Seaborn + Pandas带你玩转股市数据可视化分析
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源:数据STUDIO 作者:云朵君

大家好,我是老表。
导读: 前面探索性数据分析在介绍可视化探索特征变量时已经介绍了多个可视化图形绘制方法,本文继续介绍两大绘图技巧,分布使用seaborn与pandas包绘制可视化图形。旨在通过金融股市历史价格数据学习可视化绘图技巧。
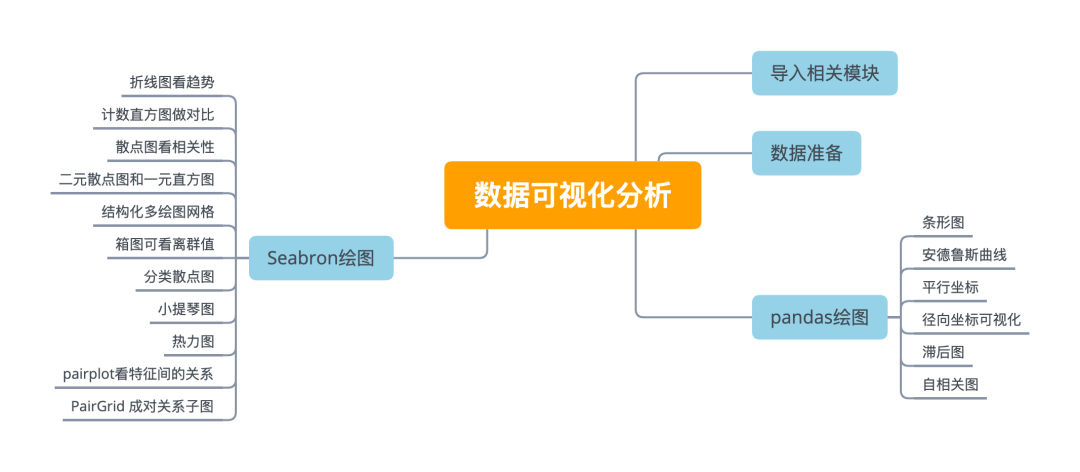
在日常生活中,可视化技术常常是优先选择的方法。尽管在大多数技术学科(包括数据挖掘)中通常强调算法或数学方法,但是可视化技术也能在数据分析方面起到关键性作用。
除了折线图和散点图,你还知道哪些一行代码就能绘制出的酷炫又实用的可视化图形呢?下面我们就来一起探索吧。
导入相关模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="white", color_codes=True)
数据准备
此处数据获取及特征构造可参见金融数据准备。
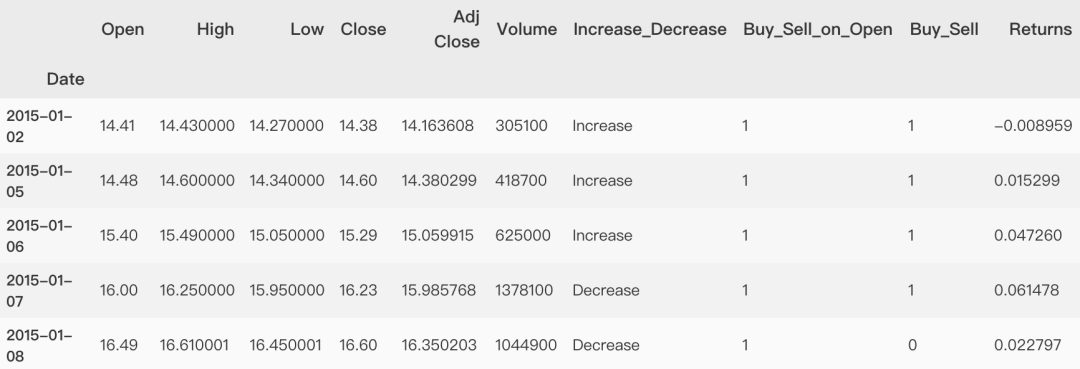
折线图看趋势
折线图在股市中地位是不可撼动的,折线图即股票走势图也就是K线图,是股民们分析股市历史数据即走势的重要图形,通常分为,日、周、月、季、年K线图。
单条折线
fig, ax = plt.subplots()
fig.set_size_inches(12, 8)
sns.lineplot(dataset.index ,
dataset['Adj Close'])
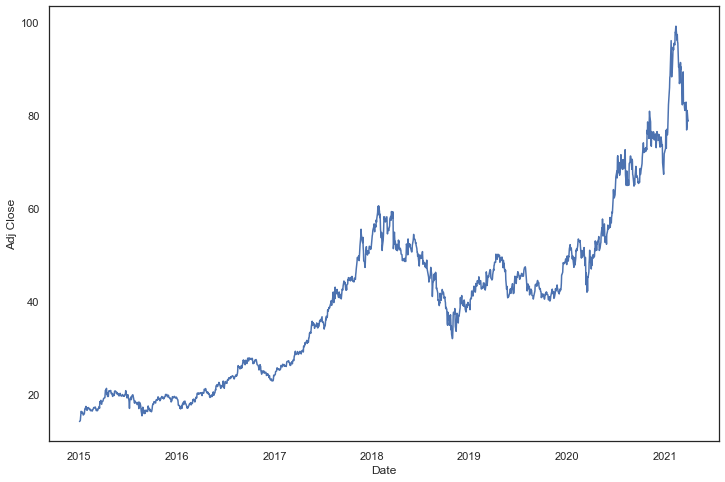
双折线
sns.lineplot(x=dataset.index,
y="Adj Close",
hue="Increase_Decrease", data=dataset)
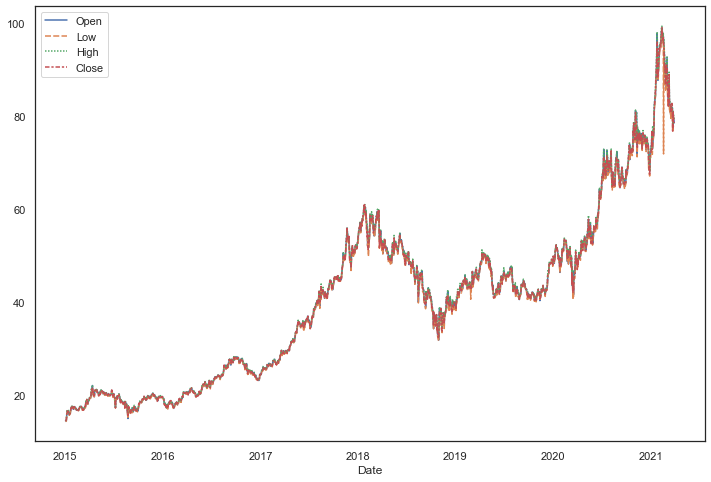
多条折线
