
这一篇和大家聊聊Hadoop
hello大家好 我是大家的学习成长小伙伴Captain

我们作为一个资深的CV工程师,在开发中肯定或多或少的接触过些许大数据的知识,也或多或少的去了解过这些大数据知识,在现在这个数据为王的时代,在现在这个数据量和数据级在日益增长的今天,大数据变得炽手可热
那么什么是大数据呢,以及我们最常听说过的Hadoop、spark、storm、flink各自的优缺点、擅长的方向都是什么呢,以及hive、HBASE这些都是如何基于hdfs存储数据的,如何来分区数据的呢
Hadoop中的hdfs到底是如何支持这么大量的数据存储的,到底是什么结构,如何保证可靠性,而MapReduce又是如何进行协调计算的,yarn是如何进行相应的资源管理的
ZooKeeper是如何为分布式应用进行协调服务的,sqoop是如何把hive和传统的数据库进行数据传递的呢,oozie和azkban都是如何进行任务工作流调度的呢,底层都是如何工作的
flume是如何基于流式结构提供海量的日志采集、聚合和进行传输的呢,而kafka又是如何在众多消息队列中脱颖而出的呢,哦对了,还有我们以前说的rocketmq,这俩到底是啥区别,这俩货的擅长的点都在哪里
等等...
各行各业,都要活到老学到老,就像联盟中的剑圣说过的一句话:真正的大师永远都怀着一颗学徒的心。A true master is an external student
我们这一篇只是对大数据领域的Hadoop进行简单的了解,后续我们会持续对来和大家一起探讨大数据领域的其它技术
什么是大数据
大数据,指的就是大数据的集合,不能使用传统的计算技术来处理,或者说无法在一定时间范围内来进行处理,需要用更新的处理模式才可以更好的这些量很大的数据
那么什么叫大数据,首先应该是数据量大,种类多,增长的很快,价值密度也很低,我们需要用相应的技术来分析处理得出更有价值的数据,就像我们上面说的那些技术,可以合作工作更好的进行数据的处理和分析
数据量大
数据集合的规模的不断扩大,已经将数据从GB增加到TB、PB级别,甚至数据都要以EB和ZB来进行计数
数据时效性
数据量的产生的速度也在持续的加快,人们现在使用网络的频率越来越高,也就是随之产生的数据的速度越来越快,我们更需要根据数据来更快的进行提取和分析,才能保证分析结果的时效性
比如我们需要根据用户的最近的浏览来分析出用户的最近的喜好,来更好的推荐商品,也就是所谓的推荐系统,那么如果这个推荐系统每天会进来大量的数据,但是分析的却很慢,需要运行一周,那这就很糟糕了啊,这分析出来的结果的可信度就很低了,时效性很差了就
数据处理速度变得越来越快,处理模式已经逐渐的从批处理转向了流处理,即时效性越来越强,我们每时每刻都在浏览抖音、淘宝,这些数据都会立刻通过推荐系统,来给大家推荐出大家更想要的结果
当然,很多场景并不需要很好的时效性,可能一周或者一个月都能在接受的范围内,比如统计报表这种,这些就是批处理的强项了
数据多样性
大数据的数据类型繁多,传统的IT行业产生和处理的数据可能通过简单的数据类型处理就可以,大部分都是结构化数据,而随着物联网的越来越深入,各行各业都在引入互联网,产生的数据也更加多样化,需要更多的图片、数据这些非结构化的数据进行存储
于是就有了MongoDB这种存储非结构化的数据的数据库,各种数据层出不穷,也就更需要对这些数据进行分析
数据价值低
由于数据量的不断加大,单位数据的价值密度也就变得更低,然而数据的总体价值还是在增加的,于是我们如何在密度更低的大量数据中提取出那些有用的数据变得尤为重要
了解Hadoop
大家可能或多或少的了解多Hadoop这个技术框架,这个属于大数据领域最主流的一套技术体系了,用Java编写的一个Apache技术开源框架,允许使用简单的编程模型就可以通过计算机集群进行分布式处理大型的数据集合
Hadoop框架的目的在于从单个服务器扩展到数千个服务器,每个都提供者本地计算和本地存储的功能,突出一个集中力量办大事
