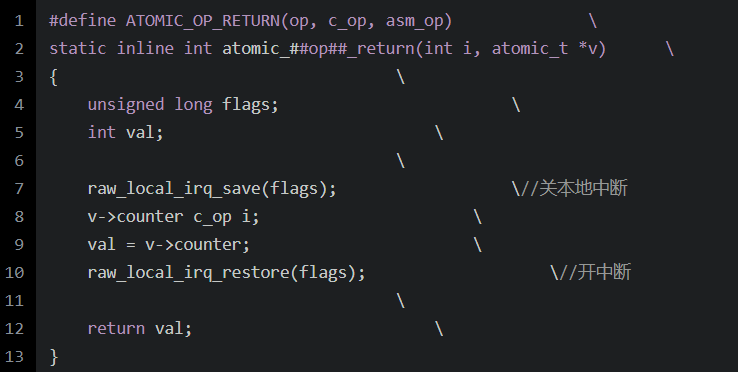
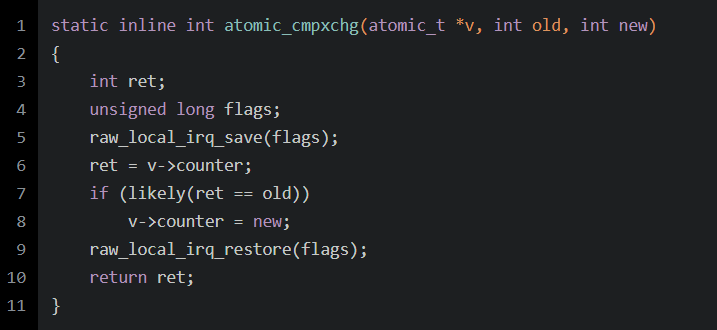
static __always_inline int atomic_cmpxchg(atomic_t *v, int old, int new){return cmpxchg(&v->counter, old, new);}__cmpxchg(ptr, old, new, sizeof(*(ptr)))__raw_cmpxchg((ptr), (old), (new), (size), LOCK_PREFIX)({ \__typeof__(*(ptr)) __ret; \__typeof__(*(ptr)) __old = (old); \__typeof__(*(ptr)) __new = (new); \switch (size) { \case __X86_CASE_B: \{ \volatile u8 *__ptr = (volatile u8 *)(ptr); \asm volatile(lock "cmpxchgb %2,%1" \: "=a" (__ret), "+m" (*__ptr) \: "q" (__new), "0" (__old) \: "memory"); \break; \} \case __X86_CASE_W: \{ \volatile u16 *__ptr = (volatile u16 *)(ptr); \asm volatile(lock "cmpxchgw %2,%1" \: "=a" (__ret), "+m" (*__ptr) \: "r" (__new), "0" (__old) \: "memory"); \break; \} \case __X86_CASE_L: \{ \volatile u32 *__ptr = (volatile u32 *)(ptr); \asm volatile(lock "cmpxchgl %2,%1" \: "=a" (__ret), "+m" (*__ptr) \: "r" (__new), "0" (__old) \: "memory"); \break; \} \case __X86_CASE_Q: \{ \volatile u64 *__ptr = (volatile u64 *)(ptr); \asm volatile(lock "cmpxchgq %2,%1" \: "=a" (__ret), "+m" (*__ptr) \: "r" (__new), "0" (__old) \: "memory"); \break; \} \default: \__cmpxchg_wrong_size(); \} \__ret; \})
ARM架构

链接:https://www.windsings.com/posts/2a85d31f/
(版权归原作者所有,侵删)
评论