
调包侠神器2.0发布,Python机器学习模型搭建只需要几行代码
共 1670字,需浏览 4分钟
·
2020-12-07 22:12
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
Python开源机器学习建模库PyCaret,刚刚发布了2.0版本。

这款堪称「调包侠神器」的模型训练工具包,几行代码就能搞定模型编写、改进和微调。
从数据预处理到模型效果对比,PyCaret都能自动实现。
所以,PyCaret长啥样,2.0的版本又做了什么改进?
一起来看看。
机器学习库的「炼丹炉」
PyCaret说白了,有点像一个机器学习库的炼丹炉。
以下是它「熔」进来的部分库:
数据处理:pandas、numpy…
数据可视化:matplotlib、seaborn…
各种模型:sklearn、xgboost、catboost、lightgbm…
嗯…sklearn直接就给封装进去了,调用很方便。
然后,PyCaret这个炼丹炉,自带功能“按键”(定义了一些函数),包括数据预处理、模型训练、模型集成、模型分析、模型测试等。
只需要写上几行Python代码,这些功能“按键”就会被按下,PyCaret自动帮你实现。
至于实现过程中需要调用什么基本库,那些可以放弃思考不需要考虑。
从下图来看,仅仅是预处理阶段,就包含样本划分、数据预处理、缺失值处理、归一化、独热编码等功能。
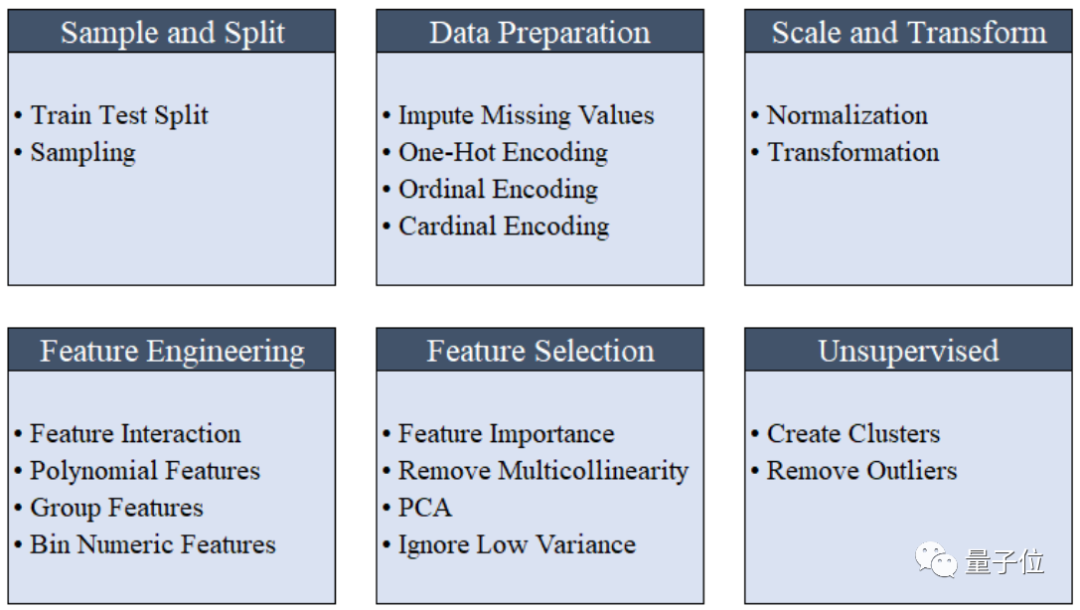
如果要实现必需的预处理功能,需要多少行代码来调用?
