
从经典到最新前沿,一文概览2D人体姿态估计
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

来自 | 知乎 作者 | 谢一宾

单人姿态估计是基础,在这个问题中,我们要做的事情就是给我们一个人的图片,我们要找出这个人的所有关键点,常用的MPII数据集就是单人姿态估计的数据集。
在多人姿态估计中,我们得到的是一张多人的图,我们需要找出这张图中的所有人的关键点。对于这个问题,一般有自上而下(Top-down)和自下而上(Bottom-up)两种方法。 Top-down: (从人到关键点)先使用detector找到图片中的所有人的bounding box,然后在对单个人进行SPPE。这个方法是Detection+SPPE,往往可以得到更好的精度,但是速度较慢。 Bottom-up: (从关键点到人)先使用一个model检测(locate)出图片中所有关键点,然后把这些关键点分组(group)到每一个人。这种方法往往速度可以实时,但是精度较差。
遮挡(自遮挡,被其他人遮挡)
扩大感受野,让网络自己去学习被遮挡的关系
人的尺度不一,拍照角度不一
多尺度特征融合
各种各样的姿态
考验网络的容量,深度
光照
在数据预处理中加入光照变化的因素,对每个通道做偏移

使用AlexNet作为backbone
直接回归关节点的坐标
使用级联的结构来refine结果
Joint training with CNN and Graphical Model(LeCun, 2014)[2]
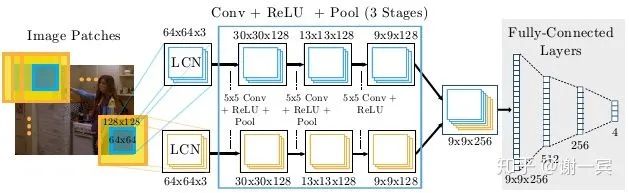
开始使用heatmap
CPM (CMU, 2016)[3]
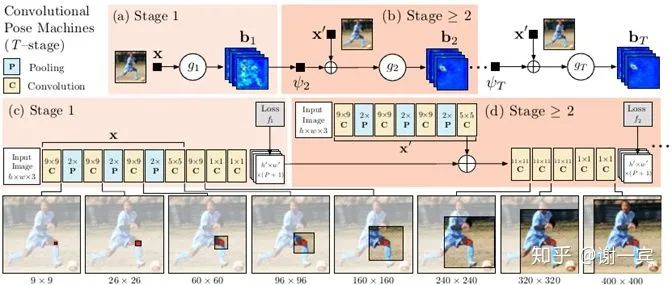
网络有多个stage组成,以第二个stage为例,他的输入由两部分组成,一个是上一个stage预测出的heatmap,一个是自己这个stage中得到的feature map,也就是在每一个stage都做一次loss计算,这样做可以使网络收敛更快也有助于提高精度。
上一层预测的heatmap可以提供丰富的spatial context,这对关节点的识别是非常重要的
正式开启e2e学习时代
Stacked Hourglass Network (Jia Deng组, 2016)[4]
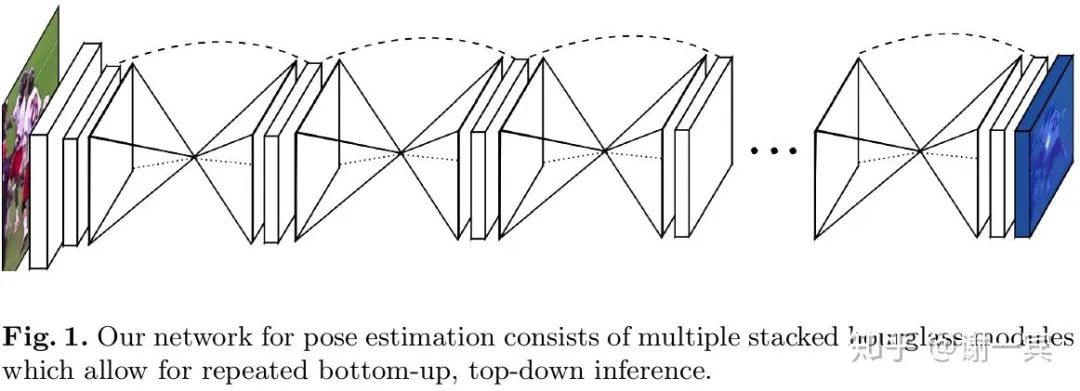
该工作的主要创新在于网络结构方面的改进,从图中可以看出,形似堆叠的沙漏。
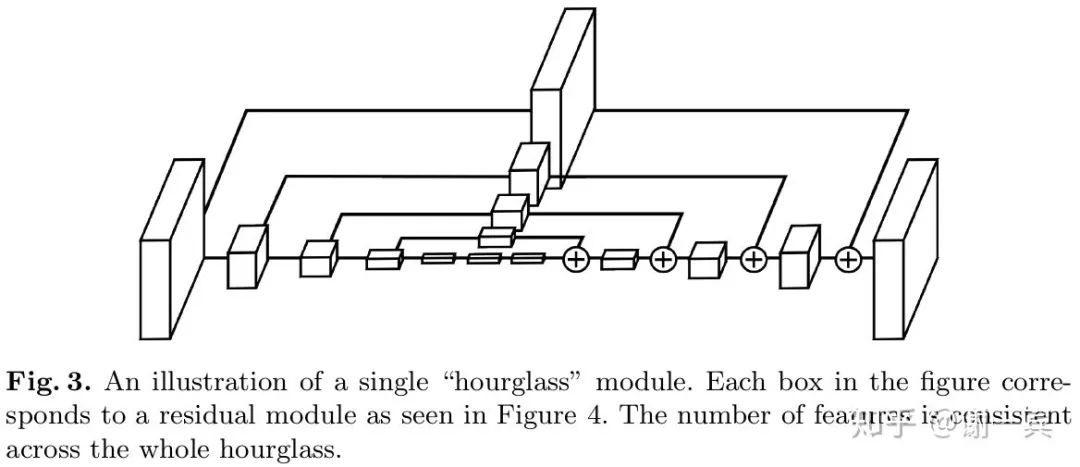
每一个沙漏模块包含了对称的下采样和上采样的过程,每一个box都代表了一个有跨层连接的子模块