# Plot Multi lines
sns.lineplot(data=dataset[
['Open', 'Low', 'High', 'Close']])
计数直方图做对比
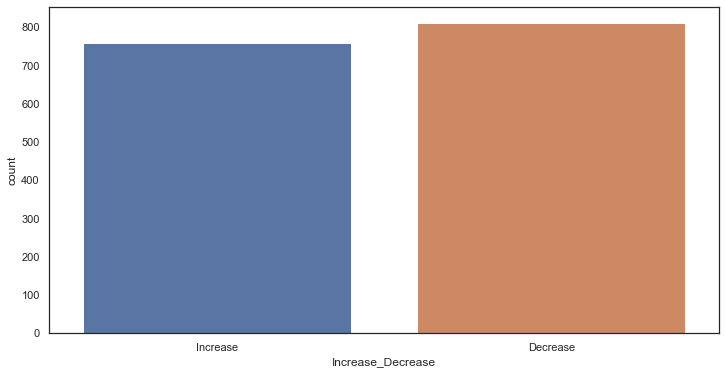
dataset['Increase_Decrease'].value_counts()
Decrease 812
Increase 759
Name: Increase_Decrease, dtype: int64
计数直方图会自动聚合求和。可以用以比较各个不同阶段成交量或成交金额的有力工具。
sns.countplot(
dataset['Increase_Decrease'],
label="Count")
散点图看相关性
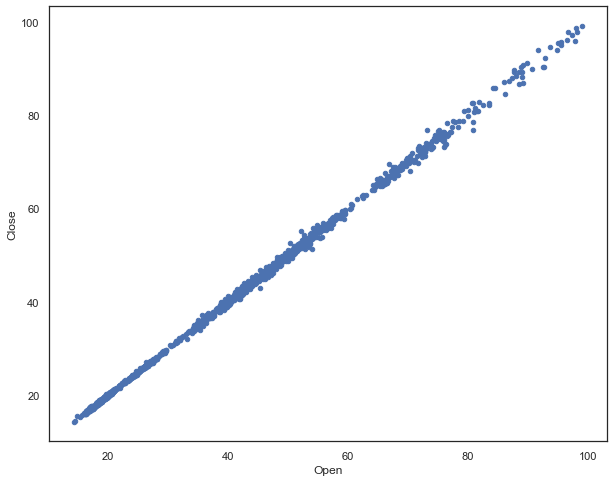
散点图表示因变量(Y轴数值)随自变量(X轴数值)变化的大致趋势,从而选择合适的函数对数据点进行拟合;散点图中包含的数据越多,比较的效果也越好。
可以使用散点图提供关键信息:
1、变量之间是否存在数量关联趋势;
2、如果存在关联趋势,是线性还是曲线的;
3、如果有某一个点或者某几个点偏离大多数点,也就是离群值,通过散点图可以一目了然。从而可以进一步分析这些离群值是否可能在建模分析中对总体产生很大影响。
# Scatterplot
dataset.plot(kind="scatter",
x="Open",
y="Close",
figsize=(10,8))
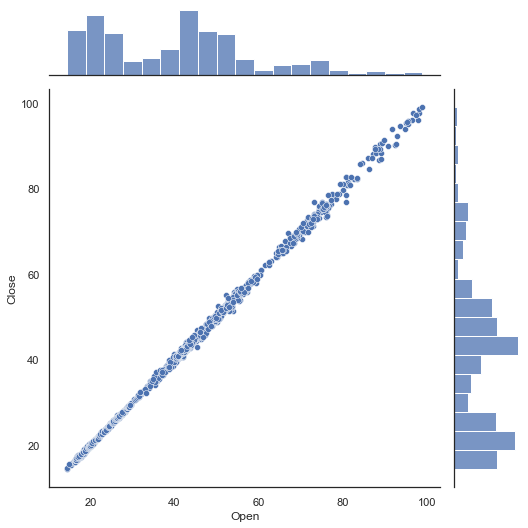
二元散点图和一元直方图
用 sns.jointplot 可以同时看到两个变量的联合分布与单变量的独立分布。
grid=sns.jointplot(x="Open",
y="Close",
data=dataset,
size=5)
grid.fig.set_figwidth(8)
grid.fig.set_figheight(8)
联合分布图也可以自动进行 KDE 和回归。
