
Pandas 骚操作:如何将运行内存占用降低 90%!
来源:机器之心

import pandas as pd
gl = pd.read_csv('game_logs.csv')
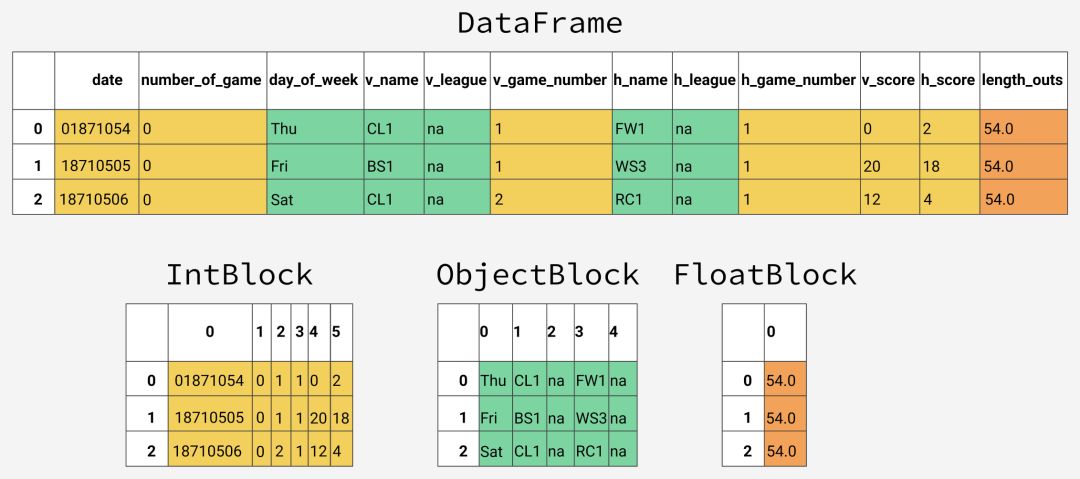
gl.head()
date - 比赛时间
v_name - 客队名
v_league - 客队联盟
h_name - 主队名
h_league - 主队联盟
v_score - 客队得分
h_score - 主队得分
v_line_score - 客队每局得分排列,例如:010000(10)00.
h_line_score - 主队每局得分排列,例如:010000(10)0X.
park_id - 比赛举办的球场名
attendance- 比赛观众
gl.info(memory_usage='deep')
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 171907 entries, 0 to 171906
Columns: 161 entries, date to acquisition_info
dtypes: float64(77), int64(6), object(78)
memory usage: 861.6 MB
for dtype in ['float','int','object']:
selected_dtype = gl.select_dtypes(include=[dtype])
mean_usage_b = selected_dtype.memory_usage(deep=True).mean()
mean_usage_mb = mean_usage_b / 1024 ** 2
print("Average memory usage for {} columns: {:03.2f} MB".format(dtype,mean_usage_mb))
Average memory usage for float columns: 1.29 MB
Average memory usage for int columns: 1.12 MB
Average memory usage for object columns: 9.53 MB
import numpy as np
int_types = ["uint8", "int8", "int16"]
for it in int_types:
print(np.iinfo(it))