网络使用了中间监督,也就是图中的蓝色框是一个预测的heatmap,这加快了网络的收敛也提高了实际效果
Fast Human Pose (2019)[5]

为了追求cost-effective,需要compact的网络结构
4-stage hourglass可以取得95%的8-stage的效果
一半的channel数(128)只会导致1%的performance drop
使用蒸馏来做监督的增强,Students learn knowledge from books (dataset) and teachers (advanced networks).
G-RMI (Google, 2017)[6]

Faster-RCNN得到bounding box之后进行image cropping,使得所有box具有同样的纵横比,然后扩大box来包含更多图像上下文

使用ResNet作为backbone来估计heatmap和offset vector,因为得到heatmap之后我们往往还需要一个argmax的操作才能得到关节点的坐标,而这个过程中由于网络的下采样过程,heatmap势必分辨率比原图更小,所以得到的坐标会出现偏移,因此又估计了一个offset vector来补偿掉这种量化误差。
OKS-based NMS:基于关键点相似度来衡量两个候选姿态的重叠情况,在目标检测中常基于IoU来做NMS,但是姿态估计中输出的是关键点,更适合用这种属性来衡量。
RMPE (上交卢策吾老师组, 2017)[7]

SSTN(Symmetric Spatial Transformer Network):在不准确的bounding box中提取担任区域
STN来选择RoI
SPPE帮助STM得到准确的区域
PNMS(Parametric Pose Non-Maximum-Suppression)来去除冗余的姿态
PGPG(Pose-Guided Proposals Generator)
Compositional Human Pose Regression (MSRA, 2018)[8]

