
利用Python做一个小姐姐词云跳舞视频
作者:北山啦
https://blog.csdn.net/qq_45176548/article/details/113410073
本文将以哔哩哔哩–乘风破浪视频为例,you-get下载视频,同时利用python爬取B站视频弹幕,并利用opencv对视频进行分割,百度AI进行人像分割,moviepy生成词云跳舞视频,并添加音频。
1. 导入模块
1.1 下载所需模块
import osimport timelibs = {"lxml","requests","pandas","numpy","you-get","opencv-python","pandas","fake_useragent","matplotlib","moviepy"}try:for lib in libs:os.system(f"pip3 install -i https://pypi.doubanio.com/simple/ {lib}")print(lib+"下载成功")except:print("下载失败")
1.2 导入模块
import osimport reimport cv2import jiebaimport requestsimport moviepyimport pandas as pdimport numpy as npfrom PIL import Imagefrom lxml import etreefrom wordcloud import WordCloudimport matplotlib.pyplot as pltfrom fake_useragent import UserAgent
2. 视频处理
2.1 下载视频

2.2 视频分割
2.2.1代码展示
# -*- coding:utf-8 -*-# @Author : 北山啦# @Time : 2021/1/29 14:08# @File : 视频分割.py# @Software : PyCharmimport cv2cap = cv2.VideoCapture(r"无价之姐~让我乘风破浪~~~.flv")while 1:# 逐帧读取视频 按顺序保存到本地文件夹ret,frame = cap.read()if ret:cv2.imwrite(f".\pictures\img_{num}.jpg",frame)else:breakcap.release() # 释放资源
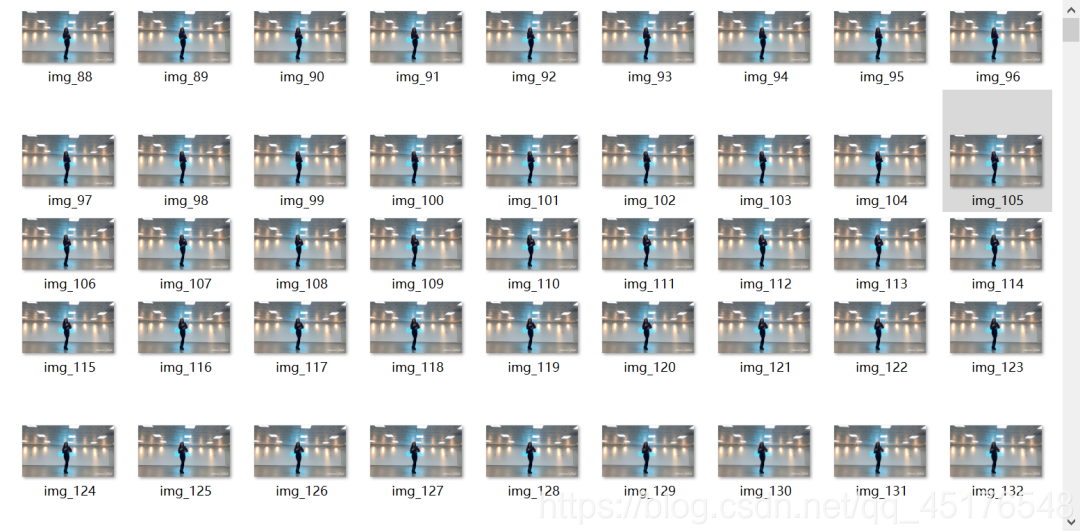
2.2.2 结果展示
2.3 人像分割
2.3.1创建应用
2.3.2 Python SDK参考文档
2.3.3 代码展示
# -*- coding:utf-8 -*-# @Author : 北山啦# @Time : 2021/1/29 14:38# @File : 人像分割.py# @Software : PyCharm"""原文链接:"""import cv2import base64import numpy as npimport osfrom aip import AipBodyAnalysisimport timeimport randomAPP_ID = '******'API_KEY = '*******************'SECRET_KEY = '********************'client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY)# 保存图像分割后的路径path = './mask_img/'# os.listdir 列出保存到图片名称img_files = os.listdir('./pictures')print(img_files)for num in range(1, len(img_files) + 1):# 按顺序构造出图片路径img = f'./pictures/img_{num}.jpg'img1 = cv2.imread(img)height, width, _ = img1.shape# print(height, width)# 二进制方式读取图片with open(img, 'rb') as fp:img_info = fp.read()# 设置只返回前景 也就是分割出来的人像seg_res = client.bodySeg(img_info)labelmap = base64.b64decode(seg_res['labelmap'])nparr = np.frombuffer(labelmap, np.uint8)labelimg = cv2.imdecode(nparr, 1)labelimg = cv2.resize(labelimg, (width, height), interpolation=cv2.INTER_NEAREST)new_img = np.where(labelimg == 1, 255, labelimg)mask_name = path + 'mask_{}.png'.format(num)# 保存分割出来的人像cv2.imwrite(mask_name, new_img)print(f'======== 第{num}张图像分割完成 ========')
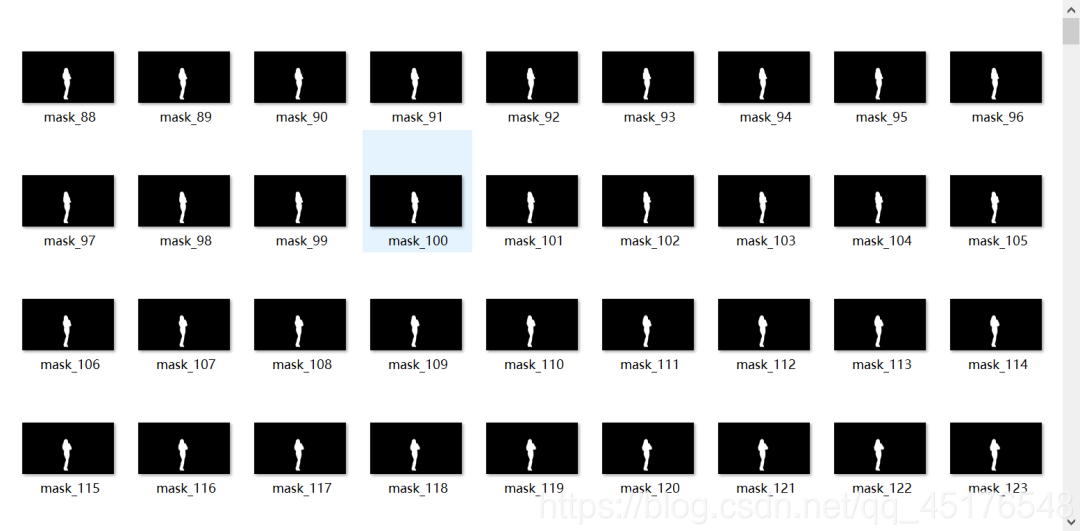
2.3.4 结果展示
3. 弹幕爬取
3.1 网页分析
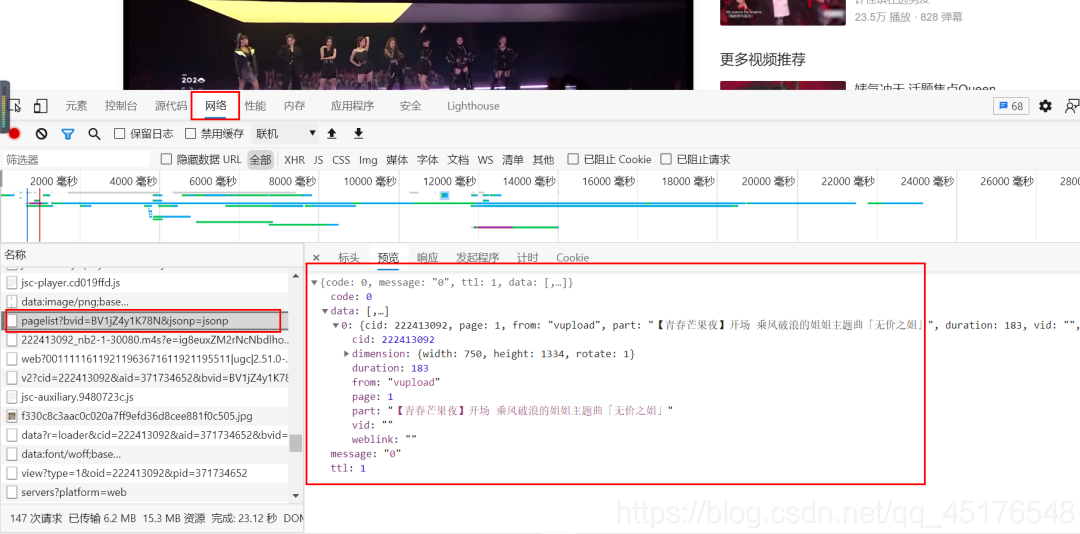
3.2 观察历史弹幕
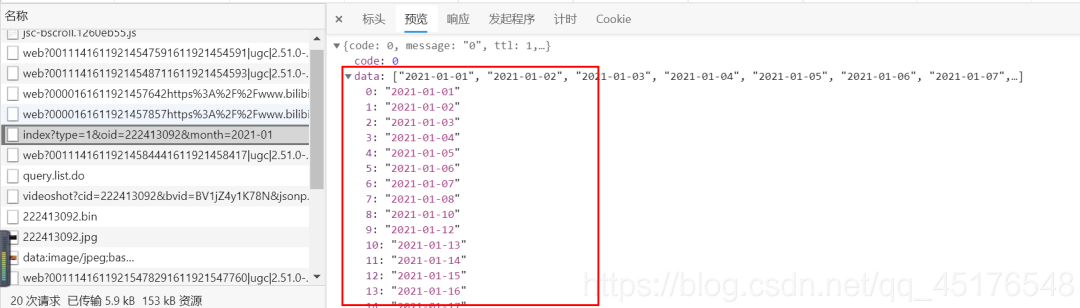
3.3爬取弹幕
3.3.1构造时间序列
import pandas as pda = pd.date_range("2020-08-08","2020-09-08")print(a)DatetimeIndex(['2020-08-08', '2020-08-09', '2020-08-10', '2020-08-11','2020-08-12', '2020-08-13', '2020-08-14', '2020-08-15','2020-08-50', '2020-08-17', '2020-08-18', '2020-08-19','2020-08-20', '2020-08-21', '2020-08-22', '2020-08-23','2020-08-24', '2020-08-25', '2020-08-26', '2020-08-27','2020-08-28', '2020-08-29', '2020-08-30', '2020-08-31','2020-09-01', '2020-09-02', '2020-09-03', '2020-09-04','2020-09-05', '2020-09-06', '2020-09-07', '2020-09-08'],dtype='datetime64[ns]', freq='D')
3.3.2 爬取数据
# -*- coding:utf-8 -*-# @Author : 北山啦# @Time : 2021/1/29 19:33# @File : 弹幕爬取.py# @Software : PyCharmimport requestsimport pandas as pdimport reimport csvfrom fake_useragent import UserAgentfrom concurrent.futures import ThreadPoolExecutorimport datetimeua = UserAgent()start_time = datetime.datetime.now()def Grab_barrage(date):headers = {"origin": "https://www.bilibili.com","referer": "https://www.bilibili.com/video/BV1jZ4y1K78N?from=search&seid=1084505810439035065","cookie": "","user-agent": ua.random(),}params = {'type': 1,'oid' : "222413092",'date': date}r= requests.get(url, params=params, headers=headers)r.encoding = 'utf-8'comment = re.findall('<d p=".