
南瓜电影 7 天内全面 Serverless 化实践
作者 | 庄徐麟

从我们了解 SAE 产品到整体上线一共是 7 天时间。3 天完成核心应用 API 网关上线,第 5 天验证结束 100% 流量打到 SAE 上,第 6-7 天把其余 30 多个系统快速迁移到 SAE,整个过程非常顺利。使用 SAE 后,运维效率提升 70%,成本下降超过 40%,扩容效率提升 10 倍以上,这是给我们带来的直观改变 。
—南瓜电影 CTO 庄徐麟
南瓜电影成立于 2015 年,是国内近两年发展非常迅速的流媒体平台,凭借着无广告、纯付费的商业模式,在影迷圈中打响了一定的知名度;之后又靠着很强的社区互动性(AI 智能推荐、影评互动、通过放映厅实现线上“云观影”等),迅速完成会员增长及流媒体市场占位;接下来将逐渐往多元化视频平台发展:如纪录片、各类自制节目等。
痛点
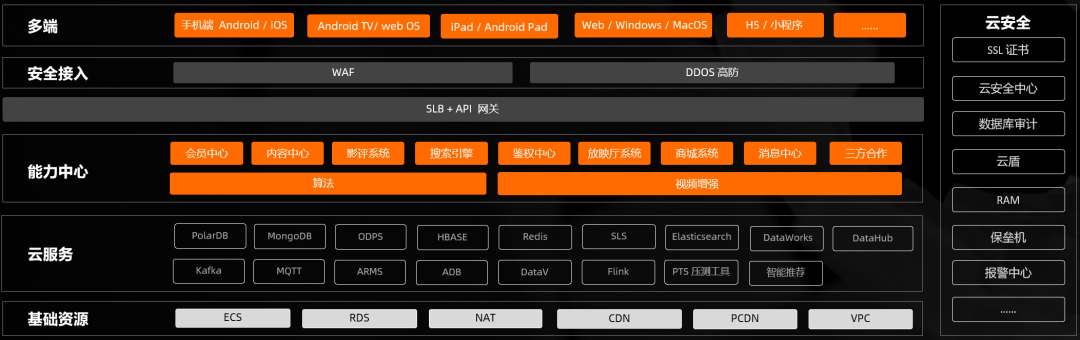
相信会有很多企业也面临和我们一样的难题,同时也制约着公司的发展。但开发人员都存在一定的惰性,认为只要不出事就先继续耗着。而真正让我们下定决心做技术升级的,还得感谢 19 年的那场热映电影。

选型
针对以上的问题,我们在想下一步应该怎么改造,当时内部有两个方案,但都存在一些弊端:


实战
ROUND 1:CI/CD Pipeline – 加速迭代效率

ROUND 2:上线第一个应用 API 网关
接下来就是挑选第一个应用实战了。当时我们做了一个大胆的决定:首先迁移 API 网关。API 网关是我们内部最核心的应用也是压力最大的应用,为什么这么选择呢?
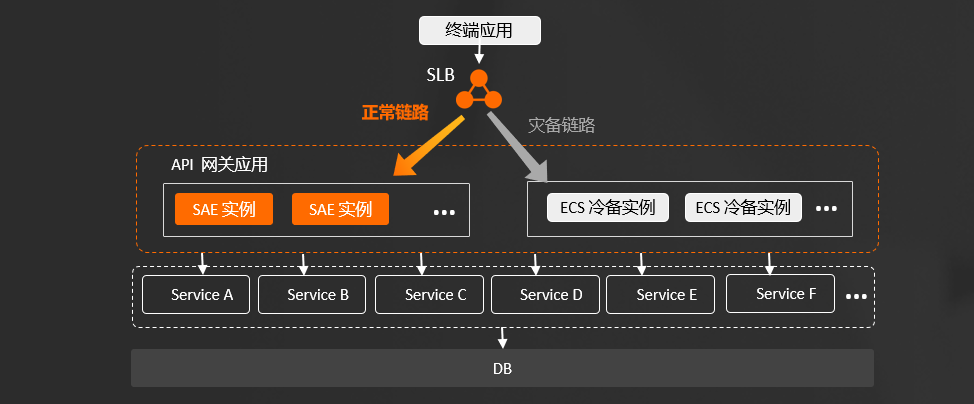
ROUND 3:API 网关自动扩缩,应对突增流量
光在常态流量下能稳定运行还不能证明 SAE 是靠谱的。于是我们先后在测试、生产环境重点验证了流量突增时,SAE 的弹性能力。

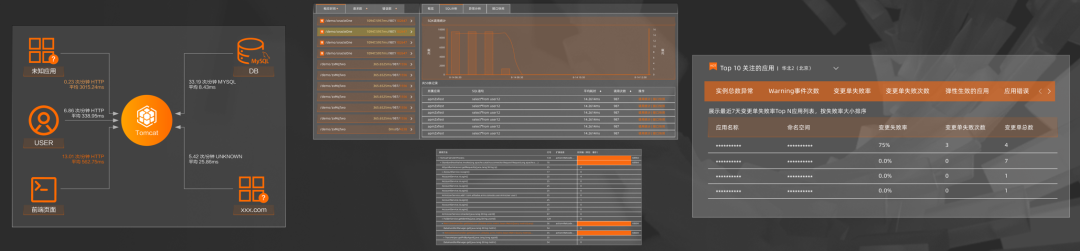
ROUND 4:开箱即用全链路监控&诊断能力
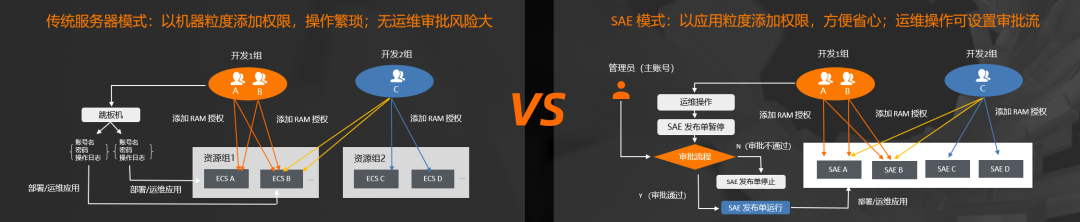
ROUND 5:【企业级特性】权限隔离&审批
ROUND 6:落地完成

总结&期待
最后,我们把使用过程中的一些总结、踩过的坑分享给大家。

南瓜电影也会一如既往地为广大影迷朋友们带来最优质的影片资源和最极致的观影体验,为社会创造更多的正能量。也祝愿阿里云敢梦想敢创新再创佳绩,服务全球更多的企业!

社区网址

Serverless Devs
Serverless Devs 2.0 全新发布,让应用开发更简单
 戳原文查看 SAE 详情!
戳原文查看 SAE 详情!