CPN (旷视,2018)[9]
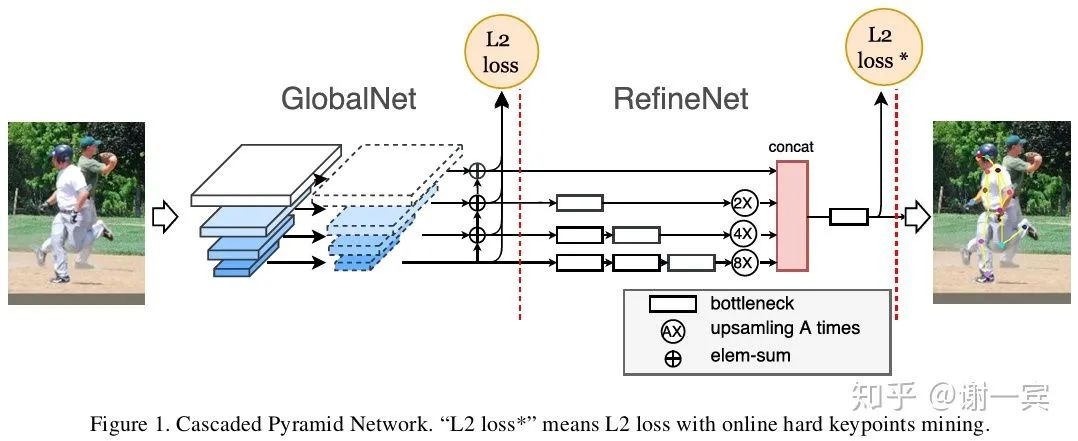
多尺度特征信息的融合是网络设计的一个很大的目标,作者使用 GlobalNet (global pyramid network, U-Shape)来处理easy keypoints,GlobalNet中包含了下采样和上采样(插值非转置卷积)的过程。
使用RefineNet (pyramid refined network)来处理hard keypoints
OHKM(online hard keypoints mining)用来找出hard keypoints,类似于检测中的OHEM
MSPN (旷视,2018)[10]
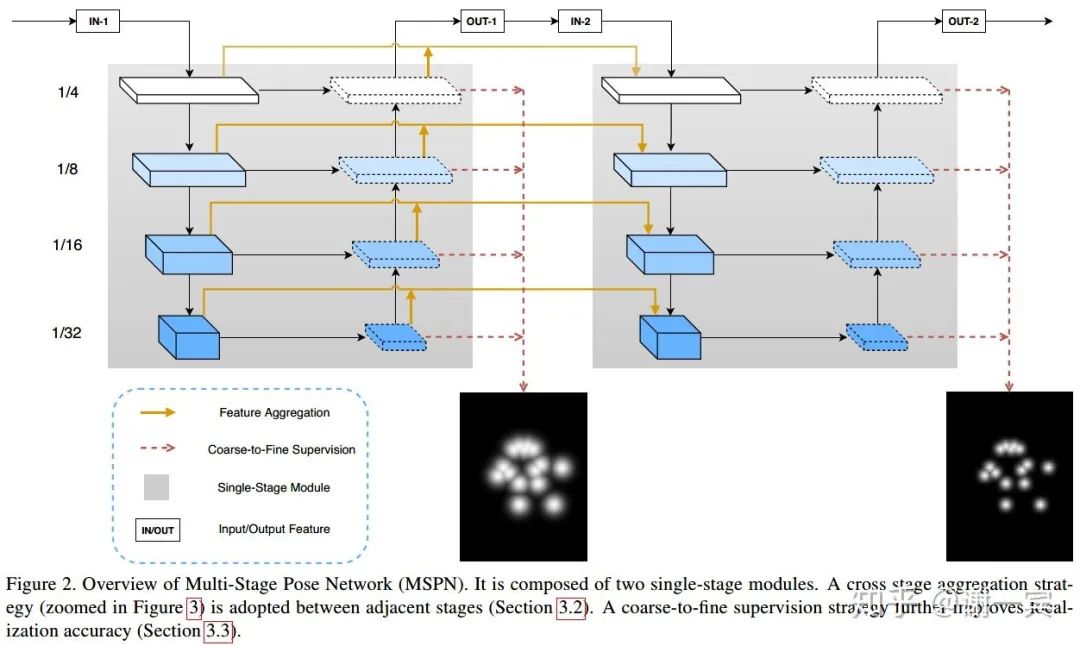
网络结构方面的改进
Simple Baseline (MSRA, 2018)[11]