Hadoop主要包含hdfs分布式文件存储系统、yarn分布式资源调度系统、MapReduce分布式计算系统,这几个家伙都是各有各的本事,每个都身怀绝技,下面我们会对这几个身怀绝技的家伙进行分析一番,看看这些绝技到底是如何炼成的
我们从一个系统开始分析,系统小的时候,使用数据库mysql和MongoDB就没问题,mysql存储结构化数据,MongoDB存储非结构化数据,然后使用redis进行数据的缓存增加系统的速度和性能
我们假设使用的mysql服务器的磁盘可以存储1TB的数据,但是我们不能保证数据量一直在1TB之内啊
随着系统的业务越来越大,1TB的数据库已经完全不够数据的存储了,咋办,加机器,分库分表,每个服务器放一部分数据
分库分表也就随之带来了更多的问题,比如我们需要保证保证数据能够准确的找到相应的机器,也能够准确的存储到相应的机器上,一般由垂直切分和水平切分两种思路
再比如涉及到跨表的join的问题,因为基于架构规范和安全性这些考虑,一般是禁止跨库join这种的,可以采用全局表和字段冗余的方式解决,全局表就是将一些系统中几乎所有模块都可能依赖的一些表,让每个机器都存储一份,这样就可以很好的避免跨库join。字段冗余就是把相同的字段多存储几份咯,总的来说思路就是用空间换时间的一种思想
岔劈了,分库分表可以用来解决一些必要数据的存储,但是比如一些无关紧要的数据,但是又有一些提取的价值,比如用户在某电商网站在APP或者网站的点击、购买和浏览的行为日志,这些肯定是没必要全部存储到mysql的,我们需要保存的是经过推荐系统分析之后的数据,而这些日常的行为数据没必要去全量保存到mysql中的
没必要保存到mysql并不意味着不需要保存,Hadoop中的hdfs就是干这个的,负责把这些大量的数据保存起来,只需要在机器上部署上Hadoop服务即可,机器是很廉价的,后续这种数据直接加机器就可以了
某天leader来了,要看一个报表,如果这些"脏数据"全部存储到mysql中,可能需要写一个几百行甚至上千行的SQL才能拿到结果,几百行的SQL直接执行在分库分表的架构上,这就有点扯了
更何况,mysql还存储了大量的无用数据,我们需要让专业的人办专业的事
于是各种处理这种数据量极其大的各种技术应运而生,大数据分析就涉及到实时性这个特点,我们上面也说过了
实时性要求不高的可以用批处理进行稍微较慢的处理,而实时性要求较高的场景则需要用流式处理来进行分析,达到一种几乎实时的效果
说说主角Hadoop
Hadoop分为四个模块,common、hdfs、yarn、MapReduce这四个

common:Hadoop模块需要的Java库和实用程序,这些库等同于是实现各种功能的地基
hdfs:分布式文件存储系统,像文件夹一样存储,数据在hdfs中就像存储在本地磁盘上一样,而实际上文件会被切分成很多的小块,然后分布到各个机器中
yarn:作业调度和集群资源管理的一个框架
MapReduce:用于并行处理大数据的计算系统,可分为map和reduce两个重要任务来协作完成数据的处理
Hadoop特点
高扩容能力,支持超大的文件,能够支持存储和处理超大数据量
成本低,只需要购买普通的机器部署Hadoop服务,组成Hadoop集群即可进行存储和处理数据,服务群可达数千个节点
高效率,通过多个机器进行分布式处理,可以让性能更好的服务器并行地处理数据,然后把处理结果进行合并即可,而且Hadoop可以在节点之间动态的移动弄个数据,保证各个节点之间的动态平衡
可靠性,大文件的数据的存储会被切分成多个数据块分别存储到不同的机器上,而每个数据块存储都不支一块,且多块不会存储在同一个机器上,保证了数据的高可靠性
Hadoop更适合于那种写一次,读多次的业务场景,Hadoop是不支持数据级别的修改的,只支持到文件级别的操作
我们在使用Hadoop的过程中的感觉其实也是像在操作一个云上的电脑磁盘,也提供了丰富的API供我们直接使用
适合场景
大规模数据
流式数据,然后写一次读多次的场景
商用的普通硬件即可
不适合场景
低延时的业务场景
大量的小文件数据
