
图解 | 深度学习:小白看得懂的BERT原理

来源:计算机视觉与机器学习 作者丨Jay Alammar
链接丨https://jalammar.github.io/illustrated-bert/
本文约4600字,建议阅读8分钟
本文中,我们将研究BERT模型,理解它的工作原理,对于其他领域的同学也具有很大的参考价值。
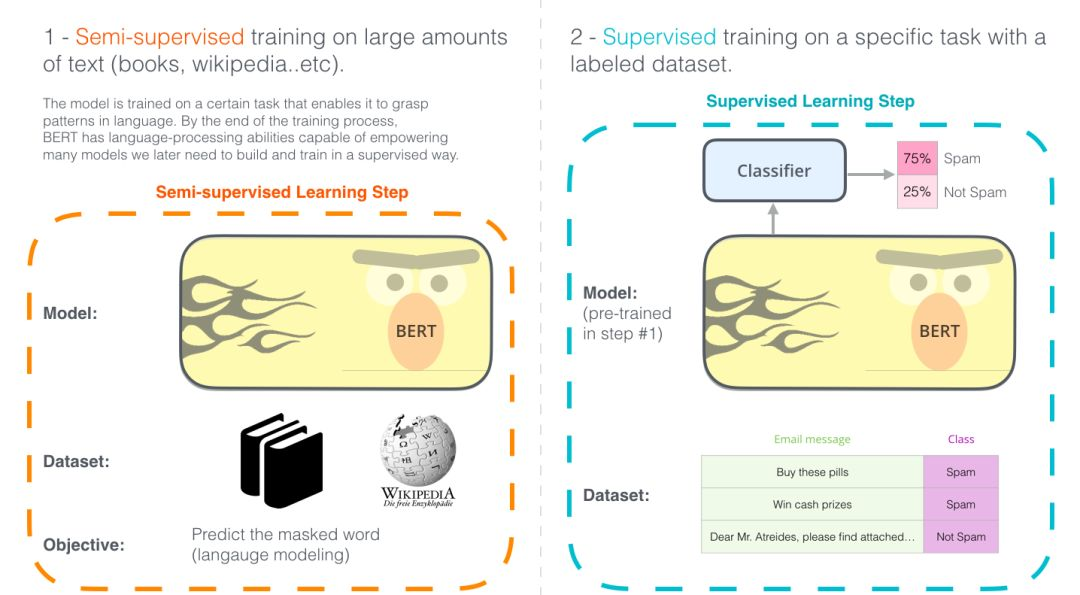
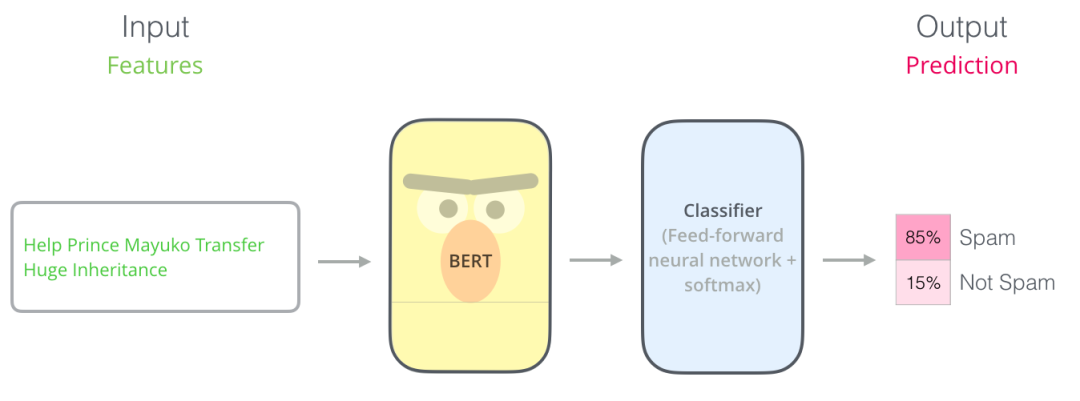
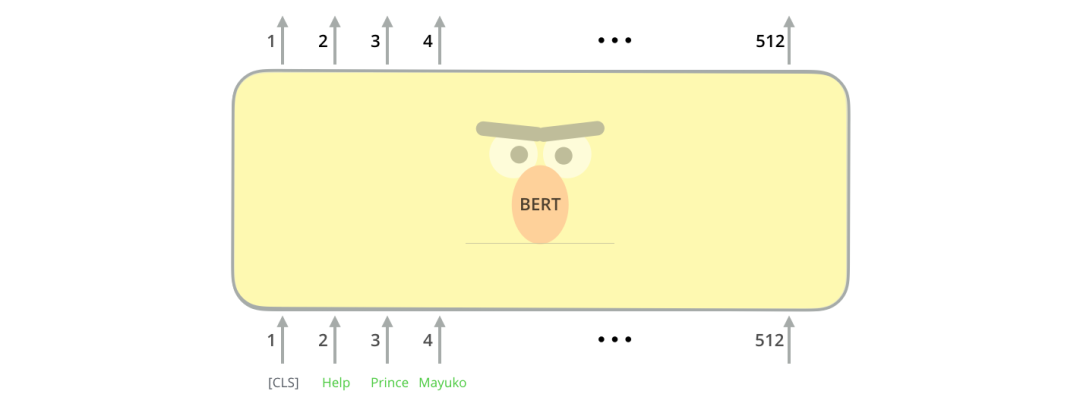
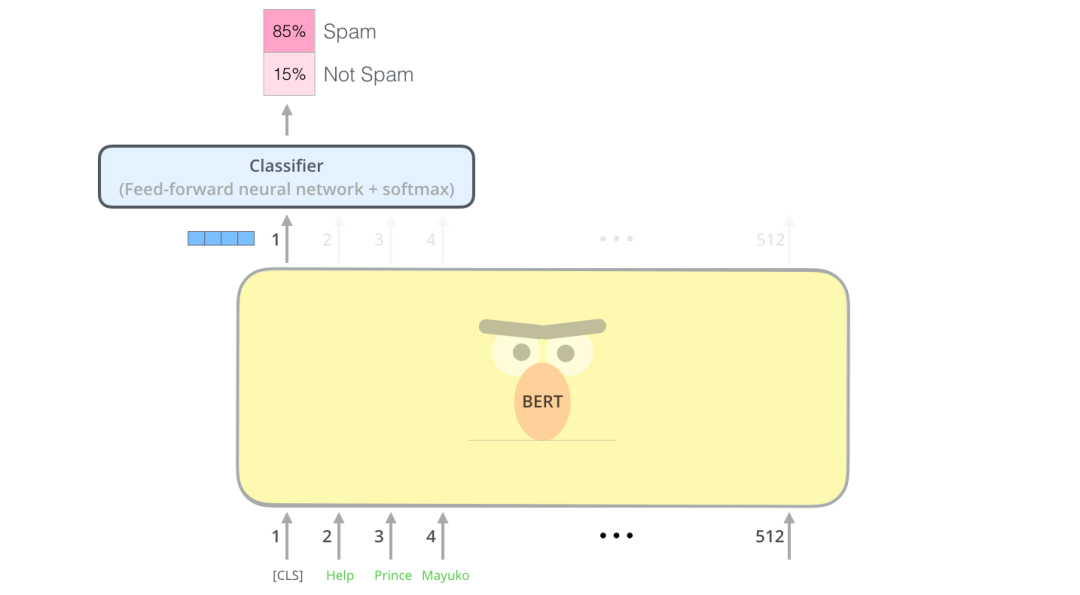
