
我用Python爬取美食网站3032个菜谱并分析,真香!


数据获取
豆果美食网的数据爬取比较简单,如果您对爬虫感兴趣,可查看J哥往期原创文章「实战|手把手教你用Python爬虫(附详细源码)」,思路一致。
 豆果美食网
豆果美食网
本次爬取的数据范围为川菜、粤菜、湘菜等八个中国菜系,包含菜谱名、链接、用料、评分、图片等字段。限于篇幅,仅给出核心代码。
1# 主函数
2def main(x):
3 url = 'https://www.douguo.com/caipu/{}/0/{}'.format(caipu,x*20)
4 print(url)
5 html = get_page(url)
6 parse_page(html,caipu)
7
8if __name__ == '__main__':
9 caipu_list = ['川菜', '湘菜','粤菜','东北菜','鲁菜','浙菜','湖北菜','清真菜'] #中国菜系
10 start = time.time() # 计时
11 for caipu in caipu_list:
12 for i in range(22):
13 # 爬取多页
14 main(x=i)
15 time.sleep(random.uniform(1, 2))
16 print(caipu,"第" + str(i+1) + "页提取完成")
17 end = time.time()
18 print('共用时',round((end - start) / 60, 2), '分钟')爬虫核心代码
数据清洗
导入数据
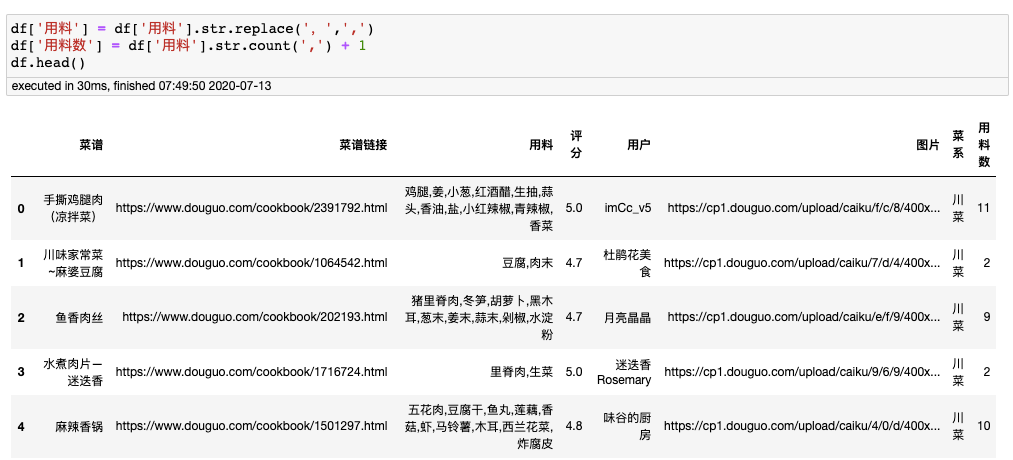
用pd.read方法导入爬取到的菜谱数据,并添加列名。预览数据如下:

