
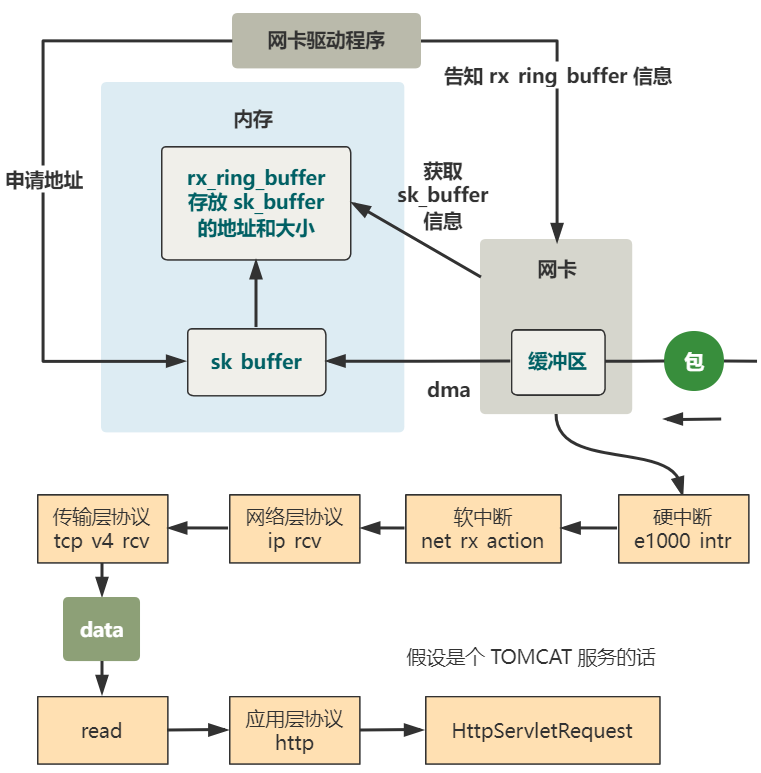
当内核收到了一个网络包
低并发编程
共 6500字,需浏览 13分钟
·
2021-10-24 15:22
之前两篇文章给这篇做了铺垫,分别讲了。
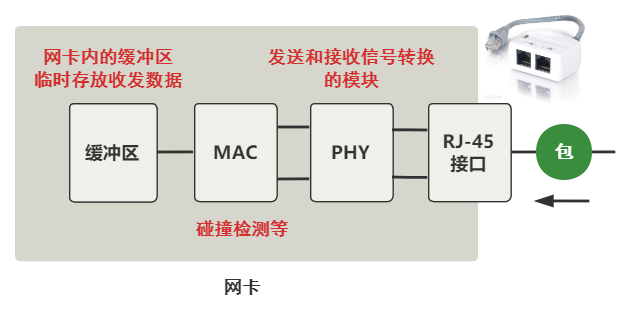
从网线到网卡
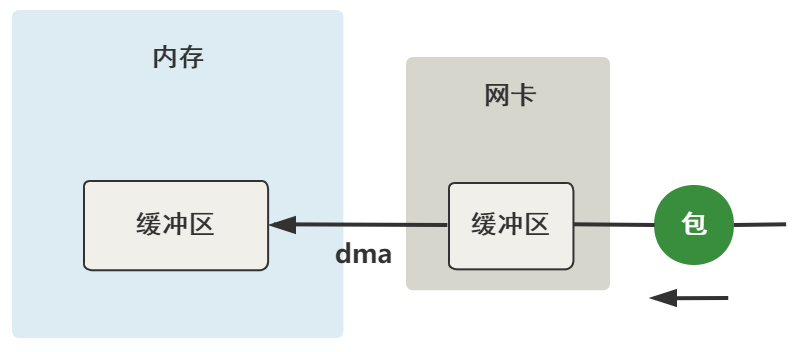
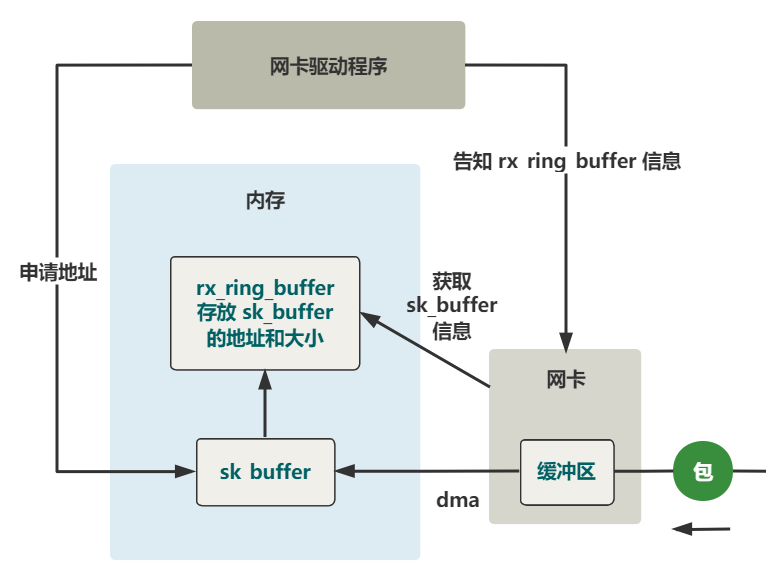
从网卡到内存
注册硬中断处理程序
request_irq(netdev->irq, &e1000_intr, ...);
硬中断 e1000_intr 干了什么
// 注册的硬中断处理函数
static irqreturn_t e1000_intr(int irq, void *data, struct pt_regs *regs) {
__netif_rx_schedule(netdev);
}
include\linux\netdevice.h
static inline void __netif_rx_schedule(struct net_device *dev) {
list_add_tail(&dev->poll_list, &__get_cpu_var(softnet_data).poll_list);
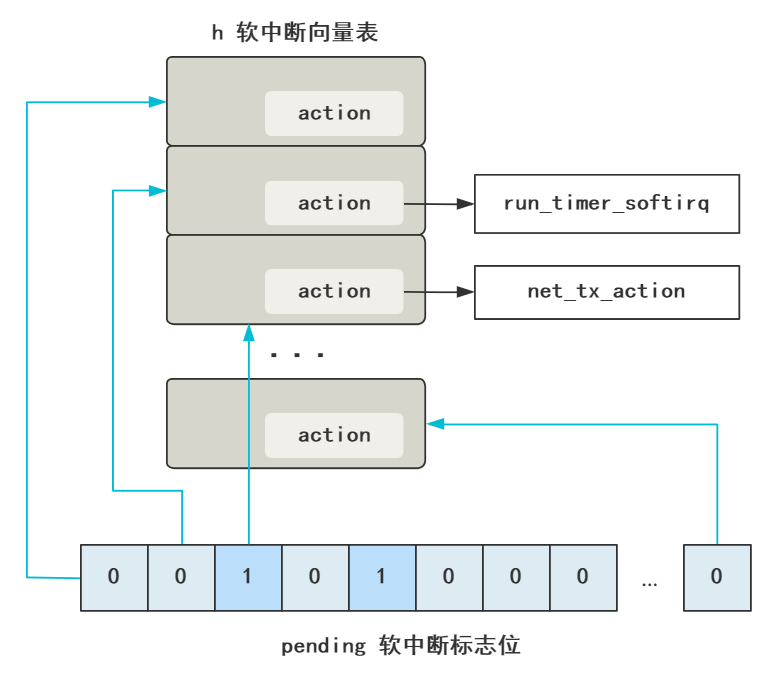
// 发出软中断
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
注册软中断处理程序
static int __init net_dev_init(void) {
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
}
// transmit 发送
static void net_tx_action(struct softirq_action *h) {...}
// receive 接收
static void net_rx_action(struct softirq_action *h) {...}
软中断 net_rx_action 干了什么
static void net_rx_action(struct softirq_action *h) {
struct softnet_data *queue = &__get_cpu_var(softnet_data);
while (!list_empty(&queue->poll_list)) {
struct net_device dev = list_entry(
queue->poll_list.next, struct net_device, poll_list);
dev->poll(dev, &budget);
}
}
netdev->poll = &e1000_clean;
static int e1000_clean(struct net_device *netdev, int *budget) {
struct e1000_adapter *adapter = netdev->priv;
e1000_clean_tx_irq(adapter);
e1000_clean_rx_irq(adapter, &work_done, work_to_do);
}
// drivers\net\e1000\e1000_main.c
e1000_clean_rx_irq(struct e1000_adapter *adapter) {
...
netif_receive_skb(skb);
...
}
// net\core\dev.c
int netif_receive_skb(struct sk_buff *skb) {
...
list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&15], list) {
...
deliver_skb(skb, ptype, 0);
...
}
...
}
static __inline__ int deliver_skb(
