
一键数据分析&自动化特征工程!
创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。——Andrew Ng
业内常说数据决定了模型效果上限,而机器学习算法是通过数据特征做出预测的,好的特征可以显著地提升模型效果。这意味着通过特征生成(即从数据设计加工出模型可用特征),是特征工程相当关键的一步。
本文从特征生成作用、特征生成的方法(人工设计、自动化特征生成)展开阐述并附上代码。
1 特征生成的作用
特征生成是特征提取中的重要一步,作用在于:
增加特征的表达能力,提升模型效果;(如体重除以身高就是表达健康情况的重要特征,而单纯看身高或体重,对健康情况表达就有限。) 可以融入业务上的理解设计特征,增加模型的可解释性;
2 数据情况分析
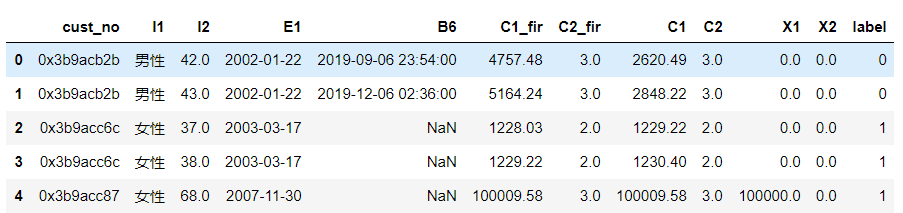
本文示例的数据集是客户的资金变动情况,如下数据字典:
cust_no:客户编号;I1 :性别;I2:年龄 ;E1:开户日期;
B6 :近期转账日期;C1 (后缀_fir表示上个月):存款;C2:存款产品数;
X1:理财存款;X2:结构性存款; label:资金情况上升下降情况。
 这里安利一个超实用Python库,可以一键数据分析(数据概况、缺失、相关性、异常值等等),方便结合数据分析报告做特征生成。
这里安利一个超实用Python库,可以一键数据分析(数据概况、缺失、相关性、异常值等等),方便结合数据分析报告做特征生成。
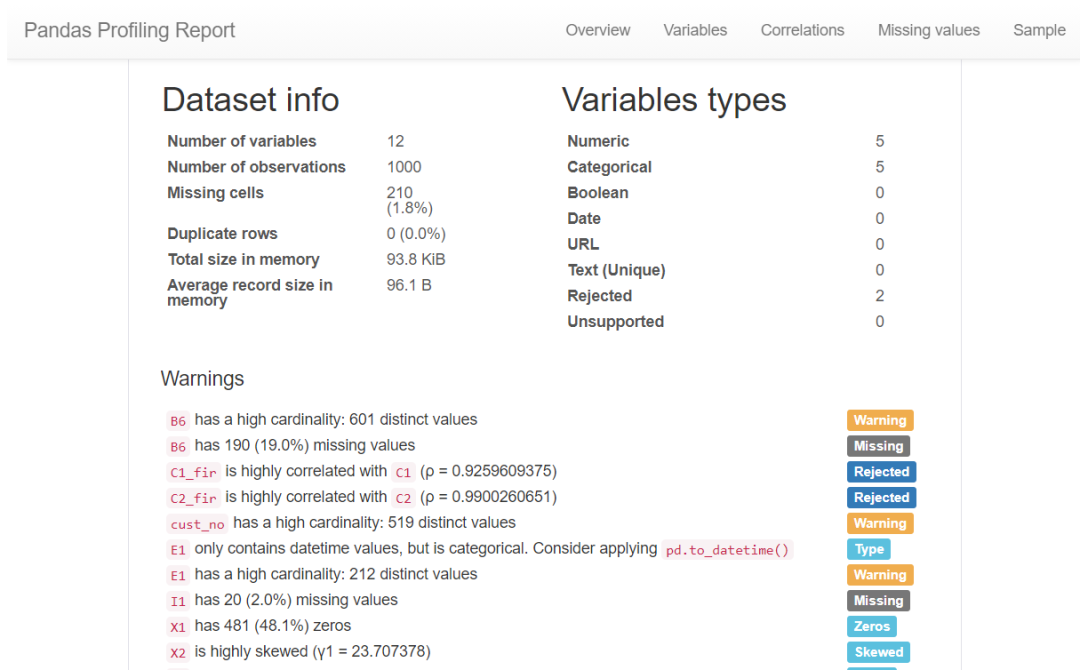
# 一键数据分析
import pandas_profiling
pandas_profiling.ProfileReport(df)
3 自动化特征生成
传统的特征工程方法通过人工构建特征,这是一个繁琐、耗时且容易出错的过程。自动化特征工程是通过Fearturetools等工具,从一组相关数据表中自动生成有用的特征的过程。对比人工生成特征会更为高效,可重复性更高,能够更快地构建模型。
3.1 FeatureTools上手

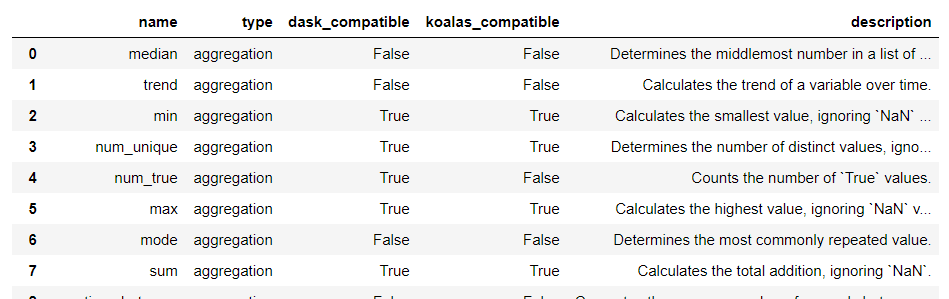
Featuretools是一个用于执行自动化特征工程的开源库,它有基本的3个概念:1)Feature Primitives(特征基元):生成特征的常用方法,分为聚合(agg_primitives)、转换(trans_primitives)的方式。可通过如下代码列出featuretools的特征加工方法及简介。
import featuretools as ft
ft.list_primitives()