删除重复项
爬虫过程中少量菜谱数据被重复抓取,需要用drop_duplicates方法删除。

缺失值处理
通过info方法发现少量记录含有缺失值,用dropna方法删除。

评分字段清洗

添加用料数字段
数据可视化
本文数据可视化主要用到pyecharts库,它能轻松实现酷炫的图表效果。如果您对可视化感兴趣,可查看J哥往期原创文章「数据可视化分析系列」,涉及地产、电商、招聘等各领域。
菜谱评分分布
1from pyecharts import options as opts
2from pyecharts.charts import Page, Pie
3cut = lambda x : '4分以下' if x < 4 else ('4.1-4.5分' if x <= 4.5 else('4.6-4.9分' if x <= 4.9 else '5分'))
4df['评分分布'] = df['评分'].map(cut)
5df2 = df.groupby('评分分布')['评分'].count()
6df2 = df2.sort_values(ascending=False)
7df2 = df2.round(2)
8print(df2)
9c = (
10 Pie()
11 .add(
12 "",
13 [list(z) for z in zip(df2.index.to_list(),df2.to_list())],
14 radius=["20%", "80%"],# 圆环的粗细和大小
15 rosetype='area' #玫瑰图
16 )
17 .set_global_opts(
18 title_opts=opts.TitleOpts(title="菜谱评分分布"
19 ),
20 legend_opts=opts.LegendOpts(
21 orient="vertical", pos_top="5%", pos_left="2%" ,textstyle_opts=opts.TextStyleOpts(font_size=14)# 左面比例尺
22 ),
23
24
25 )
26 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18),
27 )
28 )
29c.render_notebook()
玫瑰图代码
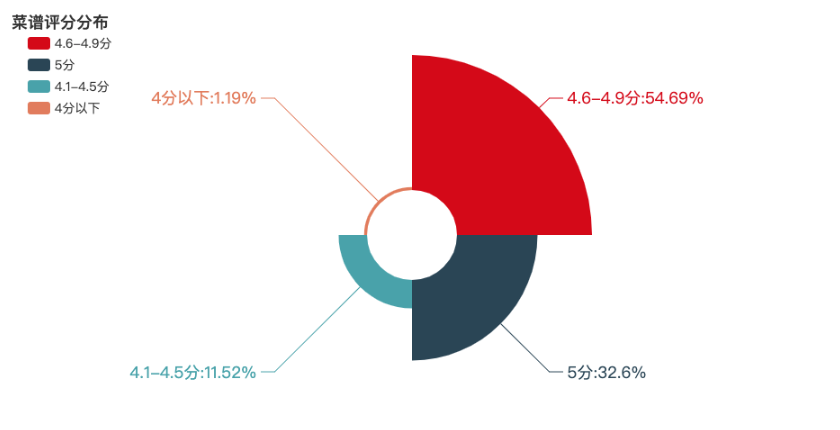
菜谱评分分布玫瑰图
各菜系菜谱数量对比
1from pyecharts import options as opts
2from pyecharts.charts import Page, Pie
3df2 = df.groupby('菜系')['评分'].count() #按菜系分组,对评分计数
4df2 = df2.sort_values(ascending=False) #降序
5print(df2)
6c = (
7 Pie()
8 .add("", [list(z) for z in zip(df2.index.to_list(),df2.to_list())])
9 .set_global_opts(title_opts=opts.TitleOpts(title="各菜系菜谱数量占比",subtitle="数据来源:豆果美食"))
10 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
11 )
12c.render_notebook()
饼图代码
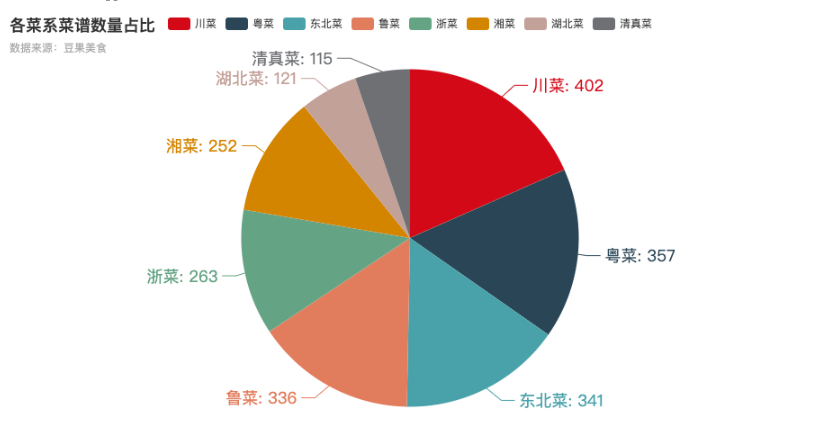
各菜系菜谱数量占比饼图
各菜系评分对比
1from pyecharts import options as opts
2from pyecharts.charts import Page, Pie
3df2 = df.groupby('菜系')['评分'].mean()
4df2 = df2.sort_values(ascending=False)
5df2 = df2.round(2)
6print(df2)
7c = (
8 Pie()
9 .add(
10 "",
11 [list(z) for z in zip(df2.index.to_list(),df2.to_list())],
12 radius=["40%", "75%"], # 圆环的粗细和大小
13 )
14 .set_global_opts(
15 title_opts=opts.TitleOpts(title="各菜系平均评分"),
16 legend_opts=opts.LegendOpts(
17 orient="vertical", pos_top="5%", pos_left="2%" # 左面比例尺
18 ),
19 )
20 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}"))
21 )
22c.render_notebook()
环状图代码
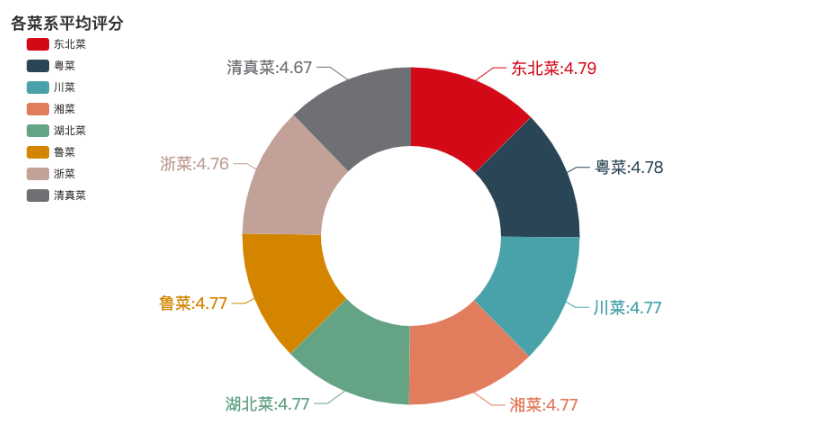
各菜系平均评分环状图
各菜系用料数量对比
1from pyecharts.charts import Bar,Pie
2from pyecharts import options as opts
3df1 = df.groupby('菜系')['用料数'].mean() #按菜系分组,对评分计数
4df1 = df1.sort_values(ascending=False) #降序
5df1 = df1.round(0)
6print(df1)
7bar = Bar()
8bar.add_xaxis(df1.index.to_list())
9bar.add_yaxis("用料数量",df1.to_list())
10bar.set_global_opts(title_opts=opts.TitleOpts(title="各菜系用料数量",subtitle="数据来源:豆果美食"))
11bar.render_notebook()
柱状图代码
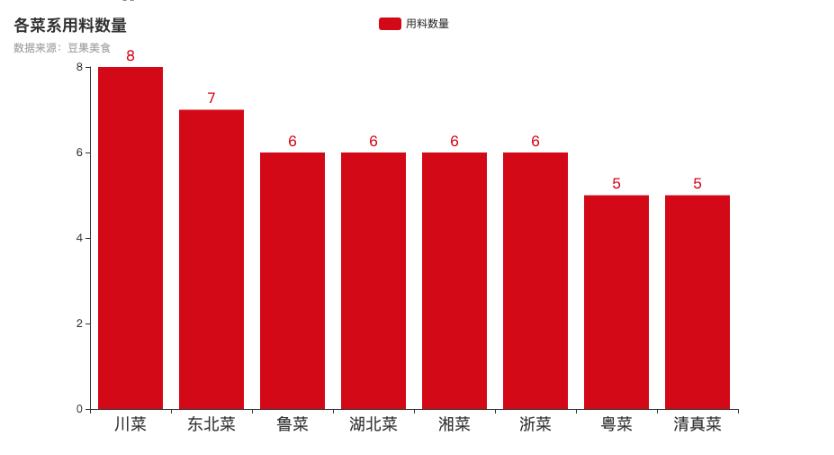
各菜系用料数量柱状图
川菜用料分析
1# 绘制词云图
2text1 = get_cut_words(content_series=df[df['菜系']=='川菜']['用料'])
3stylecloud.gen_stylecloud(text=' '.join(text1), max_words=1000,
4 collocations=False,
5 font_path='字酷堂清楷体.ttf',
6 icon_name='fas fa-thumbs-up',
7 size=653,
8 output_name='./川菜.png')
9Image(filename='./川菜.png')
词云图代码