从图中不难看出,这个网络结构非常简洁,作者使用Deconvolution来做上采样,网络中也没有不同特征层之间的跨层连接,和经典的网络结构Hourglass和CPN相比都十分简洁。
MultiPoseNet (2018)[12]
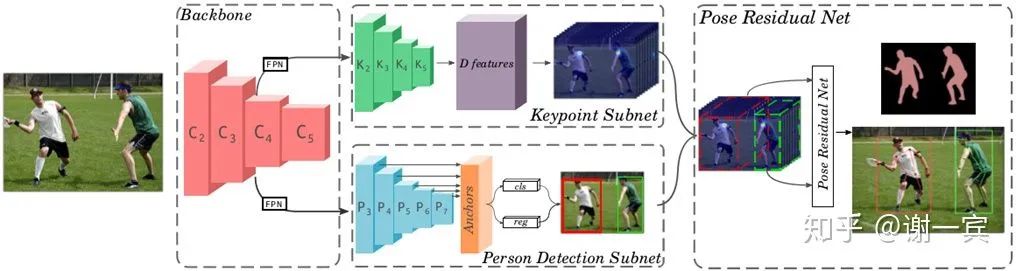
backbone也就是用来提取特征的部分采用的是resnet和两个FPN(用两个的原因是因为后面要接两个subnet)
keypoint subnet用来输出keypoint和segmentation的heatmap
person detect subnet用来检测人体,使用的是RetinaNet作为detector
pose residual network输出最终的pose,说是在学习了data的pose structures之后可以有效应对遮挡的问题
Deeply learned compositional models (2019)[13]
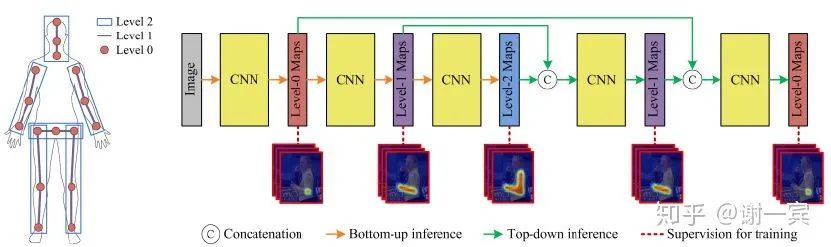
compositional models
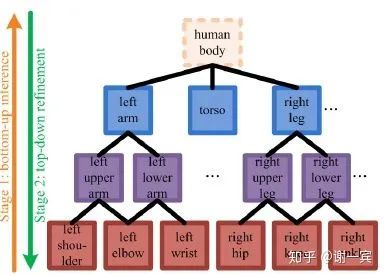
HRNet (MSRA, 2019)[14]

各个scale之间互相fuse,并不是一个串联的下采样过程,这样保留了原分辨率的feature,会有很好的spatial信息。
Enhanced Channel-wise and Spatial Information (字节跳动, 2019)[15]
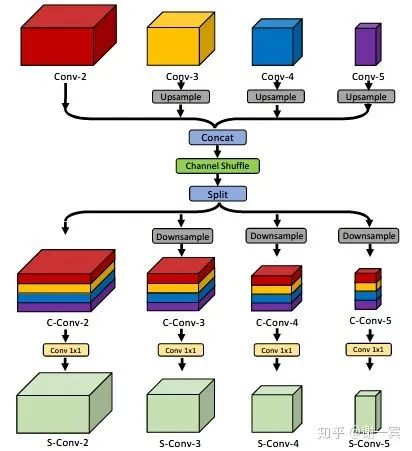
Channel Shuffle Module (CSM): reshape-transpose-reshape, 经过这一通操作之后,希望feature能够和通道的上下文信息相关。
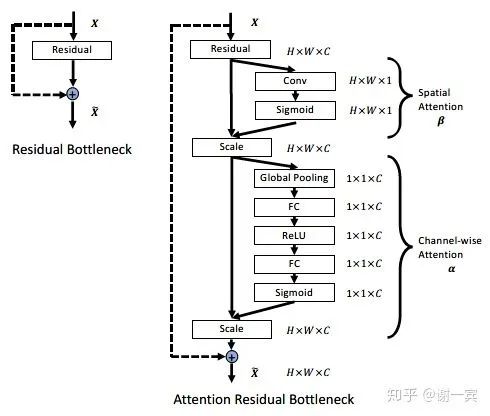
spatial attention: (feature level)希望网络对于特征图是pay attention to task-related regions而不是整张图片。
Channel-wise Attention: (channel level) 从SE-Net中借鉴来,主要包含GAP和Sigmoid两个步骤,希望网络可以选择更好的通道来detect pattern。
Related Parts Help (2019)[16]
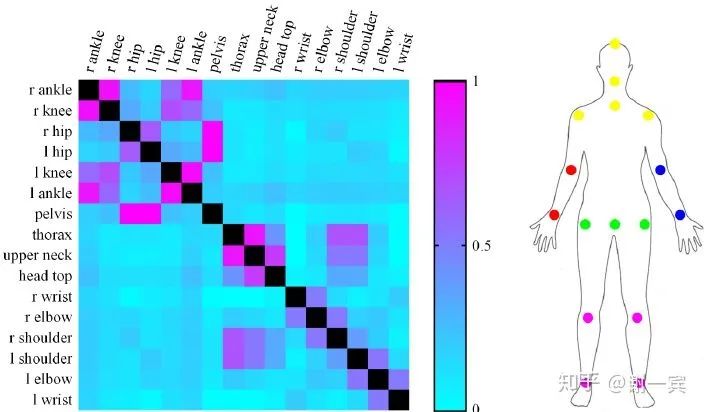
Related body parts 把keypoint分成多个group,根据mutual information
Part-based branching network (PBN) learn specific features for each group of related parts
Crowd Pose (上交卢策吾老师组,2019)[17]