频繁的修改数据
总之,Hadoop很强,但是并不是适合所有的业务场景,再时髦的技术都是随着业务诞生的,脱离了业务的技术就像是没了灵魂的躯壳,是没有意义滴
接下来我们看Hadoop其中的部分组件是如何各显神通的
HDFS
hdfs是啥
hdfs这个的神通就是能够完成巨大数据量的存储功能
只需要加机器就可以完成更多的数据存储
对外提供文件目录,我们只需要用对外开放的API直接像操作文件夹是的操作即可
hdfs就像是一个适配器,底层多个硬盘空间,累加到一起,然后对外就是一个/usr/tmp/captain.mp4这样的文件访问目录
hdfs内部原理
hdfs就是一个文件系统,用于存储文件,通过目录树来定位文件,它是属于一个分布式的,由很多服务器联合起来来实现相应的功能
hdfs的设计适合的是一次写入,多次读出的场景,并且不支持文件的修改,只支持文件级别的修改,就是可以对文件整体进行操作
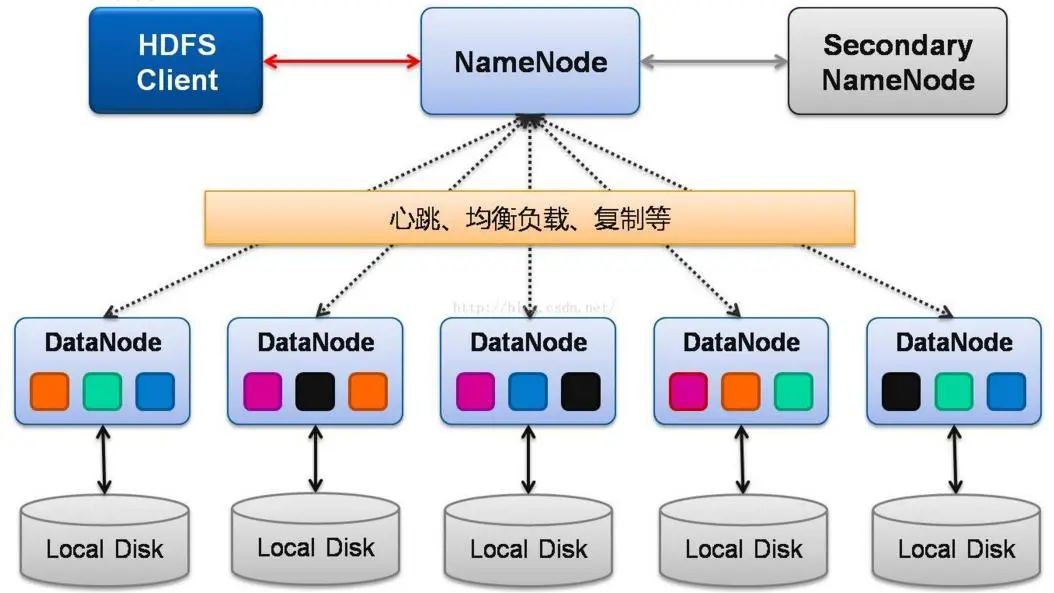
hdfs的角色
NameNode:负责处理client的请求、元数据管理等功能
DataNode:主要用来存储文件块,并且向NameNode汇报存储信息
Client:客户端,和NameNode、DateNode进行交互的
SecondaryNamenode:分担NameNode的压力,但是并不能替代,主要是进行元数据的合并
切记,SecondaryNamenode是不能替代NameNode的,这一点不像是平时那种主从架构,主挂了,从可以升为从的那种,很多小伙伴可能会混淆
Client
上传文件,向NameNode发送写请求
进行数据的切块,默认128M一块
读取文件,向NameNode发送读取请求
NameNode
接收客户端的读写请求,进行数据库元数据位置的存储
分配数据块的存储节点
接收DataNode的数据汇报,因为数据是存储到DataNode的,但是它也就是个存数据的,至于它存储哪些都需要NameNode进行管理,并未要汇报给NameNode
DataNode
真正的数据存储,每个数据块存储的还不止一份,默认每个块是存储3份
真正的处理用户的读写请求的,就是真正干活的,拿出数据来的
向NameNode发送心跳和汇报相应的数据块的存储信息
SecondaryNamenode
备份NameNode的元数据信息
帮助NameNode进行元数据的合并,减轻NameNode的压力
hdfs的优点
高容错性:默认会存储三份备份数据,增加容错性,副本丢失,可以自动恢复
适合大数据处理:可以通过增加机器的方式来进行更高级别数据的存储的处理
hdfs缺点
不适合低延时数据的访问,毫秒级别的存储数据是做不到的
不擅长处理大量小文件,无法对大量小文件进行存储
不支持多线程写入文件
shell操作示例
//基本语法bin/hadoop fs 具体命令//查看指定目录下内容hadoop fs –ls [文件目录]//显示文件内容hadoop dfs –cat [file_path]//将本地文件存储至hadoophadoop fs –put [本地地址] [hadoop目录]//将hadoop上某个文件down至本地已有目录下hadoop fs -get [文件目录] [本地目录]//删除hadoop上指定文件或文件夹hadoop fs –rm [文件地址]//删除hadoop上指定文件夹(包含子目录等hadoop fs –rm [目录地址]//在hadoop指定目录内创建新目录hadoop fs –mkdir /user/t//在hadoop指定目录下新建一个空文件hadoop fs -touchz /user/new.txt//将hadoop上某个文件重命名hadoop fs –mv /user/test.txt /user/ok.txt (将test.txt重命名为ok.txt)//将hadoop指定目录下所有内容保存为一个文件,同时down至本地hadoop fs –getmerge /user /home/t//将正在运行的hadoop作业kill掉hadoop job –kill [job-id]//输出这个命令参数hadoop fs -help rm//从本地剪切粘贴到HDFShadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo//追加一个文件到已经存在的文件末尾hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt//Linux文件系统中的用法一样,修改文件所属权限hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt//从本地文件系统中拷贝文件到HDFS路径去hadoop fs -copyFromLocal README.txt ///从HDFS拷贝到本地hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt .///从HDFS的一个路径拷贝到HDFS的另一个路径hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt//显示一个文件的末尾hadoop fs -tail /sanguo/shuguo/kongming.txt//删除空目录hadoop fs -rmdir /test//设置HDFS中文件的副本数量hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
Java的API操作示例
//HDFS文件上传public void testPut() throws Exception {Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop102:9000"),configuration,"drift");fileSystem.copyFromLocalFile(new Path("f:/hello.txt"), new Path("/0308_666/hello1.txt"));fileSystem.close();}//HDFS文件下载public void testDownload() throws Exception {// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "drift");// 2 执行下载操作fileSystem.copyToLocalFile(false,new Path("/0308_666/hello.txt"),new Path("f:/hello1.txt"),true);// 3 关闭资源fileSystem.close();System.out.println("over");}//HDFS文件夹删除public void delete() throws Exception {// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "drift");// 2 执行删除操作fileSystem.delete(new Path("/0308_777"), true);// 3 关闭资源fileSystem.close();System.out.println("over");}//HDFS文件夹名更改public void testRename() throws Exception {// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "drift");// 2 执行重命名操作fileSystem.rename(new Path("/0308_666/hello.txt"), new Path("/0308_666/hello2.txt"));// 3 关闭资源fileSystem.close();System.out.println("over");}//HDFS文件详情查看public