川菜用料词云图

川味砂锅之足不出户的麻辣烫 图片来源:豆果美食
粤菜用料分析

粤菜用料词云图

广式肠粉 图片来源:豆果美食
湘菜用料词云图

湘菜用料词云图

麻辣卤鸭三件 图片来源:互联网
东北菜用料词云图

东北菜用料词云图

翡翠白菜水饺 图片来源:豆果美食
湖北菜用料词云图

湖北菜用料词云图

家常美味——香菇鸡肉面 图片来源:豆果美食
浙菜用料词云图

浙菜用料词云图

经典糖醋排骨 图片来源:豆果美食
鲁菜用料词云图

鲁菜用料词云图

大白菜炖牛肉 图片来源:豆果美食
清真菜用料词云图

清真菜用料词云图

糖醋蛋白肉 图片来源:豆果美食
声明
1.本数据分析只做学习研究之用途,提供的结论仅供参考,美食的烹饪涉及的影响因素还有很多,请独立思考;
2.作者与豆果美食无任何瓜葛,只是他家数据比较全面且干净,便于数据分析,大家也可以去其他美食平台看看;
3.作者对传统美食文化了解甚微,相关描述可能存在不尽完善之处,请勿对号入座。
公众号后台回复「美食」可自动获取本文所用代码和数据集。