struct sk_buff *skb, struct packet_type *pt_prev, int last) {
...
return pt_prev->func(skb, skb->dev, pt_prev);
}
协议栈的注册
// net\ipv4\ip_output.c
static struct packet_type ip_packet_type = {
.type = __constant_htons(ETH_P_IP),
.func = ip_rcv,
};
void __init ip_init(void) {
dev_add_pack(&ip_packet_type);
}
// net\core\dev.c
void dev_add_pack(struct packet_type *pt) {
if (pt->type == htons(ETH_P_ALL)) {
list_add_rcu(&pt->list, &ptype_all);
} else {
hash = ntohs(pt->type) & 15;
list_add_rcu(&pt->list, &ptype_base[hash]);
}
}
module_init(inet_init);
static struct inet_protocol tcp_protocol = {
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
};
static struct inet_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
};
static int __init inet_init(void) {
inet_add_protocol(&udp_protocol, IPPROTO_UDP);
inet_add_protocol(&tcp_protocol, IPPROTO_TCP);
ip_init();
tcp_init();
}
网络层处理函数 ip_rcv 干了什么
// net\ipv4\ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt) {
...
return NF_HOOK(PF_INET, NF_IP_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
}
static inline int ip_rcv_finish(struct sk_buff *skb) {
...
if (skb->dst == NULL) {
if (ip_route_input(skb, iph->daddr, iph->saddr, iph->tos, dev))
goto drop;
}
...
return dst_input(skb);
}
// include\net\dst.h
// rth->u.dst.input= ip_local_deliver;
static inline int dst_input(struct sk_buff *skb) {
...
skb->dst->input(skb);
...
}
// net\ipv4\ip_input.c
int ip_local_deliver(struct sk_buff *skb) {
...
return NF_HOOK(PF_INET, NF_IP_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
static inline int ip_local_deliver_finish(struct sk_buff *skb) {
...
ipprot = inet_protos[hash];
ipprot->handler(skb);
...
}
static struct inet_protocol tcp_protocol = {
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
};
static struct inet_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
};
评论