答案是0行。
因为,当使用setup()进行初始化时,PyCaret将自动执行机器学习必需的数据预处理步骤,包括缺失值插入、分类变量编码、标签编码、数据集拆分等。
例如,在数据处理前,你发现数据集有空缺的地方(下图中NaN部分)。

别怕,PyCaret会自动分析数据,进行缺失值插入。

预处理后,PyCaret还贴心地帮你准备了各种模型。
从模型训练、选用到测试,只有你想不到的,没有它做不了的。
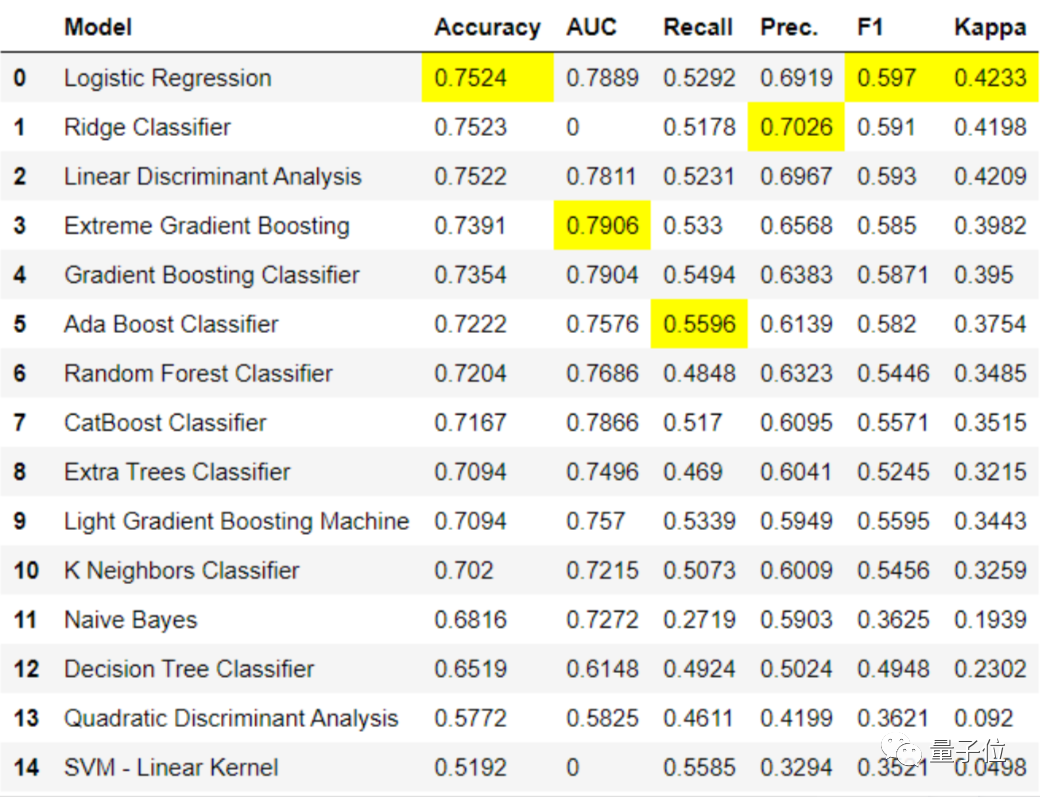
如果已经将数据处理好,并交给PyCaret,一个compare_models函数就能训练库中的所有模型,进行结果比较后,标出最佳模型。
如下图,各种模型指标的最优值会被一键标黄,就看你怎么选择了。
选好后,想对模型进行一点优化?一个tune_model函数就能帮你搞定。
或者,不想仅仅选用一个模型?
PyCaret也准备了模型集成的函数,blend和stack任你选。
除此之外,模型参数的分析(包括可视化)也只需要几行代码就能实现,功能非常强大。
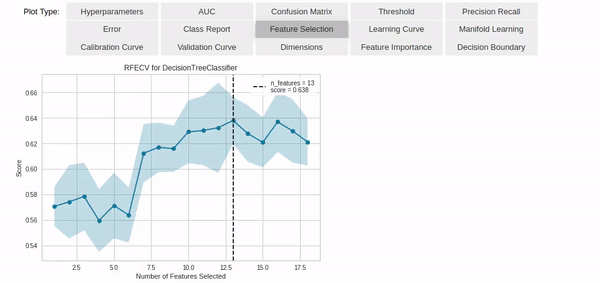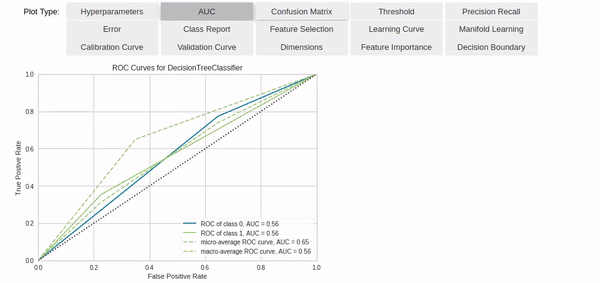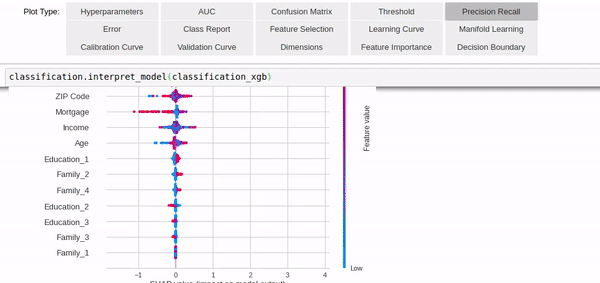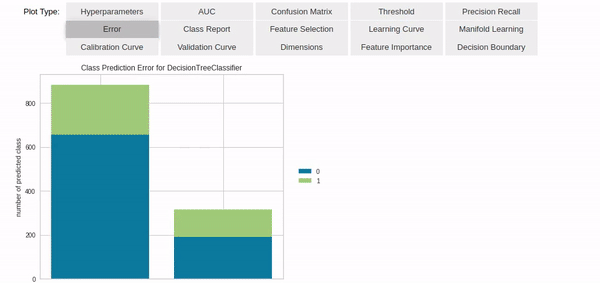
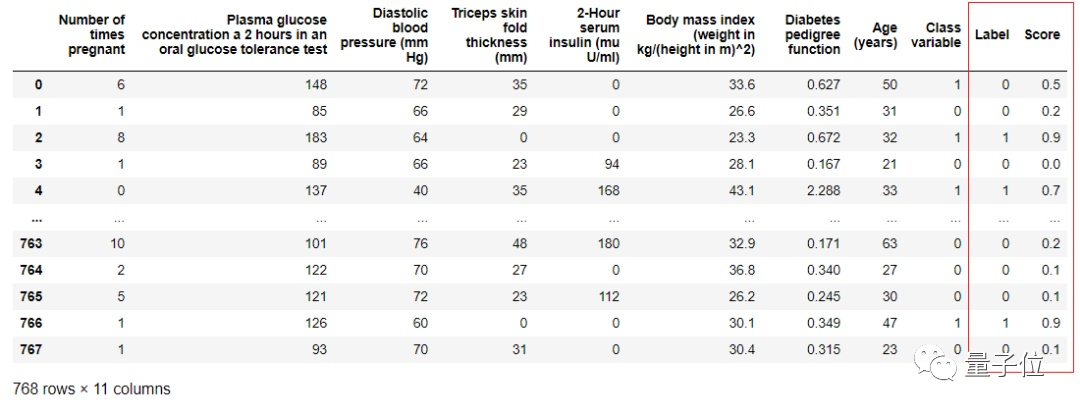