在拥挤场景下,在同一个box内,我们可能需要处理很多其他人的关键点,该项工作设计了joints candidate loss来估计multi-peak heatmaps,让所有可能的关节点都作为候选。
Person-joint Graph: joint node是通过关节点间的距离来建立,person node通过检测的human proposals来建立,两者之间的edge通过看是否有contribution来建立。由此建立了一个人-关节的graph,也就转化到了图论问题上,目标就是最大化二分图中的边权重。使用updated Kuhn-Munkres解决这个问题。
Single-Stage Multi-Person Pose Machines (NUS, 2019)[18]
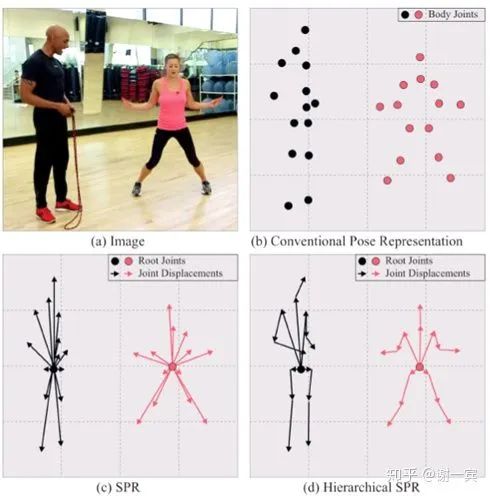
Hierarchical SPR
A unique root for each person
Several joint displacements for each joint
heatmap for root joint (L2 loss)
dense displacement map for each joint (smooth L1 loss)
DeepCut (Germany, 2016)[19]

pipeline(Bottom-up)
detect 检测人体关键点(Adapted Fast R-CNN)并且把他们表示为graph中的节点
label 使用人体关节点类别给检测出的关键点分类,比如arm, leg
partition 将关键点分组到同一个人
使用pairwise terms来做优化
Associative Embedding (Jia Deng组,2016)[20]
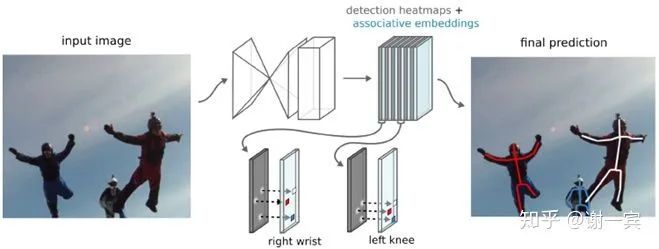
produce detection heatmaps and associate embedding tags together (bottom-up but single-stage) and then match detections to others that share the same embedding tag
主要的工作在于提出了associate embedding tag,也就是说预测每个关节点的时候也同时预测这个关节点的tag值,具有相同tag值的就是同一个人的关节点
DeeperCut (Germany, 2017)[21]
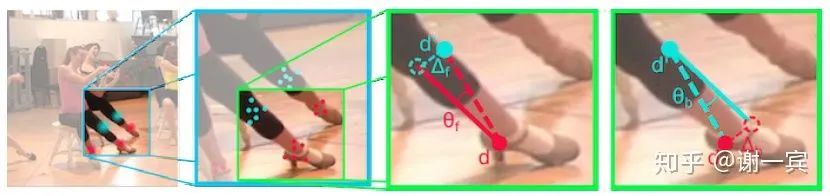
使用深层的ResNet架构来检测body part
使用image-conditioned pairwise terms来做优化,可以将众多候选节点减少,通过候选节点之间的距离来判断该节点是否重要
OpenPose (CMU, 2017)[22]