sns.jointplot(dataset.loc[:,'Open'],
dataset.loc[:,'Close'],
kind="reg",
color="#ce1414")
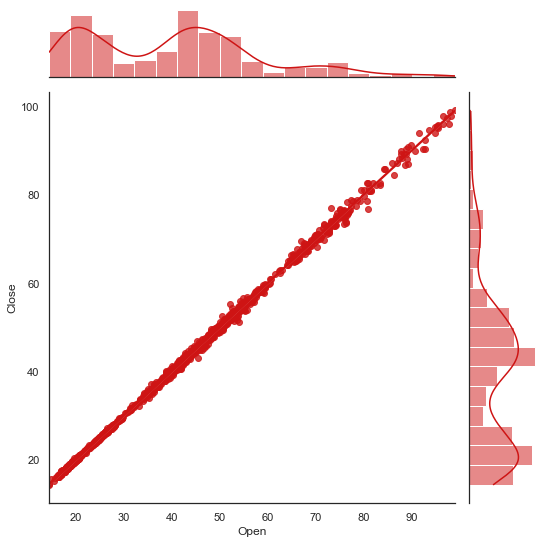
结构化多绘图网格
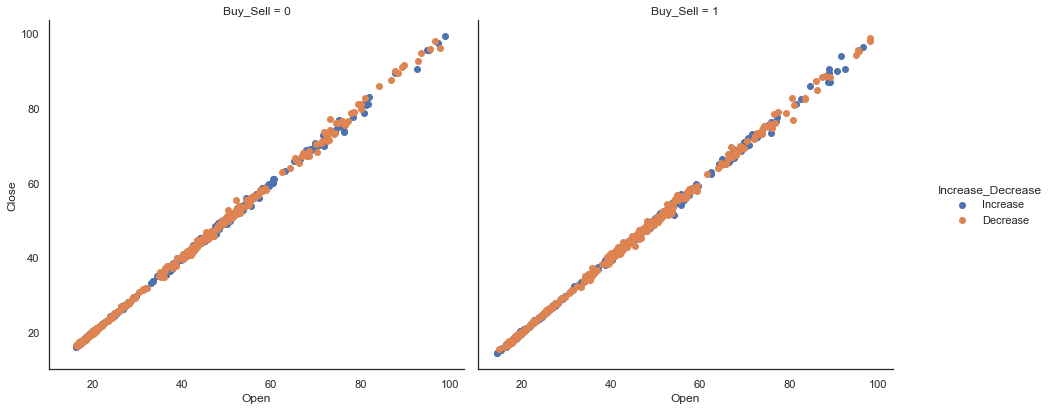
当您想要在数据集的子集中分别可视化变量的分布或多个变量之间的关系时,FacetGrid[1]类非常有用。一个FacetGrid可以与多达三个维度可以得出:row,col,和hue。前两个与得到的轴阵列有明显的对应关系; 将色调变量视为沿深度轴的第三个维度,其中不同的级别用不同的颜色绘制。
基本工作流程是FacetGrid使用数据集和用于构造网格的变量初始化对象。然后,可以通过调用FacetGrid.map()或将一个或多个绘图函数应用于每个子集 FacetGrid.map_dataframe()。最后,可以使用其他方法调整绘图,以执行更改轴标签,使用不同刻度或添加图例等操作。
grid = sns.FacetGrid(dataset,
col='Buy_Sell',
hue="Increase_Decrease",
size=5) \
.map(plt.scatter, "Open", "Close") \
.add_legend()
grid.fig.set_figwidth(15)
grid.fig.set_figheight(6)
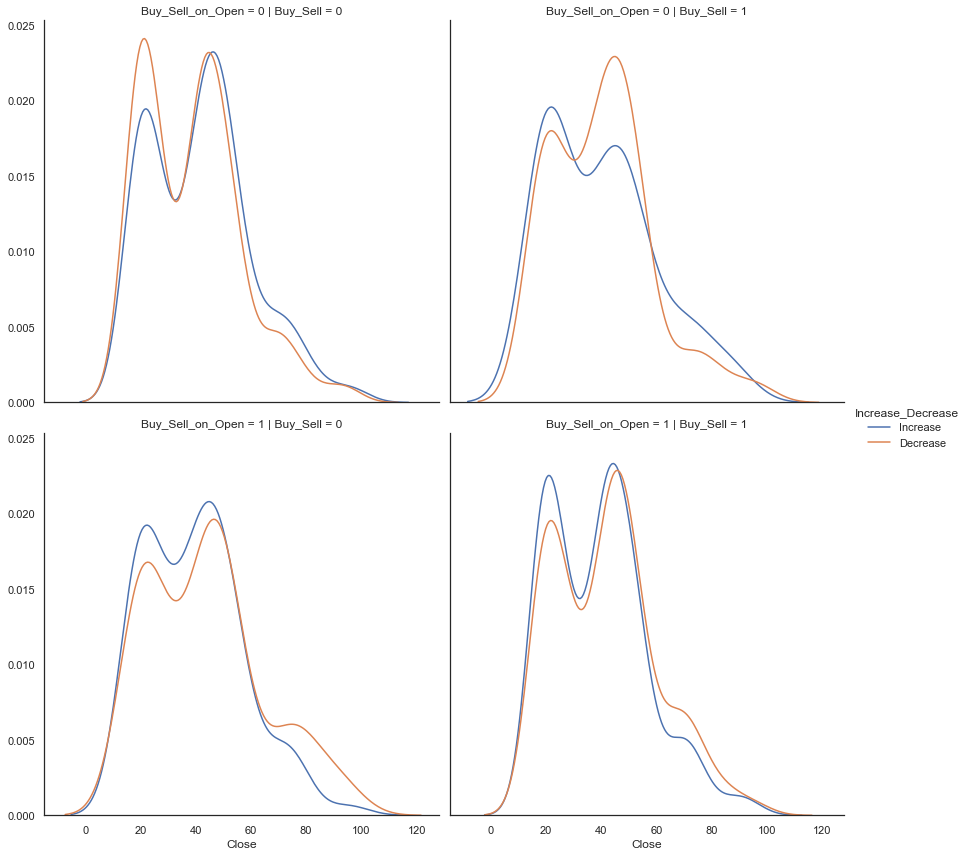
grid = sns.FacetGrid(dataset,
col='Buy_Sell',
row='Buy_Sell_on_Open',
hue="Increase_Decrease",
size=6)
grid.map(sns.kdeplot, "Close")
grid.add_legend()
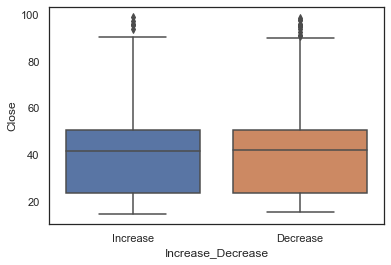
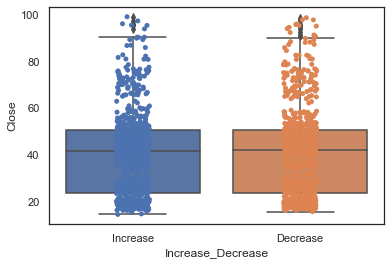
