8个常见的机器学习算法的计算复杂度总结
数据派THU
共 1174字,需浏览 3分钟
·
2022-08-25 10:55

来源:DeepHub IMBA 本文约1000字,建议阅读6分钟 本文为你整理了一些常见的机器学习算法的计算复杂度。
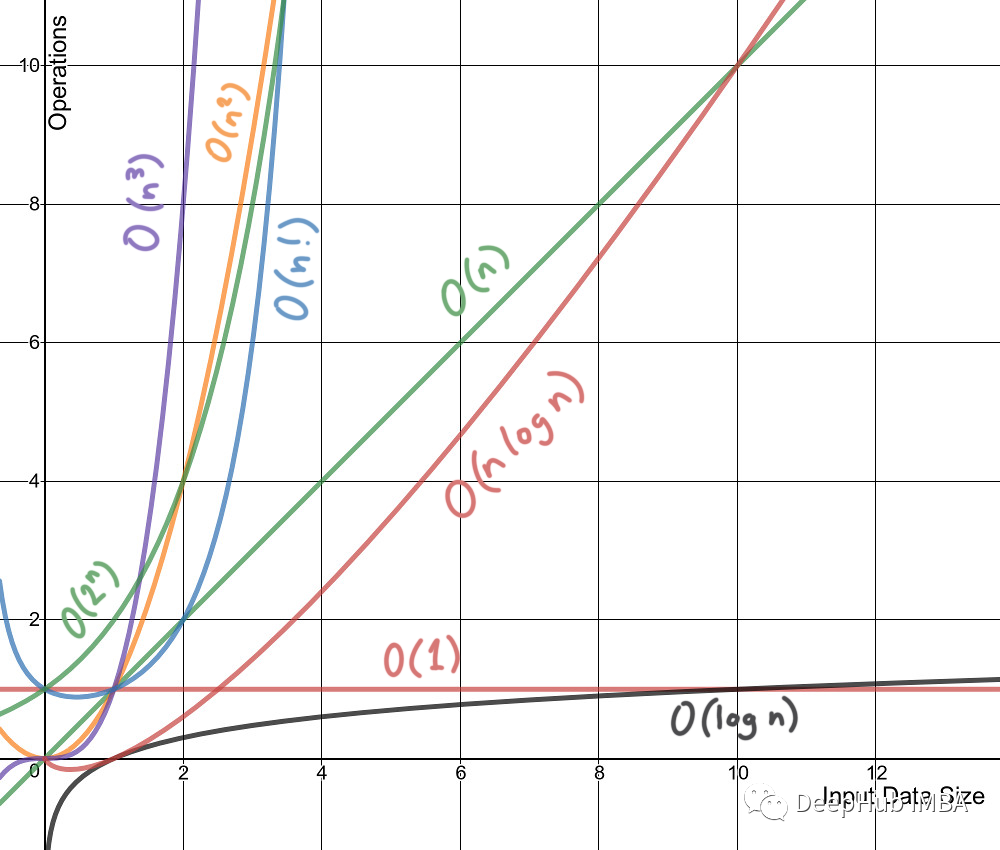
算法或计算机程序的空间复杂度是解决计算问题实例所需的存储空间量,以特征数量作为输入的函数。
编辑:黄继彦
校对:林亦霖
评论

共 1174字,需浏览 3分钟
·
2022-08-25 10:55
来源:DeepHub IMBA 本文约1000字,建议阅读6分钟 本文为你整理了一些常见的机器学习算法的计算复杂度。
算法或计算机程序的空间复杂度是解决计算问题实例所需的存储空间量,以特征数量作为输入的函数。
编辑:黄继彦
校对:林亦霖