Machine parameters for uint8
---------------------------------------------------------------
min = 0
max = 255
---------------------------------------------------------------
Machine parameters for int8
---------------------------------------------------------------
min = -128
max = 127
---------------------------------------------------------------
Machine parameters for int16
---------------------------------------------------------------
min = -32768
max = 32767
---------------------------------------------------------------
# We're going to be calculating memory usage a lot,
# so we'll create a function to save us some time!
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else: # we assume if not a df it's a series
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b / 1024 ** 2 # convert bytes to megabytes
return "{:03.2f} MB".format(usage_mb)
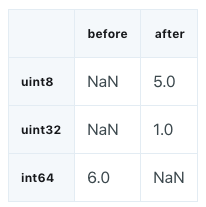
gl_int = gl.select_dtypes(include=['int'])
converted_int = gl_int.apply(pd.to_numeric,downcast='unsigned')
print(mem_usage(gl_int))
print(mem_usage(converted_int))
compare_ints = pd.concat([gl_int.dtypes,converted_int.dtypes],axis=1)
compare_ints.columns = ['before','after']
compare_ints.apply(pd.Series.value_counts)
7.87 MB
1.48 MB
gl_float = gl.select_dtypes(include=['float'])
converted_float = gl_float.apply(pd.to_numeric,downcast='float')
print(mem_usage(gl_float))
print(mem_usage(converted_float))
compare_floats = pd.concat([gl_float.dtypes,converted_float.dtypes],axis=1)
compare_floats.columns = ['before','after']
compare_floats.apply(pd.Series.value_counts)
100.99 MB
50.49 MB

optimized_gl = gl.copy()
optimized_gl[converted_int.columns] = converted_int
optimized_gl[converted_float.columns] = converted_float
print(mem_usage(gl))
print(mem_usage(optimized_gl))
861.57 MB
804.69 MB
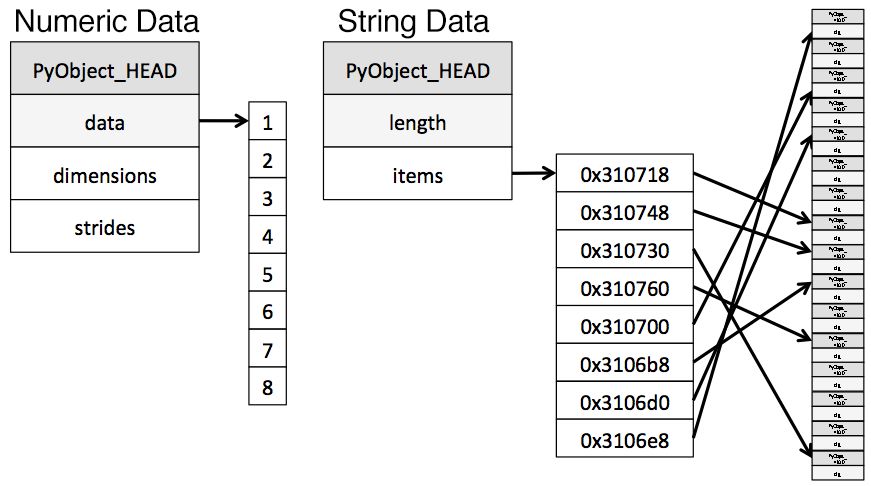
from sys import getsizeof
s1 = 'working out'
s2 = 'memory usage for'
s3 = 'strings in python is fun!'
s4 = 'strings in python is fun!'
for s in [s1, s2, s3, s4]:
print(getsizeof(s))
60
65
74
74
obj_series = pd.Series(['working out',
'memory usage for',
'strings in python is fun!',
'strings in python is fun!'])
obj_series.apply(getsizeof)
0 60
1 65
2 74
3 74
dtype: int64
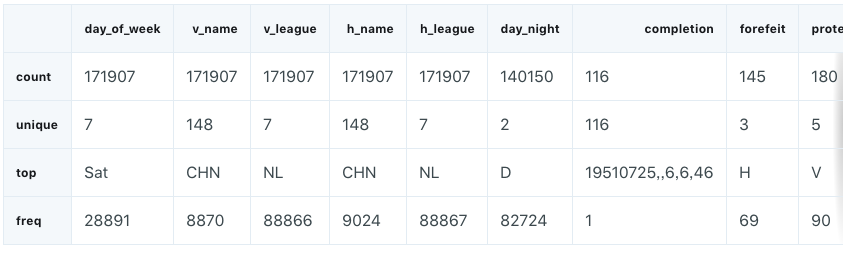
gl_obj = gl.select_dtypes(include=['object']).copy()
gl_obj.describe()
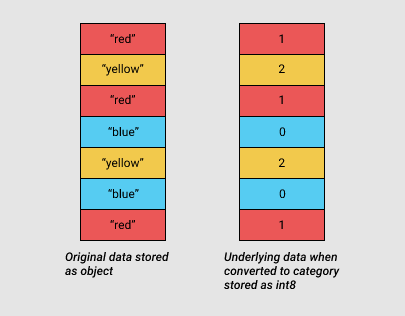
dow = gl_obj.day_of_week
print(dow.head())
dow_cat = dow.astype('category')
print(dow_cat.head())
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: object
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: category
Categories (7, object): [Fri, Mon, Sat, Sun, Thu, Tue, Wed]
dow_cat.head().cat.codes
0 4
1 0
2 2
3 1
4 5
dtype: int8
print(mem_usage(dow))
print(mem_usage(dow_cat))
9.84 MB
0.16 MB