箱图可看离群值
# Boxplot
sns.boxplot(x='Increase_Decrease',
y=dataset['Close'],
data=dataset)
分类散点图
按照不同类别对样本数据进行分布散点图绘制。
ax = sns.boxplot(x='Increase_Decrease',
y=dataset['Close'],
data=dataset)
ax = sns.stripplot(x='Increase_Decrease',
# 按照x轴类别进行绘制
y=dataset['Close'],
data=dataset,
jitter=True,
# 当数据重合较多时,用该参数做一些调整,
# 也可以设置间距如,jitter = 0.1
edgecolor="gray")
# 可以通过hue参数对散点图中的数值进行分类
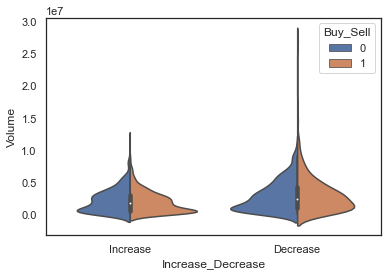
小提琴图
小提琴图是箱线图与核密度图的结合,箱线图展示了分位数的位置,核密度图则展示了任意位置的密度,通过小提琴图可以知道哪些位置的数据点聚集的较多,因其形似小提琴而得名。
其外围的曲线宽度代表数据点分布的密度,中间的箱线图则和普通箱线图表征的意义是一样的,代表着中位数、上下分位数、极差等。细线代表 置信区间。
当使用带有两种颜色的变量时,将split设置为 True 则会为每种颜色绘制对应半边小提琴。从而可以更容易直接的比较分布。
sns.violinplot(x='Increase_Decrease',
y=dataset['Volume'],
hue='Buy_Sell',
split=True,
data=dataset,
size=6)
热力图
热力图在实际中常用于展示一组变量的相关系数矩阵,在展示列联表的数据分布上也有较大的用途,通过热力图我们可以非常直观地感受到数值大小的差异状况。
sns.heatmap(dataset[['Open', 'High', 'Low', 'Adj Close', 'Volume', 'Returns']].corr(),