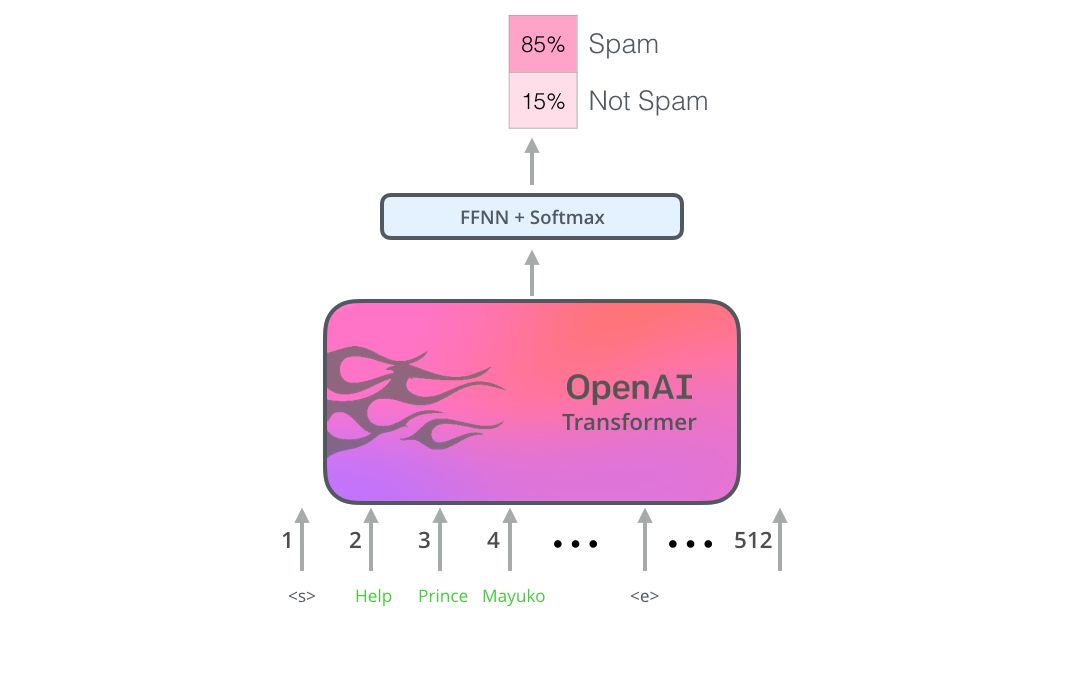
使用BERT最简单的方法就是做一个文本分类模型,这样的模型结构如下图所示:

示例数据集:SST
事实查证
输入:句子。输出:“索赔”或“不索赔”
更雄心勃勃/未来主义的例子:
输入:句子。输出:“真”或“假”

