
NLP任务非Transformer不可?
机器之心编译
编辑:Panda
在当前 NLP 领域,基于 Transformer 的模型可谓炙手可热,其采用的大规模预训练方法已经为多项自然语言任务的基准带来了实质性的提升,也已经在机器翻译等领域得到了实际应用。但之前却很少有研究者思考:预训练是否也能提升卷积在 NLP 任务上的效果?近日, 资源雄厚的 Google Research 的一项大规模实证研究填补了这一空白。结果发现,在许多 NLP 任务上,预训练卷积模型并不比预训练 Transformer 模型更差。本文将重点关注该研究的实验结果和相关讨论,具体实验设置请参阅论文。

在预训练 - 微调范式下对卷积式 Seq2Seq 模型进行了全面的实证评估。研究者表示,预训练卷积模型的竞争力和重要性仍还是一个仍待解答的问题。
研究者还得出了几项重要观察结果。具体包括:(1)预训练能给卷积模型和 Transformer 带来同等助益;(2)在某些情况下,预训练卷积在模型质量与训练速度方面与预训练 Transformer 相当。
研究者使用 8 个数据集在多个领域的许多任务上执行了广泛的实验。他们发现,在 8 项任务的 7 项上,预训练卷积模型优于当前最佳的 Transformer 模型(包括使用和未使用预训练的版本)。研究者比较了卷积和 Transformer 的速度和操作数(FLOPS),结果发现卷积不仅更快,而且还能更好地扩展用于更长的序列。
RQ1:预训练能否为卷积和 Transformer 带来同等助益?
RQ2:卷积模型(不管是否使用预训练)能否与 Transformer 模型媲美?它们在什么时候表现较好?
RQ3:相比于使用 Transformer 模型,使用预训练卷积模型是否有优势,又有哪些优势?相比于基于自注意力的 Transformer,卷积模型是否更快?
RQ4:预训练卷积不适用于哪些情况?哪些情况需要警惕?原因是什么?
RQ5:是否有某些卷积模型变体优于另一些模型?
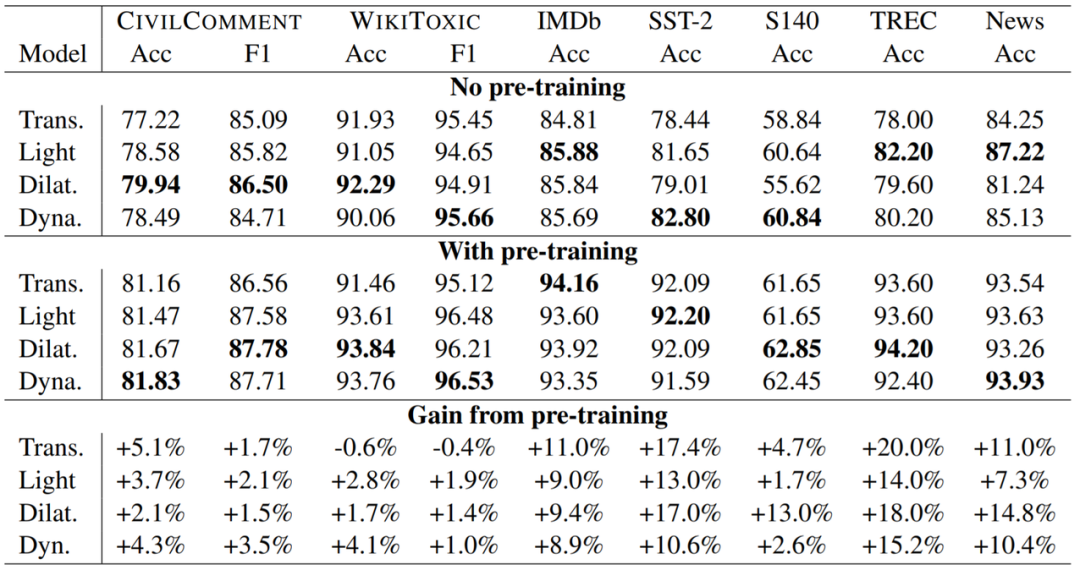
在处理长序列时,卷积速度更快,扩展更好。
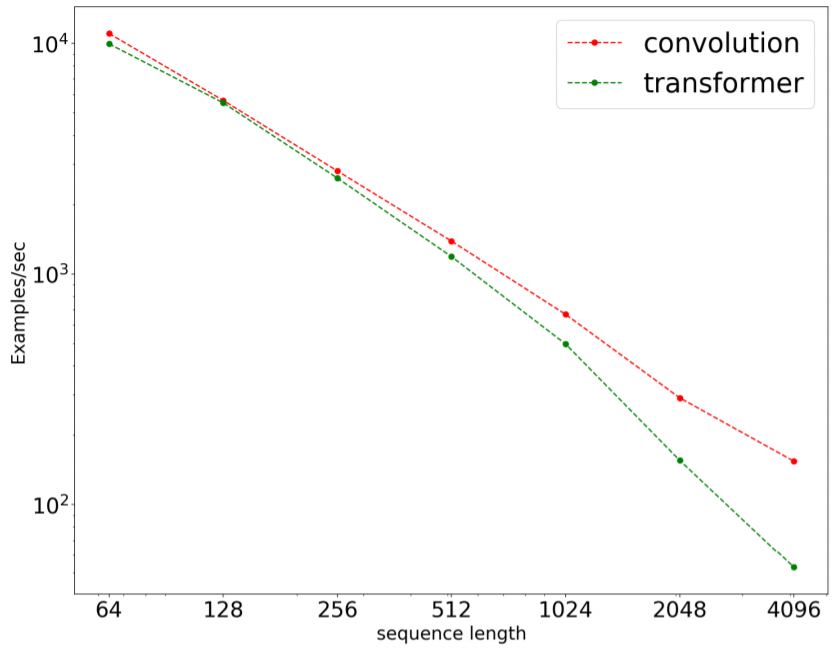
卷积的 FLOPs 效率更高
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论