annot=True,
linewidths=.5,
fmt= '.3f')
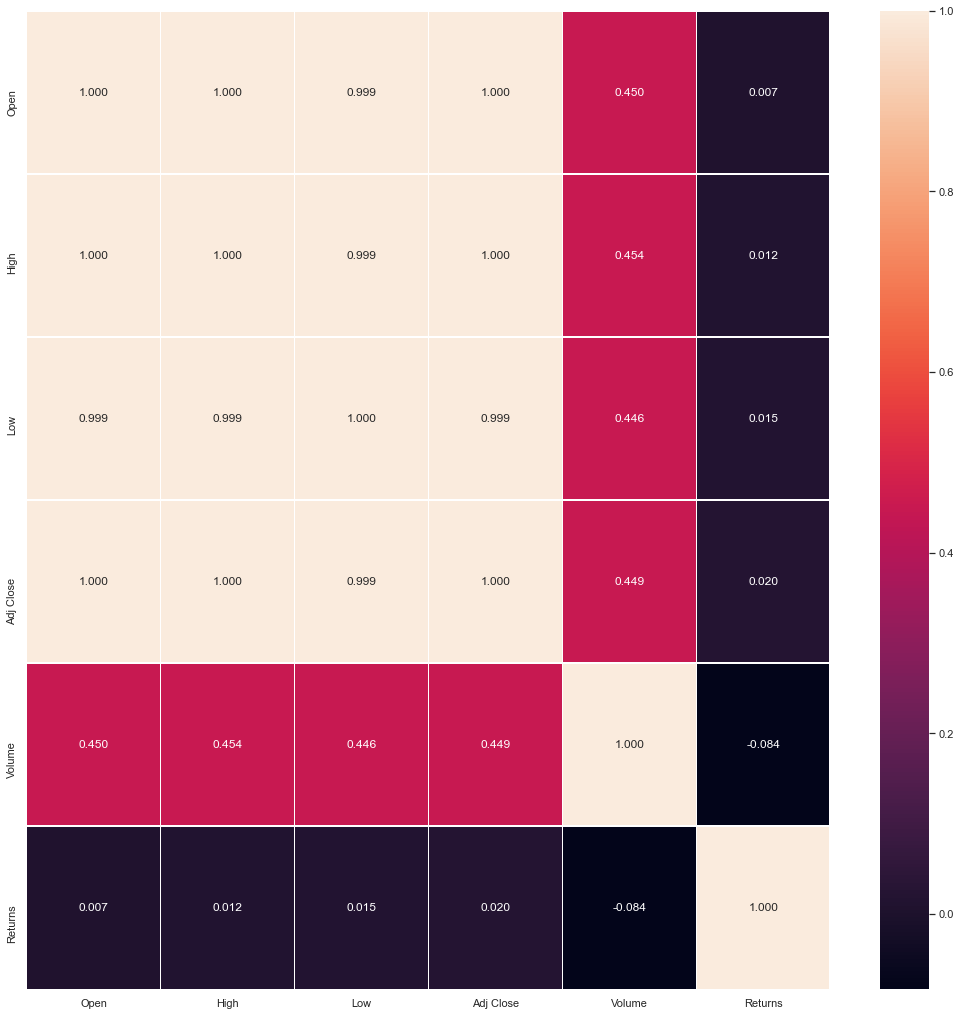
热力图的右侧是颜色带,上面代表了数值到颜色的映射,数值由小到大对应色彩由暗到亮。
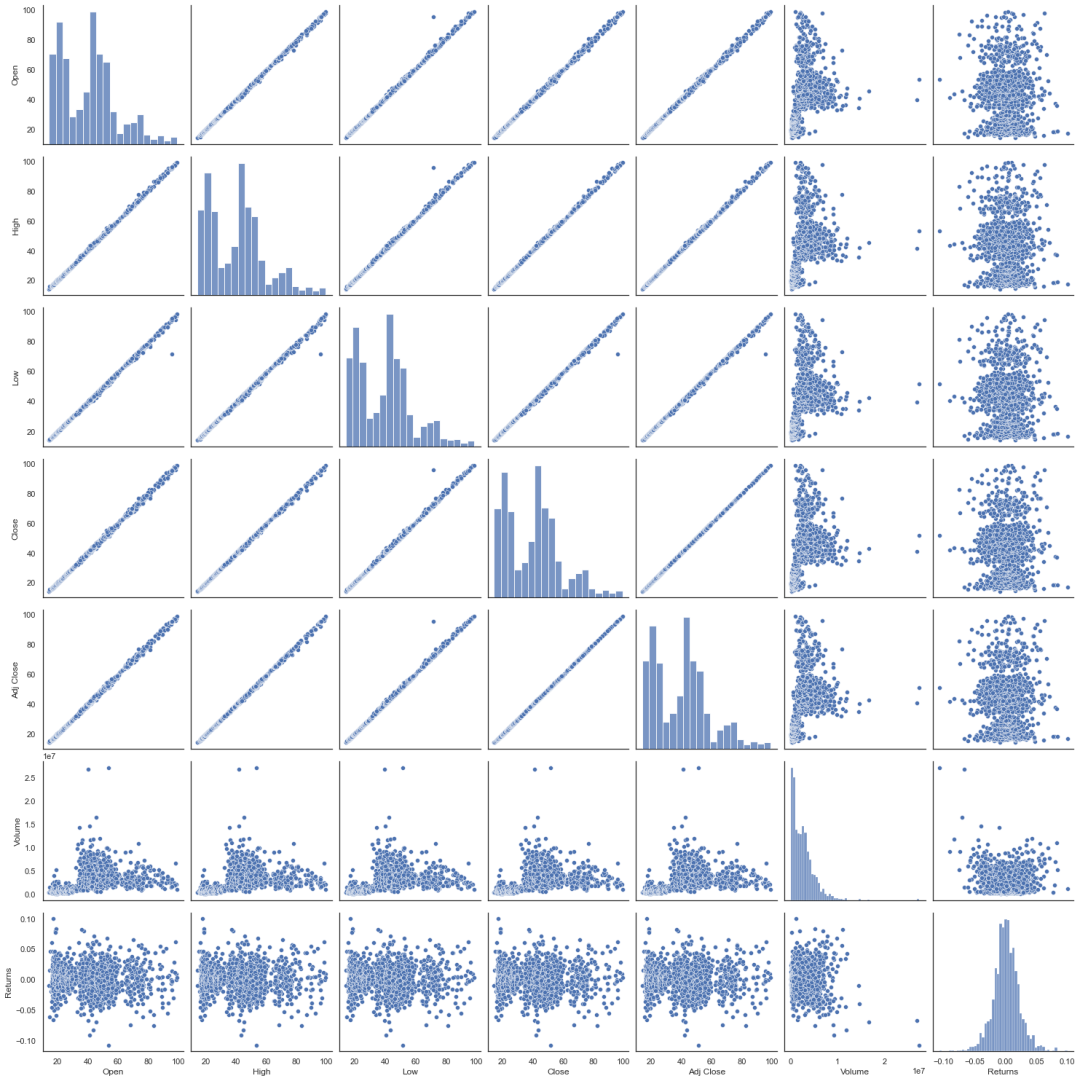
pairplot看特征间的关系
seaborn中pairplot函数可视化探索数据特征间的关系。
当你需要对多维数据集进行可视化时,最终都要使用散布矩阵图**(pair plot)** 。如果想画出所有变量中任意两个变量之间的图形,用矩阵图探索多维数据不同维度间的相关性非常有效。
散布图有两个主要用途。其一,他们图形化地显示两个属性之间的关系。直接使用散布图,或使用变换后属性的散布图,也可以判断非线性关系。
其二,当类标号给出时,可以使用散布图考察两个属性将类分开的程度。意思是用一条直线或者更复杂的曲线,将两个属性定义的平面分成区域,每个区域包含一个类的大部分对象,则可能基于这对指定的属性构造精确的分类器。
sns.pairplot(dataset.drop(
["Increase_Decrease", "Buy_Sell_on_Open",
"Buy_Sell"],axis=1), size=3,
# diag_kind="kde"
)
PairGrid 成对关系子图
子图网格,用于在数据集中绘制成对关系。
此类将数据集中的每个变量映射到多轴网格中的列和行。可以使用不同的axes-level绘图函数在上三角形和下三角形中绘制双变量图,并且每个变量的边际分布可以显示在对角线上。
它还可以使用hue参数表示条件化的附加级别,该参数以不同的颜色绘制不同的数据子集。这使用颜色来解析第三维上的元素,但仅在彼此之上绘制子集,而不会像axes-level函数接受色相那样为特定的可视化效果定制色相参数。
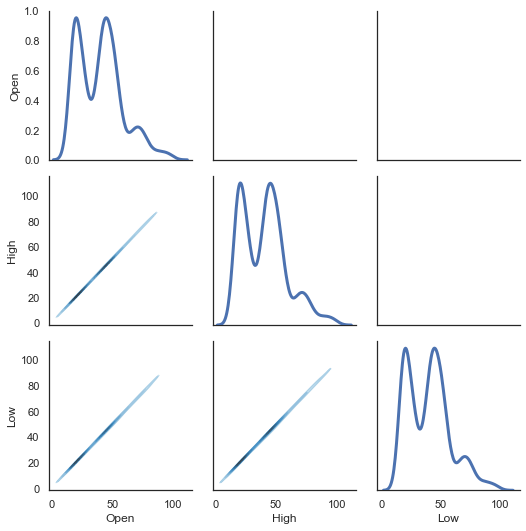
sns.set(style="white")
df = dataset.loc[:,['Open','High','Low']]