网络结构基于CPM改进,网络包含两个分支,一个分支预测heatmap,另一个分支预测paf(part affine field),paf也是这项工作的关键所在。
paf是两个关节点连接的向量场,可以把它看做肢体,以paf为基础,把group的问题转化文二分图匹配(bipartite graph)的问题,使用匈牙利算法求解。
PersonLab (2018)[23]

short-range offsets to refine heatmaps
mid-range to predict pairs of keypoints
greedy decoding to group keypoints into instances
PifPaf (EPFL, 2019)[24]

从图中可以看出,网络基于ResNet,encoder最后输出两个分支,PIF和PAF向量场。
PIF向量场是17x5,其中17是关节数,5表示用于优化heatmap的值。
PAF向量场是19x7,其中19代表了19种肢体连接,7表示了confidence和offset来优化肢体向量的值。
关键点由PIF给出,关键点之间的连接由PAF给出,接下来就是使用Greedy Decoding进行group的过程了。
HigherHRNet (字节跳动,2020)[25]
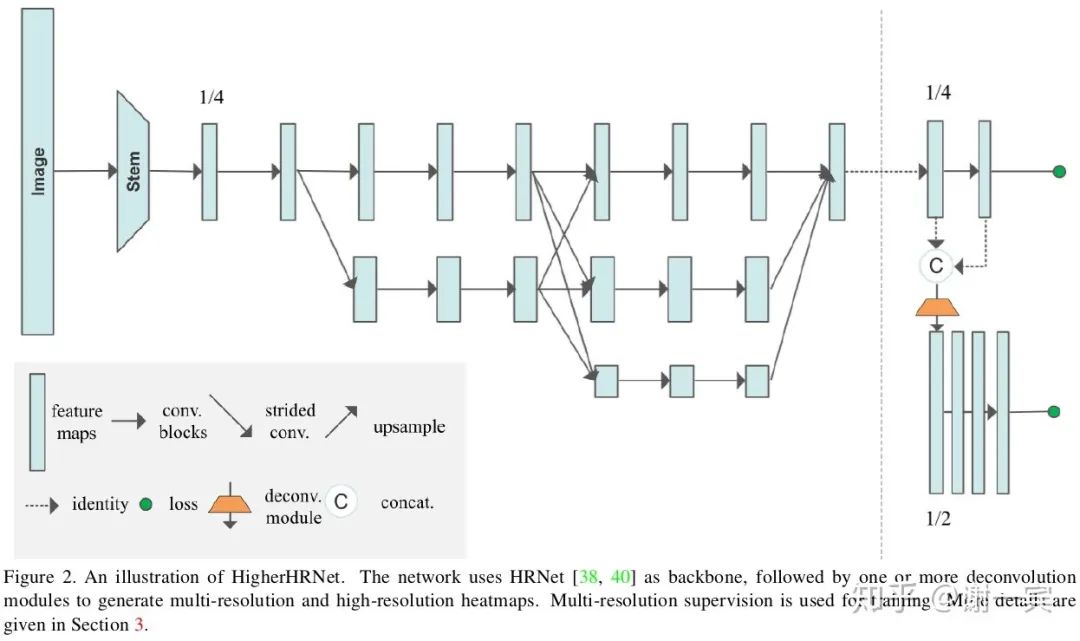
HRNet在bottom-up方法中的尝试,associative embedding加上更强大的网络。
大体的创新点主要集中在网络结构和特征表示两个方面,网络结构是一个填不满的坑,怎么更好的抽取信息,利用信息是网络结构设计的本质。在输出特征的表示方面主要有heatmap和自定义的向量场,人为设计的向量也许可以更好地指引网络训练。人体的关节点不是孤立的,利用好这种先验的肢体关系也可以更好地指导网络训练。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~