最后,PyCaret还能为新数据提供迭代预测结果,下面的效果,同样只需要几行代码就能完成。
那么,这次PyCaret增强,进行了什么改进呢?(项目见传送门)
PyCaret 2.0增强版
这是PyCaret 2.0的6大特色,有些在1.0就有了,有些功能如实验日志,看起来是更新后新加入的功能。

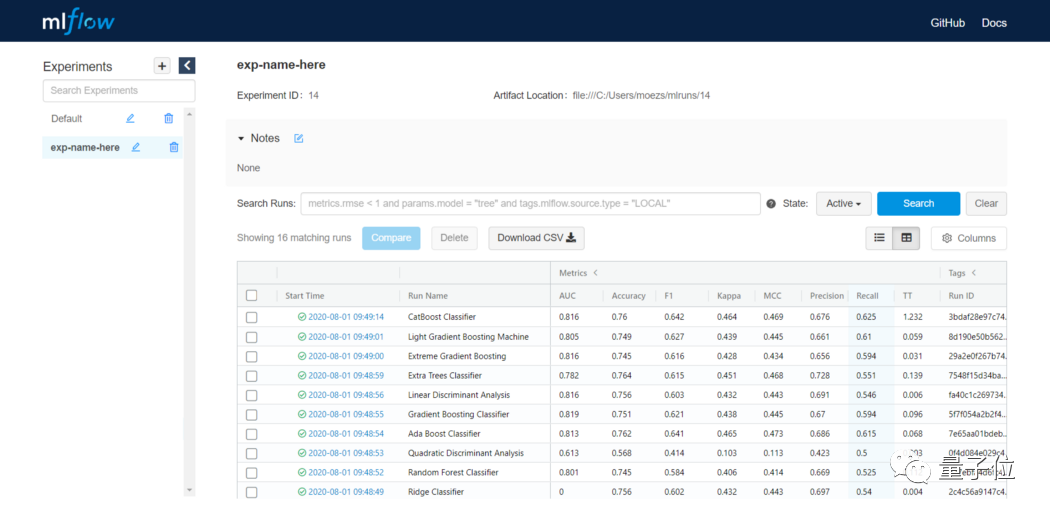
实验日志,对于模型的调整不可或缺。
例如,想要将训练过程中模型的精度变化可视化,通常我们会在模型中加入生成日志文件的函数,生成一个更直观的时间-精度变化图。
PyCaret 2.0加入了实验日志的功能,自动帮你跟踪模型实验过程中的各项指标,以及生成视觉效果等。
不仅如此,在2.0中,模型生成到预测的所有工作流程,现在可以被设计了。
也就是说,你可以设置一条自定义「流水线」,在这个过程中,从训练到测试,所有模块的功能都会被自动化完成。
甚至,PyCaret 2.0还提供了机器学习模型前端软件的搭建工具。
以及,PyCaret 2.0现在几乎支持所有算法的并行处理,xgboost和catboost模型也支持GPU训练。
除此之外,还有一些新的程序功能,等待你去发现。
传送门
项目地址:
https://github.com/pycaret/pycaret/releases/tag/2.0
参考链接:
https://towardsdatascience.com/announcing-pycaret-2-0-39c11014540e