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot, cmap="Blues_d")
g.map_upper(plt.scatter)
g.map_diag(sns.kdeplot, lw=3)
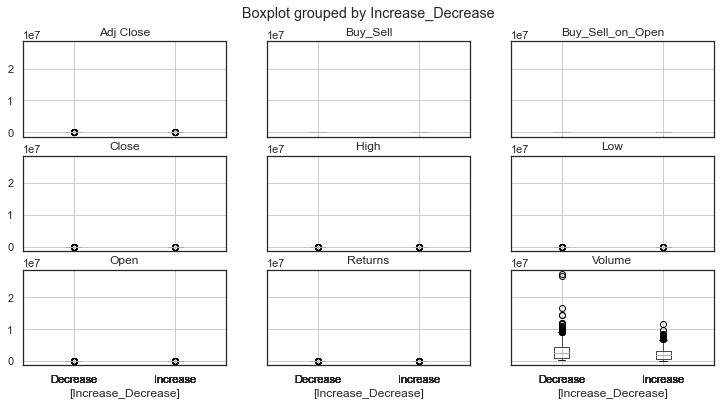
dataset.boxplot(by="Increase_Decrease", figsize=(12, 6))
pandas绘图
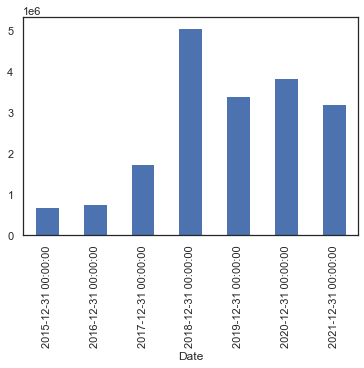
条形图
dataset['Volume'].resample('Y').mean().plot.bar()
pandas可视化[2]中,可以使用Series和DataFrame上的plot方法,它只是一个简单的包装器 plt.plot(),另外还有一些有几个绘图功能在pandas.plotting 内。
安德鲁斯曲线
安德鲁斯曲线[3]允许将多元数据绘制为大量曲线,这些曲线是使用样本的属性作为傅里叶级数的系数而创建的。通过为每个类别对这些曲线进行不同的着色,可以可视化数据聚类。属于同一类别的样本的曲线通常会更靠近在一起并形成较大的结构。
from pandas.plotting import andrews_curves
andrews_curves(dataset[
['Open', 'Close', 'Increase_Decrease']],
"Increase_Decrease")
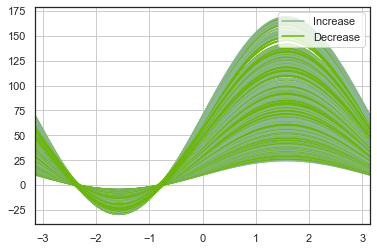
平行坐标
平行坐标[4]是一种用于绘制多元数据的绘制技术 。平行坐标允许人们查看数据中的聚类,并直观地估计其他统计信息。使用平行坐标点表示为连接的线段。每条垂直线代表一个属性。一组连接的线段代表一个数据点。趋于聚集的点将显得更靠近。
from pandas.plotting import parallel_coordinates