*?">(.*?)</d>', r.text)for i in comments:df.append(i)a = pd.DataFrame(df)a.to_excel("danmu.xlsx")def main():with ThreadPoolExecutor(max_workers=4) as executor:executor.map(Grab_barrage, date_list)"""计算所需时间"""delta = (datetime.datetime.now() - start_time).total_seconds()print(f'用时:{delta}s')if __name__ == '__main__':# 目标urlurl = "https://api.bilibili.com/x/v2/dm/history"start,end = '20200808','20200908'date_list = [x for x in pd.date_range(start, end).strftime('%Y-%m-%d')]count = 0main()
3.3.3结果展示

4.生成词云图
4.1 评论内容机械压缩去重
def func(s):for i in range(1,int(len(s)/2)+1):for j in range(len(s)):if s[j:j+i] == s[j+i:j+2*i]:k = j + iwhile s[k:k+i] == s[k+i:k+2*i] and k<len(s):k = k + is = s[:j] + s[k:]return sdata["短评"] = data["短评"].apply(func)
4.2 添加停用词和自定义词组
import pandas as pdfrom wordcloud import WordCloudimport jiebafrom tkinter import _flattenimport matplotlib.pyplot as pltjieba.load_userdict("./词云图//add.txt")with open('./词云图//stoplist.txt', 'r', encoding='utf-8') as f:stopWords = f.read()
4.3生成词云图
# -*- coding:utf-8 -*-# @Author : 北山啦# @Time : 2021/1/29 19:10# @File : 跳舞词云图生成.py# @Software : PyCharmfrom wordcloud import WordCloudimport collectionsimport jiebaimport refrom PIL import Imageimport matplotlib.pyplot as pltimport numpy as npwith open('barrages.txt') as f:data = f.read()jieba.load_userdict("./词云图//add.txt")# 读取数据with open('barrages.txt') as f:data = f.read()jieba.load_userdict("./词云图//add.txt")# 文本预处理 去除一些无用的字符 只提取出中文出来new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)new_data = "/".join(new_data)# 文本分词seg_list_exact = jieba.cut(new_data, cut_all=True)result_list = []with open('./词云图/stoplist.txt', encoding='utf-8') as f:con = f.read().split('\n')stop_words = set()for i in con:stop_words.add(i)for word in seg_list_exact:# 设置停用词并去除单个词if word not in stop_words and len(word) > 1:result_list.append(word)# 筛选后统计词频word_counts = collections.Counter(result_list)path = './wordcloud/'img_files = os.listdir('./mask_img')print(img_files)for num in range(1, len(img_files) + 1):img = fr'.