void testLS1() throws Exception {// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "drift");// 2 查询文件信息RemoteIteratorlistFiles = fileSystem.listFiles(new Path("/"), true); while (listFiles.hasNext()) {LocatedFileStatus fileStatus = listFiles.next();// 文件的长度System.out.println(fileStatus.getLen());// 文件的名字System.out.println(fileStatus.getPath().getName());// 文件的权限System.out.println(fileStatus.getPermission());BlockLocation[] locations = fileStatus.getBlockLocations();for (BlockLocation location : locations) {String[] hosts = location.getHosts();for (String host : hosts) {System.out.println(host);}}System.out.println("---------------分割线---------------");}// 3 关闭资源fileSystem.close();}//HDFS文件和文件夹判断public void testLS2() throws Exception {// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "drift");// 2 文件和文件夹的判断FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));for (FileStatus fileStatus : fileStatuses) {if (fileStatus.isFile()) {System.out.println("F:" + fileStatus.getPath().getName());} else {System.out.println("D:" + fileStatus.getPath().getName());}}// 3 关闭资源fileSystem.close();}
Yarn
yarn是什么
yarn属于Hadoop的资源管理系统,基本设计思路是分为一个全局的资源管理器ResourceManager和每个应用程序持有的ApplicationMaster,还有一个节点的资源管理器NodeManager
yarn组成结构
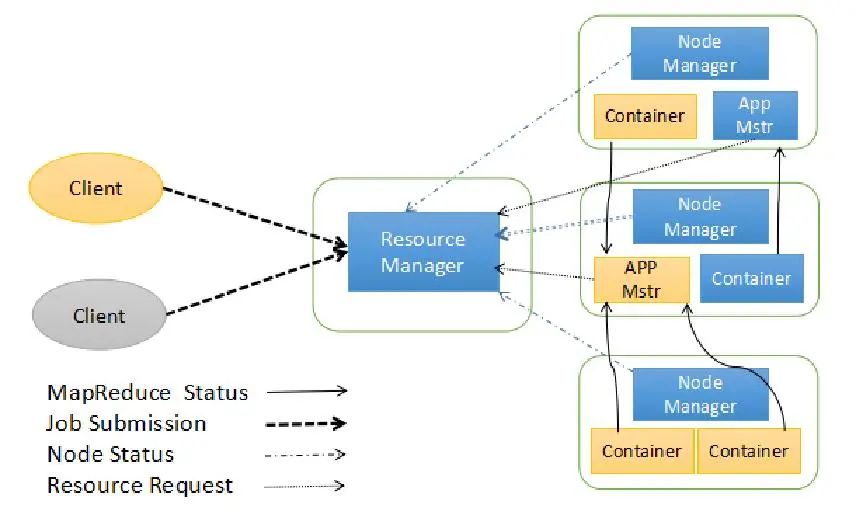
YARN总体上仍然是Master/Slave结构
在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度
当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响
ResourceManager
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器和应用程序管理器
调度器
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序
该调度器是一个纯调度器,它不再从事任何与具体应用程序相关的工作,这些工作均交给应用程序相关的ApplicationMaster
调度器仅根据各个应用程序的资源需求进行资源分配,该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等