parallel_coordinates(dataset[
['Open', 'High', 'Low', 'Increase_Decrease']],
"Increase_Decrease")
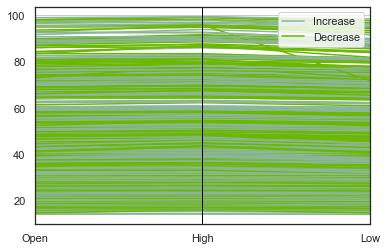
径向坐标可视化
RadViz是一种可视化多变量数据的方法。它基于简单的弹簧张力最小化算法。基本上,在平面上设置了一堆点。在我们的情况下,它们在单位圆上等距分布。每个点代表一个属性。然后,假设数据集中的每个样本都通过弹簧连接到这些点中的每个点,弹簧的刚度与该属性的数值成正比(将它们标准化为单位间隔)。样本在平面上的沉降点(作用在样本上的力处于平衡状态)是绘制代表样本的点的位置。根据样本所属的类别,其颜色会有所不同。
from pandas.plotting import radviz
radviz(dataset[
['Open','High', 'Low', 'Close', 'Increase_Decrease']],
"Increase_Decrease")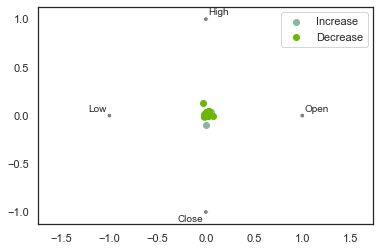
滞后图
滞后图用于检查数据集或时间序列是否随机。随机数据在滞后图中不应显示任何结构。非随机结构意味着基础数据不是随机的。该lag参数可以传递,而当lag=1时基本上是data[:-1]对 data[1:]。
from pandas.plotting import lag_plot
lag_plot(dataset['Volume'].tail(250))
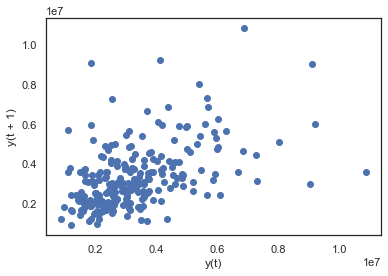
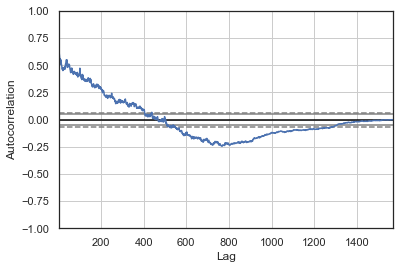
自相关图
自相关图通常用于检查时间序列中的随机性。通过在变化的时滞中计算数据值的自相关来完成此操作。如果时间序列是随机的,则对于任何和所有时滞间隔,此类自相关应接近零。如果时间序列不是随机的,则一个或多个自相关将明显为非零。图中显示的水平线对应于95%和99%的置信带。虚线是99%置信带。