\mask_img\mask_{num}.png'# 获取蒙版图片mask_ = 255 - np.array(Image.open(img))# 绘制词云plt.figure(figsize=(8, 5), dpi=200)my_cloud = WordCloud(background_color='black', # 设置背景颜色 默认是blackmask=mask_, # 自定义蒙版mode='RGBA',max_words=500,font_path='simhei.ttf', # 设置字体 显示中文).generate_from_frequencies(word_counts)# 显示生成的词云图片plt.imshow(my_cloud)# 显示设置词云图中无坐标轴plt.axis('off')word_cloud_name = path + 'wordcloud_{}.png'.format(num)my_cloud.to_file(word_cloud_name) # 保存词云图片print(f'======== 第{num}张词云图生成 ========')
5. 合成视频
5.1图片合成
# -*- coding:utf-8 -*-# @Author : 北山啦# @Time : 2021/1/29 19:10# @File : 跳舞词云图生成.py# @Software : PyCharmimport cv2import os# 输出视频的保存路径video_dir = 'result.mp4'# 帧率fps = 30# 图片尺寸img_size = (1920, 1080)fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)img_files = os.listdir('.//wordcloud')for i in range(88, 888):img_path = './/wordcloud//wordcloud_{}.png'.format(i)frame = cv2.imread(img_path)frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同videoWriter.write(frame) # 写进视频里print(f'======== 按照视频顺序第{i}张图片合进视频 ========')videoWriter.release() # 释放资源

5.2 音频添加
# -*- coding:utf-8 -*-# @Author : 北山啦# @Time : 2021/1/29 19:10# @File : 跳舞词云图生成.py# @Software : PyCharmimport moviepy.editor as mpy# 读取词云视频my_clip = mpy.VideoFileClip('result.mp4')# 截取背景音乐audio_background = mpy.AudioFileClip('song.mp3').subclip(0,25)audio_background.write_audiofile('song1.mp3')# 视频中插入音频final_clip = my_clip.set_audio(audio_background)# 保存为最终的视频 动听的音乐!漂亮小姐姐词云跳舞视频!final_clip.write_videofile('final_video.mp4')
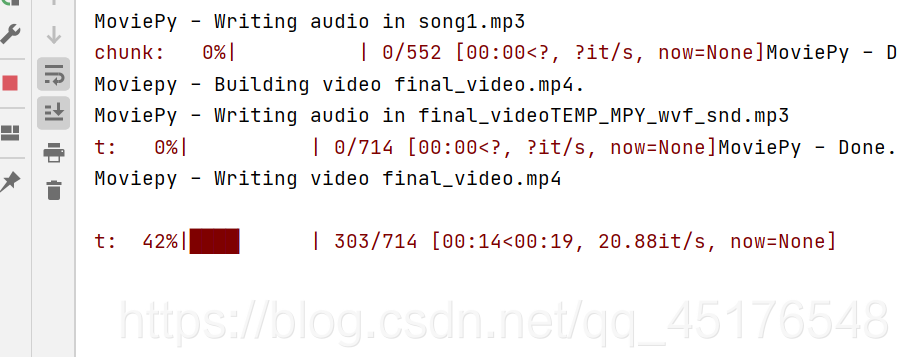
6. 结果展示
到这里就结束了,如果对你有帮助,欢迎点赞,你的点赞对我很重要。
微信扫码关注,了解更多内容
评论