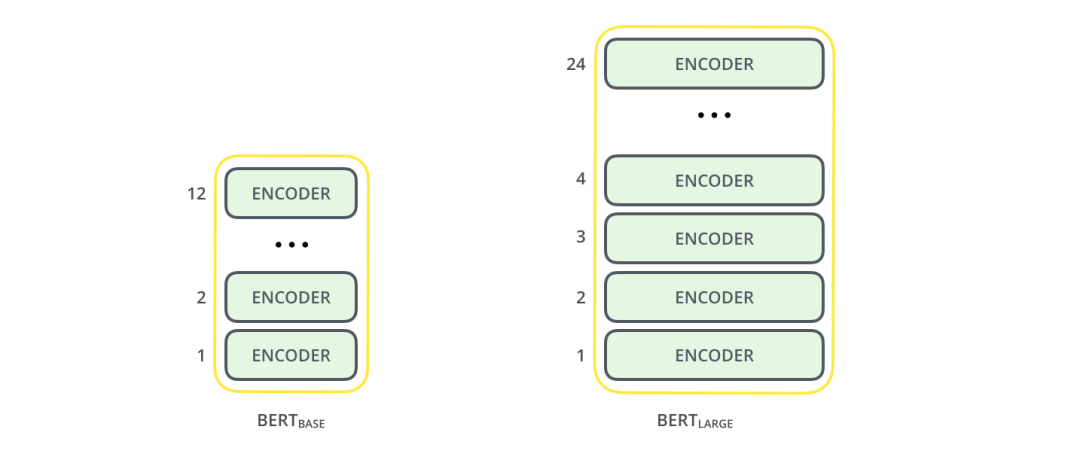
BERT BASE - 与OpenAI Transformer的尺寸相当,以便比较性能 BERT LARGE - 一个非常庞大的模型,它完成了本文介绍的最先进的结果。
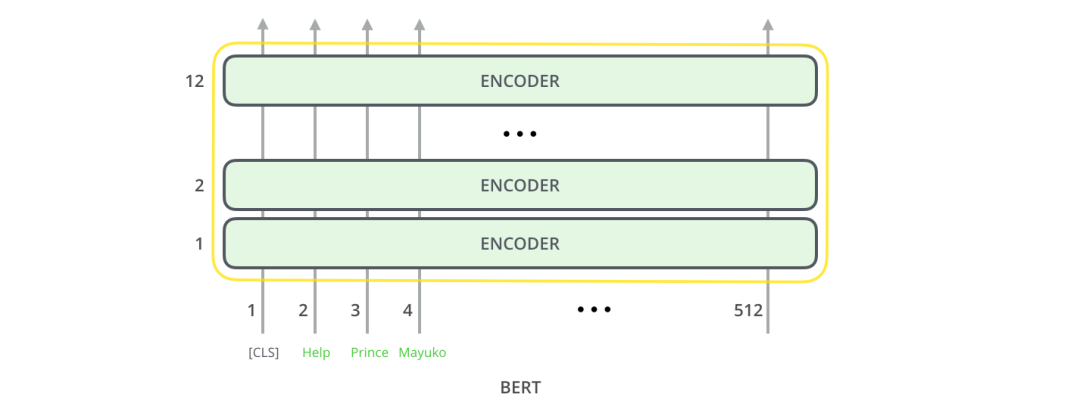
