
集成学习Bagging和Boosting简述
共 871字,需浏览 2分钟
·
2020-12-09 22:22
集成学习是时下非常火爆的一款机器学习方法,是将多个弱分类器按照某种方式组合起来,形成一个强分类器,以此来获得比单个模型更好的回归和分类表现,其常用的方法有 Bagging 和 Boosting。
Bagging
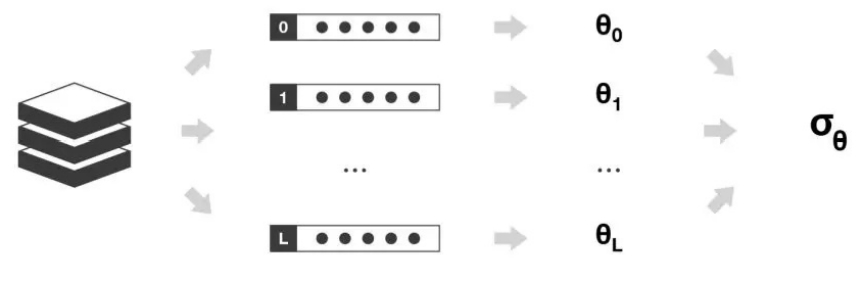
把数据集通过有放回的抽样方式,一次性建立多个平行独立的弱评估器。针对分类问题,按照少数服从多数原则进行投票,针对回归问题,求多个测试结果的平均值。其代表模型为随机森林。
Boosting
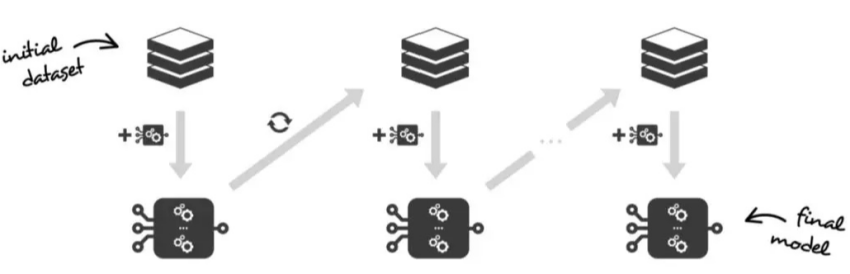
Bagging 是以自适应的方法按顺序一一学习这些弱学习器,即每个新学习器都依赖于前面的模型,并按照某种确定性的策略将它们组合起来 ,其核心思想是结合弱评估器的力量一次次对难以评估的样本进行预测,从而构成一个强评估器。其代表算法为 AdaBoost 和 GBDT (梯度提升)。
AdaBoost 与 GBDT 的区别
AdaBoost
第一颗树建模完成后,对模型进行评估,然后将模型预测错误的样本反馈给我们的数据集,第一次迭代就算完成。在第二次有放回抽样时,被给予前面错误预测的数据更高权重,简单来说就是前面被判断错误的样本更有可能被我们抽中。
GBDT
第一颗树建模完成后,把其残差(真实值和预测值之间的差值)结果作为下一次预测依据,依次类推,直到残差小于某个接近 0 的阀值或回归树数目达到某一阀值。其核心思想是每轮通过拟合残差来降低损失函数。
Boosting 与 Bagging 的区别:
评估器:Bagging 的基分类器训练是独立的,而 Boosting 的训练集是依赖于之前的模型;
作用:Bagging 的作用是减少方差,提升模型的整体稳定性,而 Boosting 在于减少偏差,提高模型整体的精确度;
抽样数据集:Bagging 是有放回抽样,Boosting 也是有放回抽样,但是会确认数据的权重。