from pandas.plotting import autocorrelation_plot
autocorrelation_plot(dataset['Volume'])
参考资料
FacetGrid: https://blog.csdn.net/weixin_42398658/article/details/82960379
[2]pandas可视化: https://pandas.pydata.org/pandas-docs/stable/user_guide/visualization.html
[3]安德鲁斯曲线: https://en.wikipedia.org/wiki/Andrews_plot
[4]平行坐标: https://en.wikipedia.org/wiki/Parallel_coordinates
--END--
留言赠书
赠书规则:给本文点赞("在看"不作要求),扫描下方二维码,添加老表的微信。把点赞截图发给我,我会发送抽奖码给大家,时间截止至05月28号 20:00。,可获得《人工智能数学基础》赠书一本。
扫码即可加我微信
观看朋友圈,获取最新学习资源
注意:中奖者24小时内,微信私聊我回复:书名+姓名+电话+收件地址即可领取,逾期不候!为了大家都有机会中奖,本月已经中过书的朋友,再次中奖将不再赠书。
本批书籍由 北京大学出版社 赞助,再次致谢。也欢迎大家自行前往购买支持。
简说Python 投稿规则及激励
规则:必须是自己的原创文章,和Python相关技术文章,形式不限制(文字、图文、漫画等),字数800+,在微信公众号首发。
激励
根据文章内容 字数 分为两种基础和深度
基础文章:每投稿两篇可以获得技术相关图书一本 从书单里选
深度文章:每1k字50-100元(代码不算)
额外激励
文章阅读量超过2000,激励50元
文章被同量级大号转载次数5次及以上,激励100元
长期投稿作者还有额外激励,技术能力可以的,还可以一起做项目,接私活,内推等。
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