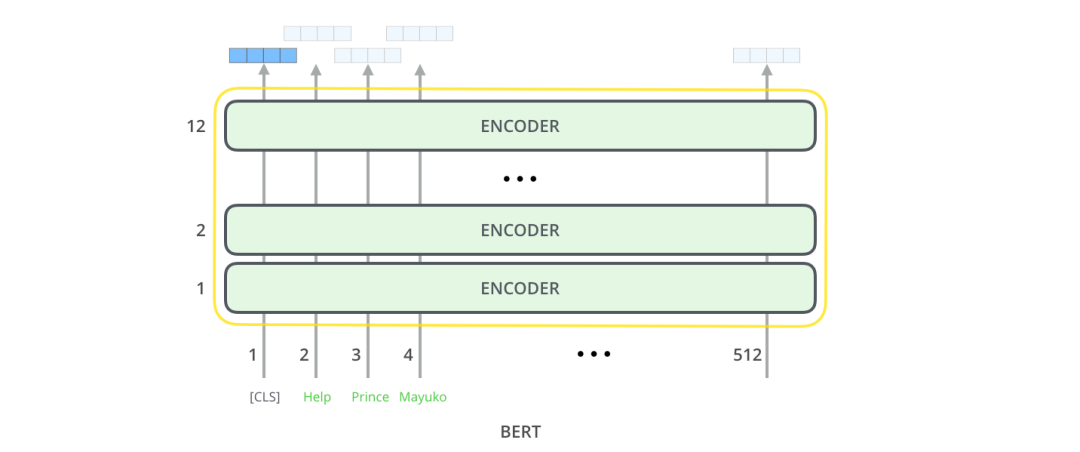
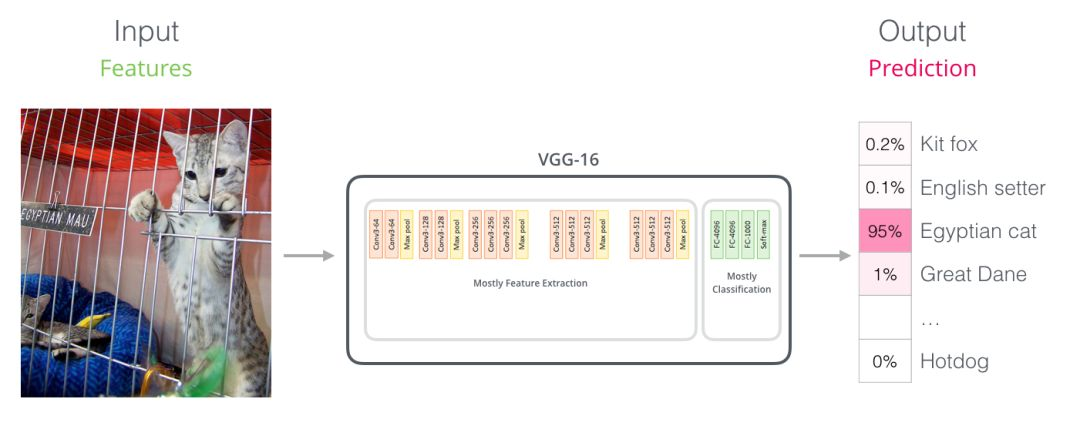
对于那些具有计算机视觉背景的人来说,这个矢量切换应该让人联想到VGGNet等网络的卷积部分与网络末端的完全连接的分类部分之间发生的事情。