converted_obj = pd.DataFrame()
for col in gl_obj.columns:
num_unique_values = len(gl_obj[col].unique())
num_total_values = len(gl_obj[col])
if num_unique_values / num_total_values < 0.5:
converted_obj.loc[:,col] = gl_obj[col].astype('category')
else:
converted_obj.loc[:,col] = gl_obj[col]
print(mem_usage(gl_obj))
print(mem_usage(converted_obj))
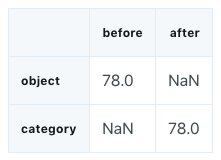
compare_obj = pd.concat([gl_obj.dtypes,converted_obj.dtypes],axis=1)
compare_obj.columns = ['before','after']
compare_obj.apply(pd.Series.value_counts)
752.72 MB
51.67 MB
optimized_gl[converted_obj.columns] = converted_obj
mem_usage(optimized_gl)
'103.64 MB'
date = optimized_gl.date
print(mem_usage(date))
date.head()
0.66 MB
0 18710504
1 18710505
2 18710506
3 18710508
4 18710509
Name: date, dtype: uint32
optimized_gl['date'] = pd.to_datetime(date,format='%Y%m%d')
print(mem_usage(optimized_gl))
optimized_gl.date.head()
104.29 MB
0 1871-05-04
1 1871-05-05
2 1871-05-06
3 1871-05-08
4 1871-05-09
Name: date, dtype: datetime64[ns]
在读入数据的同时选择类型
dtypes = optimized_gl.drop('date',axis=1).dtypes
dtypes_col = dtypes.index
dtypes_type = [i.name for i in dtypes.values]
column_types = dict(zip(dtypes_col, dtypes_type))
# rather than print all 161 items, we'll
# sample 10 key/value pairs from the dict
# and print it nicely using prettyprint
preview = first2pairs = {key:value for key,value in list(column_types.items())[:10]}
import pprint
pp = pp = pprint.PrettyPrinter(indent=4)
pp.pprint(preview)
{ 'acquisition_info': 'category',
'h_caught_stealing': 'float32',
'h_player_1_name': 'category',
'h_player_9_name': 'category',
'v_assists': 'float32',
'v_first_catcher_interference': 'float32',
'v_grounded_into_double': 'float32',
'v_player_1_id': 'category',
'v_player_3_id': 'category',
'v_player_5_id': 'category'}
read_and_optimized = pd.read_csv('game_logs.csv',dtype=column_types,parse_dates=['date'],infer_datetime_format=True)
print(mem_usage(read_and_optimized))
read_and_optimized.head()
104.28 MB
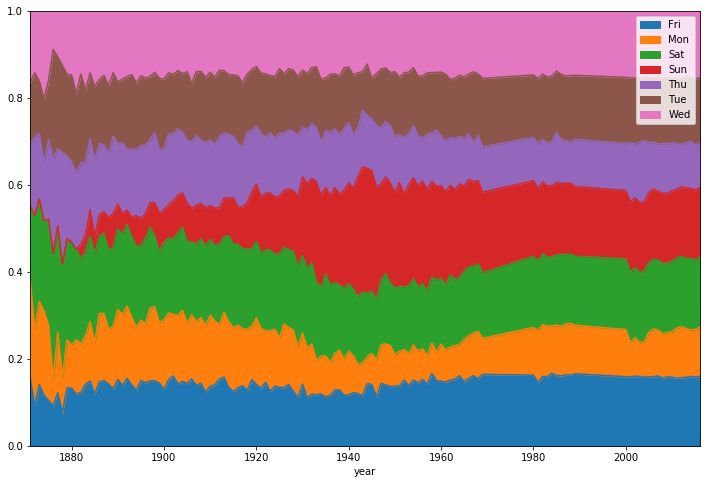
optimized_gl['year'] = optimized_gl.date.dt.year
games_per_day = optimized_gl.pivot_table(index='year',columns='day_of_week',values='date',aggfunc=len)
games_per_day = games_per_day.divide(games_per_day.sum(axis=1),axis=0)
ax = games_per_day.plot(kind='area',stacked='true')
ax.legend(loc='upper right')
ax.set_ylim(0,1)
plt.show()
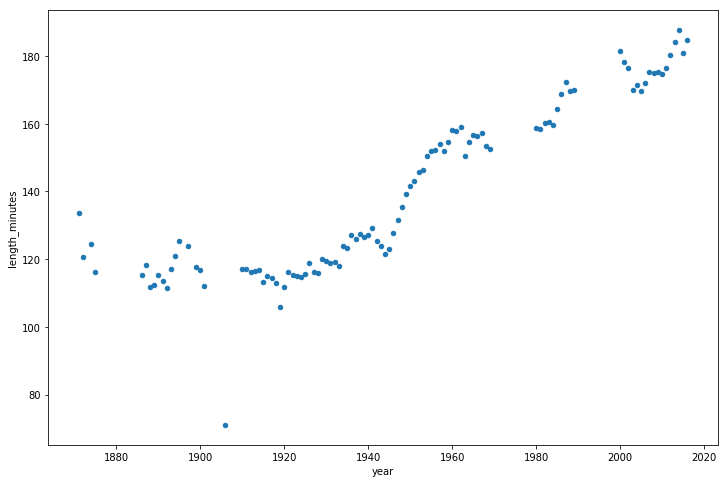
game_lengths = optimized_gl.pivot_table(index='year', values='length_minutes')
game_lengths.reset_index().plot.scatter('year','length_minutes')
plt.show()
将数值列向下转换成更高效的类型
将字符串列转换成 categorical 类型
--END--
扫码即可加我微信
老表朋友圈经常有赠书/红包福利活动
新玩法,以后每篇技术文章,点赞超过100+,我将在个人视频号直播带大家一起进行项目实战复现,快嘎嘎点赞吧!!!
大家的 点赞、留言、转发是对号主的最大支持。
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了 优秀的读者都知道,“点赞”传统美德不能丢
评论