2)Entity(实体) 可以被看作类似Pandas DataFrame, 多个实体的集合称为Entityset。实体间可以根据关联键添加关联关系Relationship。
# df1为原始的特征数据
df1 = df.drop('label',axis=1)
# df2为客户清单(cust_no唯一值)
df2 = df[['cust_no']].drop_duplicates()
df2.head()
# 定义数据集
es = ft.EntitySet(id='dfs')
# 增加一个df1数据框实体
es.entity_from_dataframe(entity_id='df1',
dataframe=df1,
index='id',
make_index=True)
# 增加一个df2数据实体
es.entity_from_dataframe(entity_id='df2',
dataframe=df2,
index='cust_no')
# 添加实体间关系:通过 cust_no键关联 df_1 和 df 2实体
relation1 = ft.Relationship(es['df2']['cust_no'], es['df1']['cust_no'])
es = es.add_relationship(relation1)
3)dfs(深度特征合成) : 是从多个数据集创建新特征的过程,可以通过设置搜索的最大深度(max_depth)来控制所特征生成的复杂性
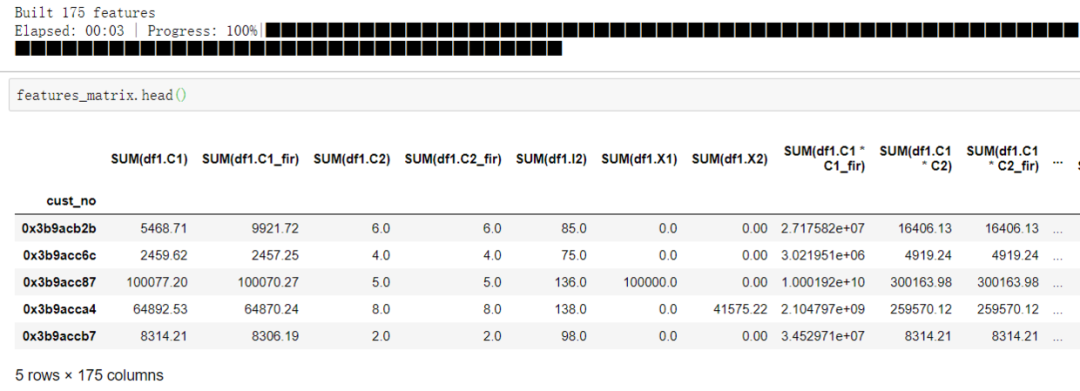
## 运行DFS特征衍生
features_matrix,feature_names = ft.dfs(entityset=es,
target_entity='df2',
relationships = [relation1],
trans_primitives=['divide_numeric','multiply_numeric','subtract_numeric'],
agg_primitives=['sum'],
max_depth=2,n_jobs=1,verbose=-1)
3.2 FeatureTools问题点
4.2.1 内存溢出问题 Fearturetools是通过工程层面暴力生成所有特征的过程,当数据量大的时候,容易造成内存溢出。解决这个问题除了升级服务器内存,减少njobs,还有一个常用的是通过只选择重要的特征进行暴力衍生特征。
4.2.2 特征维度爆炸 当原始特征数量多,或max_depth、特征基元的种类设定较大,Fearturetools生成的特征数量巨大,容易维度爆炸。这是就需要考虑到特征选择、特征降维。