
深度学习模型压缩与加速综述
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

导读
本文详细介绍了4种主流的压缩与加速技术:结构优化、剪枝、量化、知识蒸馏,作者分别从每个技术结构与性能表现进行陈述。
近年来,深度学习模型在CV、NLP等领域实现了广泛应用。然而,庞大的参数规模带来的计算开销、内存需求,使得其在计算能力受限平台的部署中遇到了巨大的困难与挑战。因此,如何在不影响深度学习模型性能的情况下进行模型压缩与加速,成为了学术界和工业界的研究热点。
深度学习模型压缩与加速是指利用神经网络参数和结构的冗余性精简模型,在不影响任务完成度的情况下,得到参数量更少、结构更精简的模型。被压缩后的模型对计算资源和内存的需求更小,相比原始模型能满足更广泛的应用需求。(事实上,压缩和加速是有区别的,压缩侧重于减少网络参数量,加速侧重于降低计算复杂度、提升并行能力等,压缩未必一定能加速,本文中我们把二者等同看待)
必要性:主流的模型,如VGG-16,参数量1亿3千多万,占用500多MB空间,需要进行300多亿次浮点运算才能完成一次图像识别任务。 可行性:并非所有的参数都在模型中发挥作用,部分参数作用有限、表达冗余,甚至会降低模型的性能,因此,只需训练一小部分的权值参数就有可能达到和原来网络相近的性能甚至超过原来网络的性能(可以看做一种正则化)。
压缩与加速,大体可以从三个层面来做:算法层、框架层、硬件层,本文仅讨论算法层的压缩与加速技术。
主流的压缩与加速技术有4种:结构优化、剪枝(Pruning)、量化(Quantization)、知识蒸馏(Knowledge Distillation)。
2.1、结构优化
通过优化网络结构的设计去减少模型的冗余和计算量。常见方式如下:
矩阵分解:如ALBERT的embedding layer 参数共享:如CNN和ALBERT(只能压缩参数不能加速推理) 分组卷积:主要应用于CV领域,如shuffleNet,mobileNet等 分解卷积:使用两个串联小卷积核来代替一个大卷积核(Inception V2)、使用两个并联的非对称卷积核来代替一个正常卷积核(Inception V3) 全局平均池化代替全连接层 使用1*1卷积核
2.2、剪枝
剪枝是指在预训练好的大型模型的基础上,设计对网络参数的评价准则,以此为根据删除“冗余”参数。根据剪枝粒度粗细,参数剪枝可分为非结构化剪枝和结构化剪枝。非结构化剪枝的粒度比较细,可以无限制去掉网络中期望比例的任何“冗余”参数,但会带来裁剪后网络结构不规整难以有效加速的问题。结构化剪枝的粒度比较粗,剪枝的最小单位是filter内参数的组合,通过对filter或者feature map设置评价因子,甚至可以删除整个filter或者某几个channel,使网络“变窄”,可以直接在现有软硬件上获得有效加速,但可能带来预测精度的下降,需要通过对模型微调恢复性能。
2.3、量化
量化是指用较低位宽表示典型的32bit浮点型网络参数。网络参数包括权重、激活值、梯度和误差等等, 可以使用统一的位宽(如16bit,8bit,2bit和1bit等),也可以根据经验或一定策略自由组合不同的位宽。量化的优点在于:1).能够显著减少参数存储空间与内存占用空间,如,将参数从32bit浮点型量化到8bit整型能够减少75%的存储空间,这对于计算资源有限的边缘设备和嵌入式设备进行深度学习模型的部署和使用都有很大帮助;2).能够加快运算速度,减少设备能耗,读取32bit浮点数所需的带宽可以同时读入4个8bit整数,并且整型运算相比浮点型运算更快,自然能降低设备功耗。但其仍存在一定的局限性,网络参数的位宽减少损失一部分信息量,造成推理精度下降,虽然能通过微调恢复部分精确度,但带来时间成本;量化到特殊位宽时,很多现有的训练方法和硬件平台不再适用,需要设计专用的系统架构,灵活性不高。
2.4、知识蒸馏
知识蒸馏在Hinton于2015年发表的《Distilling the Knowledge in a Neural Network》(https://arxiv.org/pdf/1503.02531.pdf)中被提出。
同其它压缩与加速技术不同,知识蒸馏需要两种类型的网络:Teacher Model和Student Model。前者参数量大、结构复杂,后者参数量较小、结构相对简单。二者可以是不同的网络结构,但是采用相似的网络结构,蒸馏效果会更好。训练流程如下图所示:

首先训练Teacher Model,然后用其指导Student Model的训练(训练集可以保持一致)。具体指导方案,将Teacher Model在Softmax层的输出作为数据的soft label(熵更高,信息量更大),Student Model的loss function将是对soft label预测和hard label预测的loss的线性加权和(具体可以参考https://zhuanlan.zhihu.com/p/102038521)。Student Model训练好后,按照常规模型使用即可。
对soft label预测的loss,可以计算两个Model在Softmax层的输出的Cross Entropy,也可以计算两个Model在Softmax层的输入的MSE。
知识蒸馏通过将Teacher Model的知识迁移到Student Model中,使Student Model达到与Teacher Model相当的性能,同时又能起到模型压缩的目的。其局限性在于,由于使用Softmax层的输出作为知识,所以一般多用于具有Softmax层面的分类任务,在其它任务上的表现不好。
以下列举几个知识蒸馏的应用实例。
3.1、DistillBERT
DistillBERT在Hugging Face于2019年发表的《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》(https://arxiv.org/pdf/1910.01108.pdf)中被提出。
DistillBERT的细节如下:
Student架构:总体和BERT一致,移除了token-type embeddings和pooler,层数减半(每两层去掉一层,由12层减到6层) Student初始化:直接采用Teacher(BERT-base)中对应的参数进行初始化 Training loss:  ,其中,
,其中,  是soft label之间的KL散度(非交叉熵),
是soft label之间的KL散度(非交叉熵),  同BERT,
同BERT,  是隐层向量之间的cosine值
是隐层向量之间的cosine值Student训练:采用了RoBERTa的方式,如,更大的batch_size、dynamic masking、去NSP 数据集:Student采用了和原始BERT一致的数据集
DistillBERT在GLUE数据集上的性能表现:
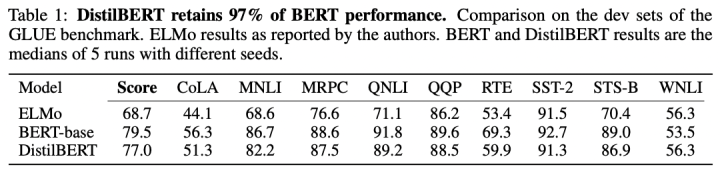
DistillBERT在参数量和推理速度上的表现:

3.2、TinyBERT
TinyBERT在华科+华为于2019年发表的《TinyBERT: Distilling BERT for Natural Language Understanding》(https://arxiv.org/pdf/1909.10351.pdf)中被提出。
TinyBERT的训练流程如下:
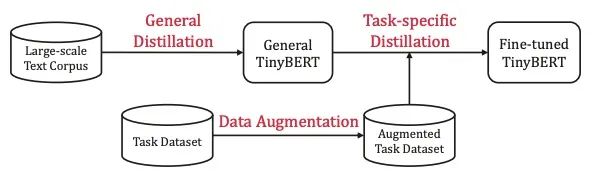
整体是个两阶段的蒸馏过程:
General Distillation:以未经fine-tuning的BERT作为Teacher,蒸馏得到General TinyBERT Task-specific Distillation:以fine-tuning后的BERT作为Teacher,General TinyBERT作为Student的初始化,在经过数据增强后的Task Dataset上继续蒸馏,得到Fine-tuned TinyBERT
TinyBERT的结构如下:

TinyBERT的loss如下:

其中,  表示embedding layer,
表示embedding layer,  表示prediction layer,
表示prediction layer,  有三种形式,代表三种不同的loss:
有三种形式,代表三种不同的loss:

 都是MSE loss,
都是MSE loss,  是Cross Entropy loss,具体计算公式可参考论文。
是Cross Entropy loss,具体计算公式可参考论文。
TinyBERT的性能表现如下:

3.3、FastBERT
FastBERT在北大+腾讯于2020年发表的《FastBERT: a Self-distilling BERT with Adaptive Inference Time》(https://arxiv.org/pdf/2004.02178.pdf)中被提出。
FastBERT的结构如下:

它的创新点在于self-distillation mechanism和sample-wise adaptive mechanism:
self-distillation mechanism:Teacher(backbone)和Student(branch)统一在一个模型中,在原始BERT的每层Transformer后接Student Classifier,拟合原始BERT的Teacher Classifier;backbone和branch的参数训练是独立的,其中一个模块参数在训练时,另一个模块参数会frozen sample-wise adaptive mechanism:基于LUHA(the Lower the Uncertainty,the Higher the Accuracy)假设,在底层Transformer对应的Student Classifier中,如果已经做出了置信的分类决策,则不再继续顶层的预测
FastBERT的训练流程如下:
Pre-training:对除Teacher Classifier外的backbone进行预训练,这部分和BERT系列模型没有区别(甚至可以直接使用开源的训练好的模型) Fine-tuning forbackbone:根据下游任务,采用对应的数据集,训练含Teacher Classifier在内的backbone Self-distillation for branch:可以采用无标签的数据(因为不需要label,只需要Teacher Classifier的输出),Teacher Classifier的输出  作为soft label,计算Student Classifier的输出
作为soft label,计算Student Classifier的输出  和 之间的KL散度,将所有层的KL散度之和作为total loss:
和 之间的KL散度,将所有层的KL散度之和作为total loss:
为了实现Adaptive inference,FastBERT采用了归一化的熵作为Student Classifier决策结果的置信度指标:

其中, 是Student Classifier输出的概率分布,  是类目数量。论文中,给Uncertainty设定的阈值是Speed,二者取值均介于0、1之间。
是类目数量。论文中,给Uncertainty设定的阈值是Speed,二者取值均介于0、1之间。
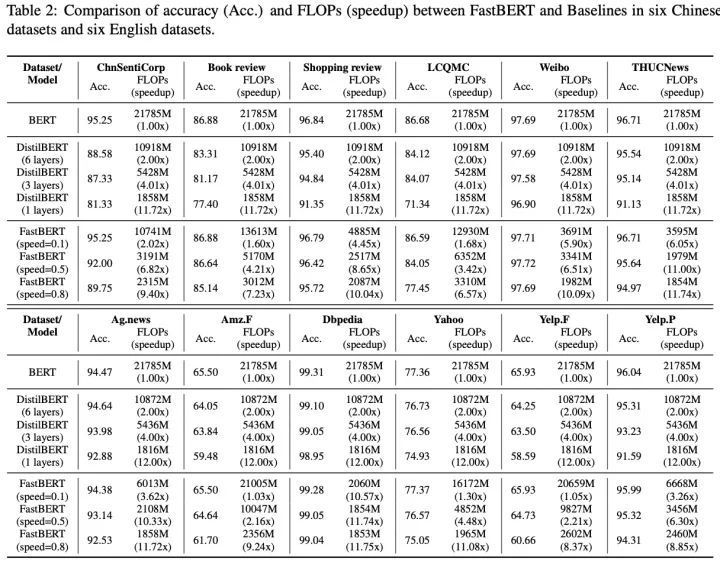
FastBERT的性能表现如下(当前仅应用于分类任务):
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~