你可以这样理解,实质上这样理解也很方便。
词嵌入的新时代〜

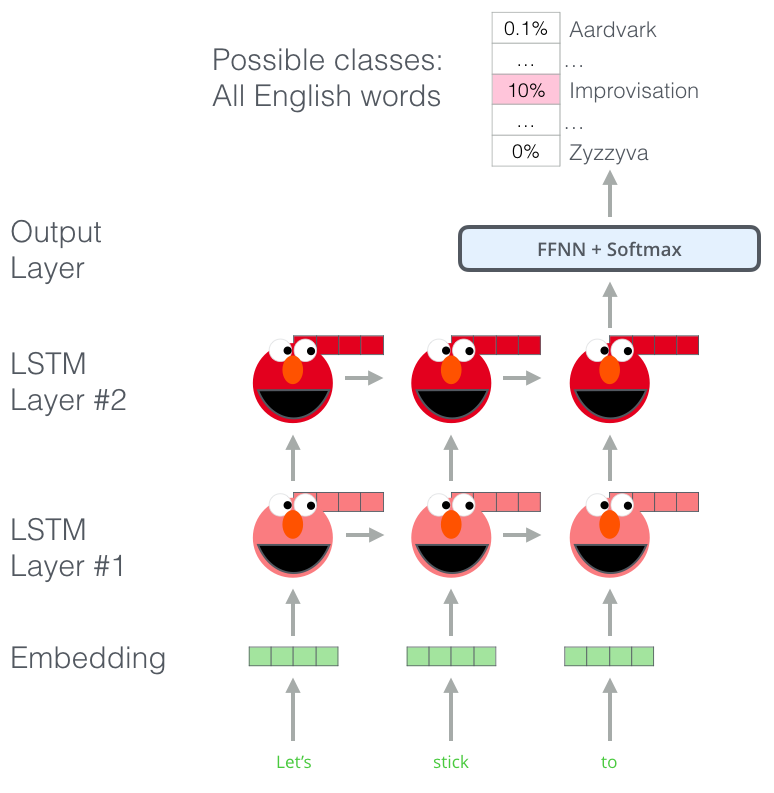
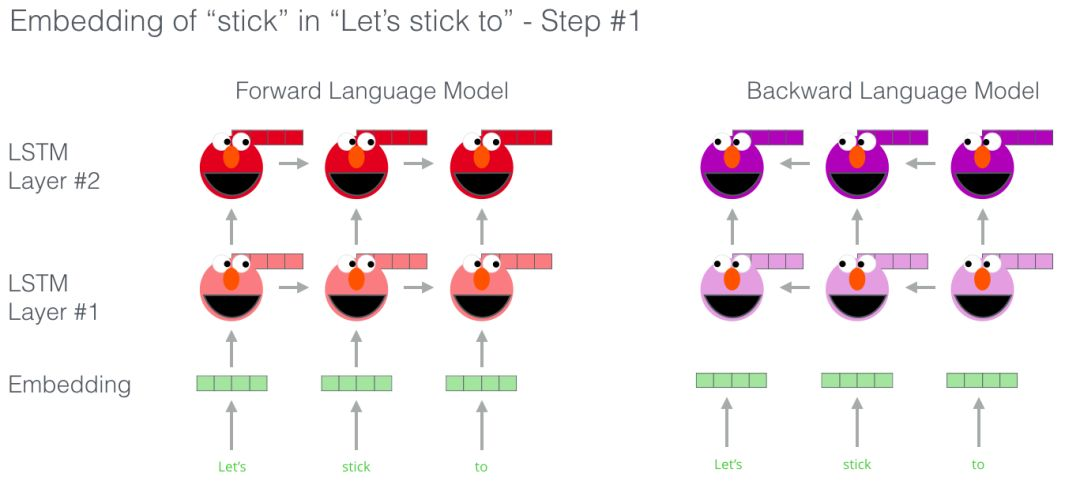
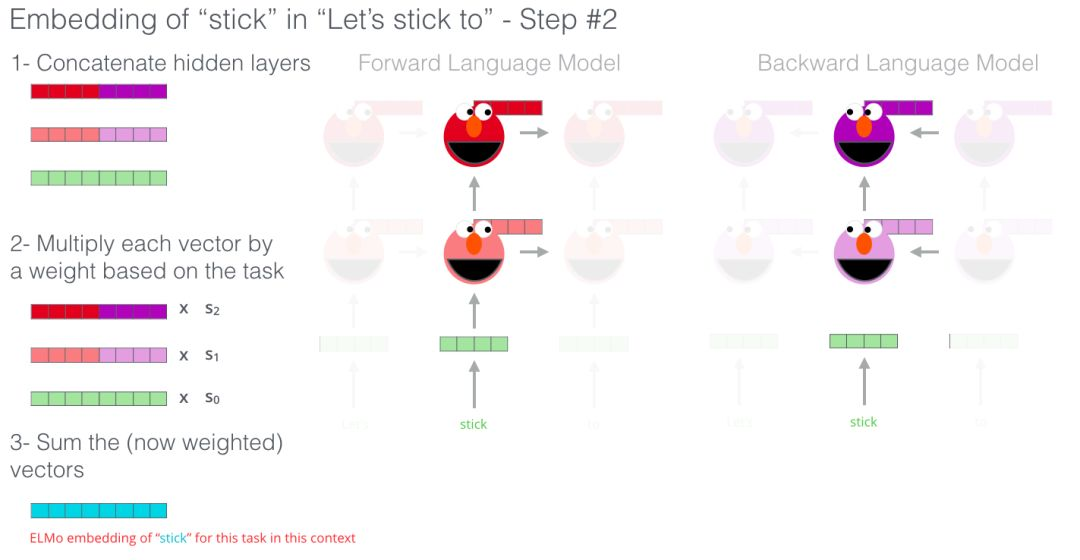