应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等
ApplicationMaster
用户提交的每个应用程序均包含一个AM,与RM调度器协商以获取资源(用Container表示),将得到的任务进一步分配给内部的任务
与NM通信以启动/停止任务
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
NodeManager
NM是每个节点上的资源和任务管理器
一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态
另一方面,它接收并处理来自AM的Container启动/停止等各种请求
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的
YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源
MapReduce
什么是MapReduce
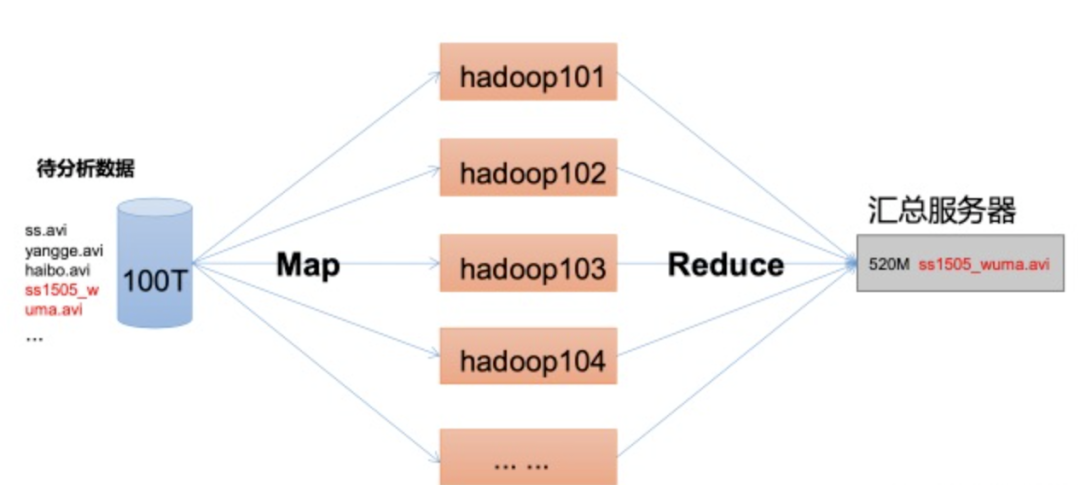
MapReduce是一个分布式运算程序的编程框架,是用户开发基于hadoop的数据分析应用的核心框架
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上
海量数据在单机上处理因为硬件资源限制,无法胜任,引入mapreduce框架后,可以很好的处理多个机器的资源来进行计算,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理。
mapreduce就是这样一个分布式程序的通用框架
优点
MapReduce 易于编程:简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行
良好的扩展性:当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力
高容错性:其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的
适合PB级以上海量数据的离线处理:可以实现上千台服务器集群并发工作,提供数据处理能力
缺点
不擅长实时计算:MapReduce无法像Mysql一样,在毫秒或者秒级内返回结果
不擅长流式计算:流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的
Hadoop中的数据压缩
压缩技术能够有效减少底层存储系统(HDFS)读写字节数。压缩提高了网络带宽和磁盘空间的效率
在Hadoop下,尤其是数据规模很大和工作负载密集的情况下,使用数据压缩显得非常重要。在这种情况下,I/O操作和网络数据传输要花大量的时间
鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助,如果磁盘I/O和网络带宽影响了MapReduce作业性能,在任意MapReduce阶段启用压缩都可以改善端到端处理时间并减少I/O和网络流量
压缩Mapreduce的一种优化策略:通过压缩编码对Mapper或者Reducer的输出进行压缩,以减少磁盘IO,提高MR程序运行速度(但相应增加了cpu运算负担)
注意:采用压缩技术减少了磁盘IO,但同时增加了CPU运算负担。所以,压缩特性运用得当能提高性能,但运用不当也可能降低性能

运算密集型的job,少用压缩
IO密集型的job,多用压缩
结束语
感谢大家能够做我最初的读者和传播者,请大家相信,只要你给我一份爱,我终究会还你们一页情的。
Captain会持续更新技术文章,和生活中的暴躁文章,欢迎大家关注【Java贼船】,成为船长的学习小伙伴,和船长一起乘千里风、破万里浪
哦对了,后续所有的文章都会更新到这里
https://github.com/DayuMM2021/Java
