
OpenCV系列(九)图像仿射变换
无论是在人脸识别或者跟踪领域,还是在图像处理领域,在我们做训练或者分析局部数据之前,都需要把对应的图像数据提取出来。但是在实际情况中,我们不一定每次都能找到水平的预测框,例如在OCR识别中,我们检测到的文字事实上可能是歪的。这时候就需要反射变化将歪的图片转换成正的,以供我们进行下一步的训练或识别。

● 场景模拟
首先,我们使用Opencv模拟出一个斜着的矩形框,并且提取出矩形框四个角的坐标,代码如下:
import cv2import numpy as npdef get_point(th):boxes=[]contours, _ = cv2.findContours(th, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)for contour in contours:if cv2.contourArea(contour) > 120000:continueelse:rect = cv2.minAreaRect(contour)boxs = cv2.boxPoints(rect)for index ,value in enumerate(boxs):print(value)x,y=valueboxes.append([int(x),int(y)])cv2.circle(img,(x,y),1,(0,255,0))cv2.putText(img,'%s'%index,(x,y),cv2.FONT_HERSHEY_COMPLEX,.5,(255,0,0),1)return boxesif __name__ == '__main__':img=cv2.imread('opencv_image/range_back.jpg')gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)blur=cv2.GaussianBlur(gray,(5,5),0)_,th=cv2.threshold(blur,0,255,cv2.THRESH_BINARY)points=get_point(th)cv2.imshow('img',img)cv2.waitKey(0)
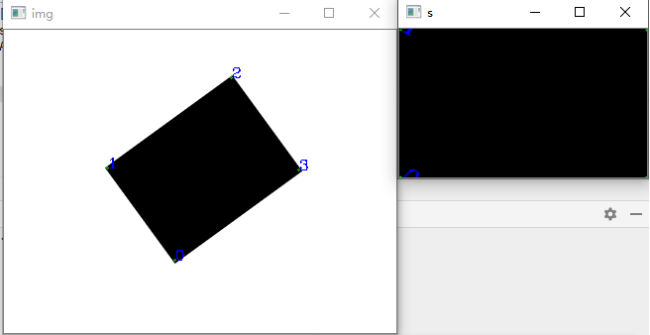
程序运行结果如下,在一张白色为底色的带有旋转方框的图片中,我们取到了4个顶点的坐标,分别为:左下角、左上角、右上角、右下角:

● 放射变换
取得这些坐标后,我们就可以对图中的矩形进行矫正,把矩形变为水平的,并提取出来。使用的代码如下:
if __name__ == '__main__':img=cv2.imread('opencv_image/range_back.jpg')gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)blur=cv2.GaussianBlur(gray,(5,5),0)=cv2.threshold(blur,0,255,cv2.THRESH_BINARY)points=get_point(th)# 只需要3个点就可以进行仿射变换points=np.array(points,np.float32)[:-1]# 图片反射变换之后的对应坐标系 位置与获取的点的位置相同new_point = np.array([[0, 150], [0, 0], [250,0]], np.float32)A1 = cv2.getAffineTransform(points, dst=new_point)d1=cv2.warpAffine(img,A1,(250,150),borderValue=125)cv2.imshow('img',img)cv2.imshow('s',d1)cv2.waitKey(0)
运行程序的结果为如下,我们把非水平的矩形提取出来,变成水平的矩形,但是这需要最少3个坐标才能完成仿射变换:
函数解析: cv2.getAffineTransform(src, dst)
作用:生成仿射变换矩阵
| src | 输入的3个点 |
| dst | 输出的3个点 |
函数解析:cv2.warpAffine(img,M,dsize,borderValue)
作用:进行仿射变换
| img | 输入图像 |
| M | 变换矩阵 |
| dsize | 输出的图片大小 |
| borderValue | 边框填充,默认为0 |
评论