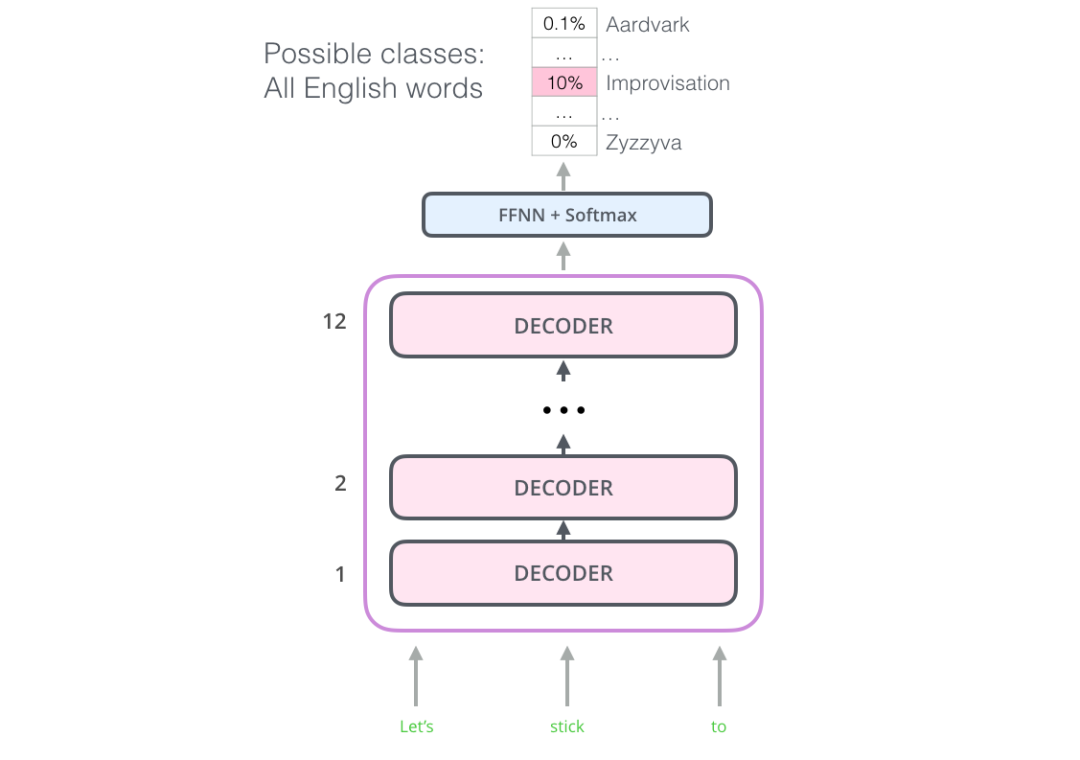
BERT说:“我要用 transformer 的 encoders”
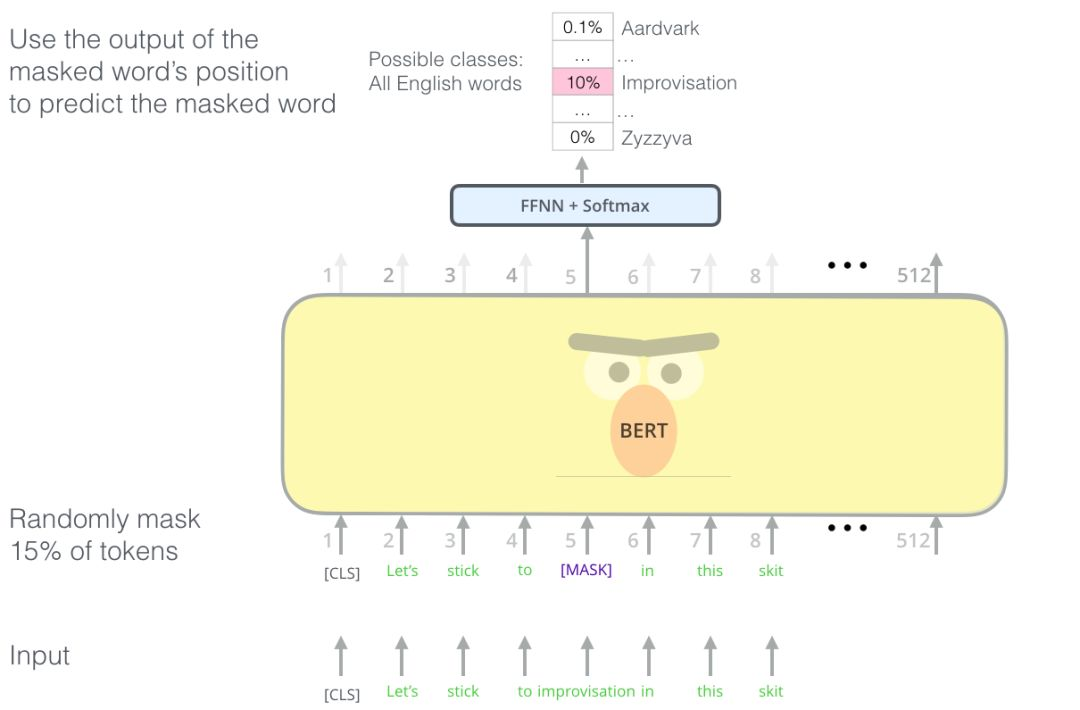

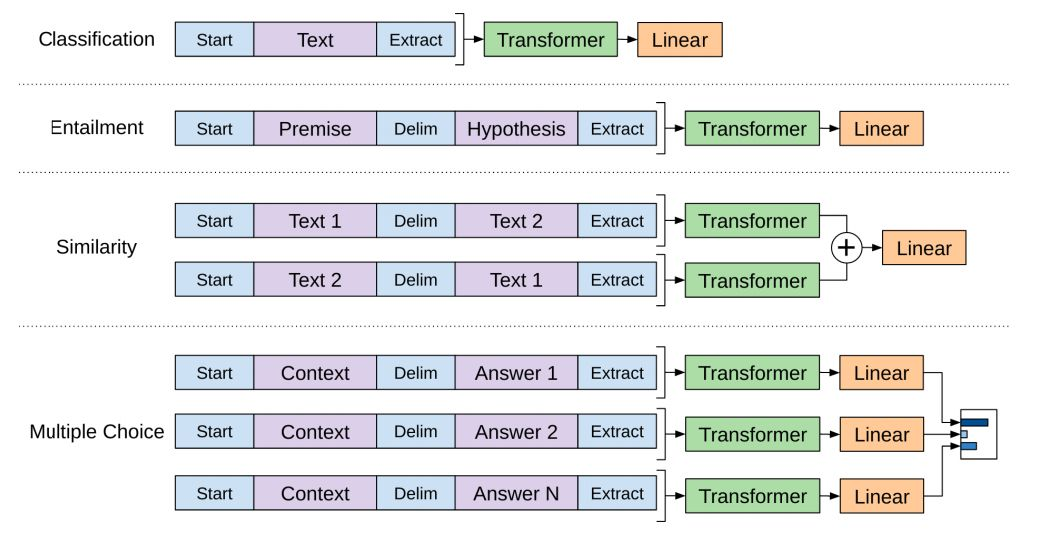
短文本相似 文本分类 QA机器人 语义标注
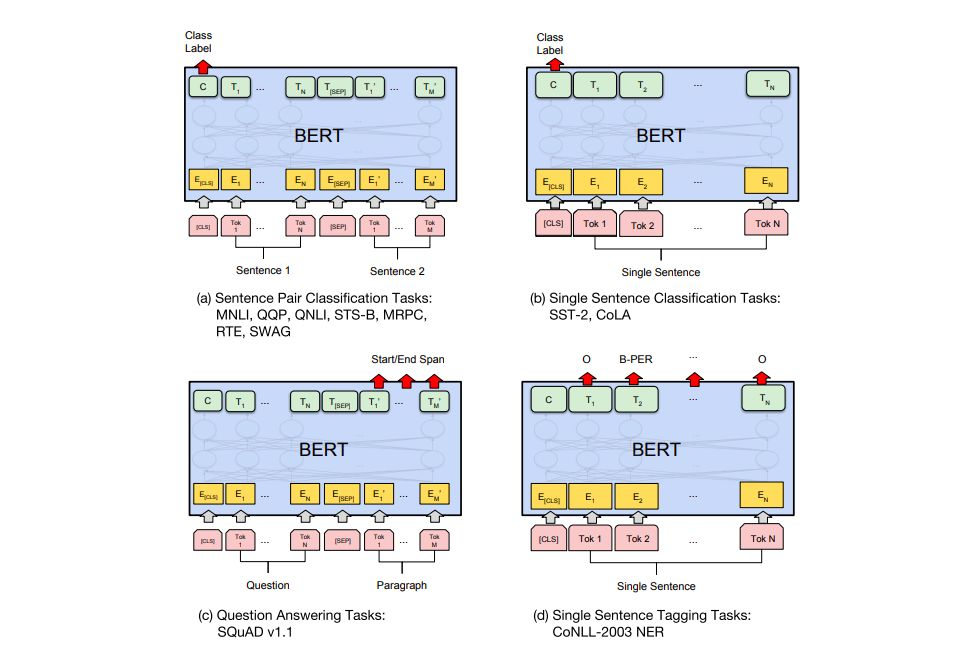
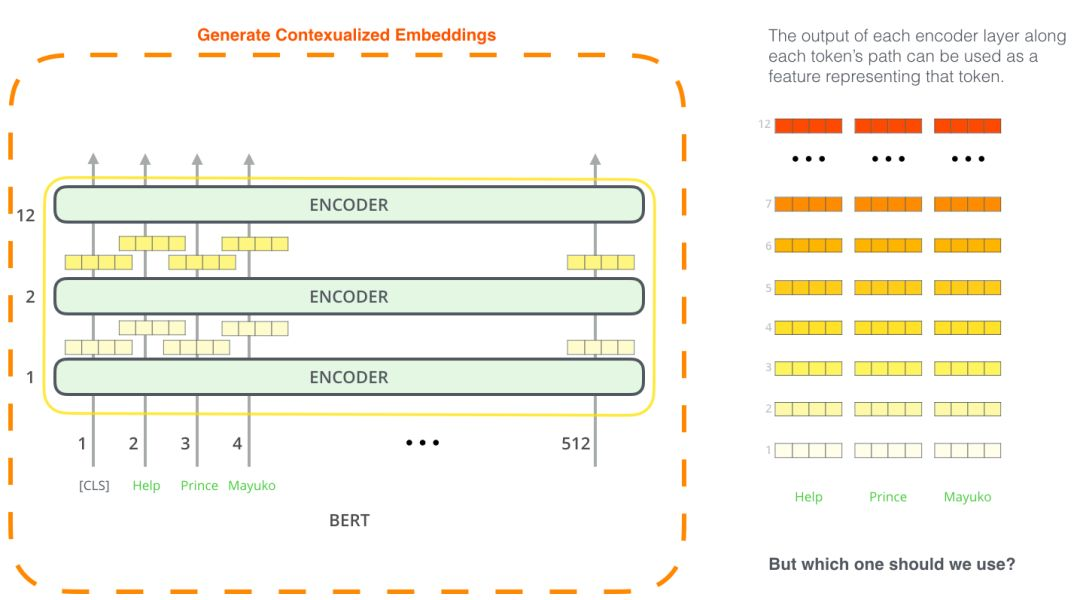
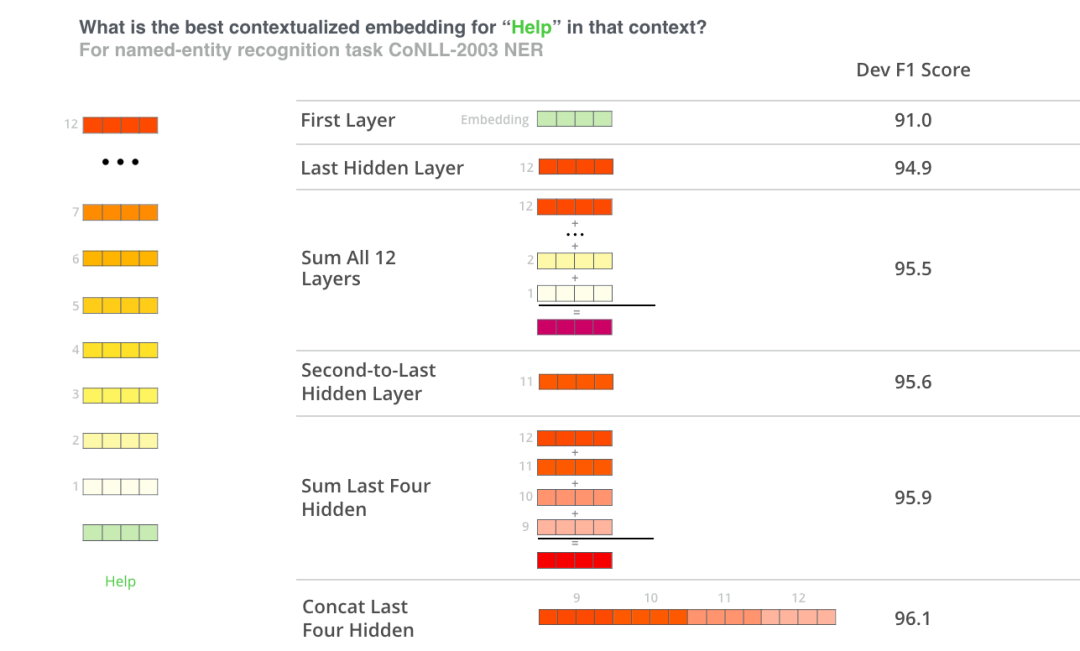
评论