
ICCV2021论文速递 | Transformer 分割、文本识别、视频插帧、视频修复!
共 3211字,需浏览 7分钟
·
2021-08-21 01:11
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
大家好,今天跟大家分享 ICCV 2021 的论文成果,主要包含五篇内容的简介:
基于Transformer 的分割方法;
用于场景文本识别的数据增强;
在线持续学习在食品视觉分类中的应用;
用于视频插帧的非对称双边运动估计;
遮挡感知视频对象修复
更多ICCV 2021 最新工作(目前已更新 250+论文):
https://github.com/DWCTOD/ICCV2021-Papers-with-Code-Demo
SOTR: Segmenting Objects with Transformers
基于Transformer 的分割方法

论文:https://arxiv.org/abs/2108.06747
代码:https://github.com/easton-cau/SOTR
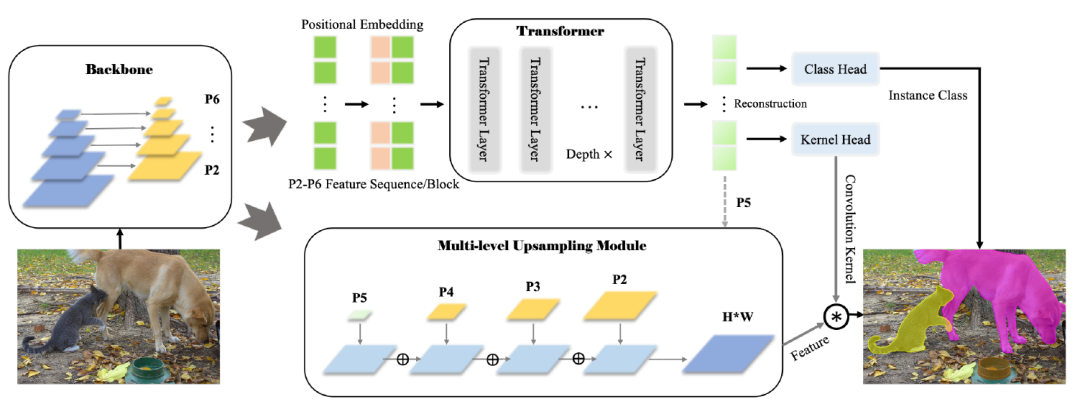
摘要:最新的基于Transformer的模型在视觉任务上表现出令人印象深刻的性能,甚至比卷积神经网络(CNN)更好。在这项工作中,我们提出了一种新颖、灵活、有效的基于Transformer 的高质量实例分割模型。所提出的Segmenting Objects with Transformers(SOTR)的方法简化了分割pipeline,建立在一个附加有两个并行子任务的CNN主干上:
(1)通过Transformer 预测每个实例的类别;
(2)使用多级上采样模块动态生成分割掩码。
SOTR可以分别通过特征金字塔网络(FPN)和twin transformer有效地提取底层特征表示,并捕获长期上下文依赖。同时,与原Transformer 相比,该双Transformer 在时间和资源上都是高效的,因为只需要注意一行和一列来编码像素。此外,SOTR易于与各种CNN主干和Transformer模型变体结合,从而大大提高分割精度和训练收敛性。大量实验表明,我们的SOTR在MS COCO数据集上表现良好,超过了最先进的实例分割方法。我们希望我们简单但强大的框架可以作为实例级识别的首选基线。
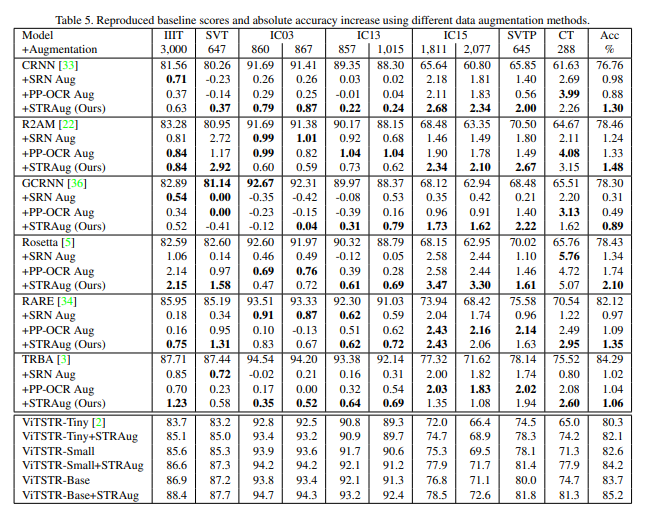
Data Augmentation for Scene Text Recognition
用于场景文本识别的数据增强

论文:https://arxiv.org/abs/2108.06946
代码:https://github.com/roatienza/straug

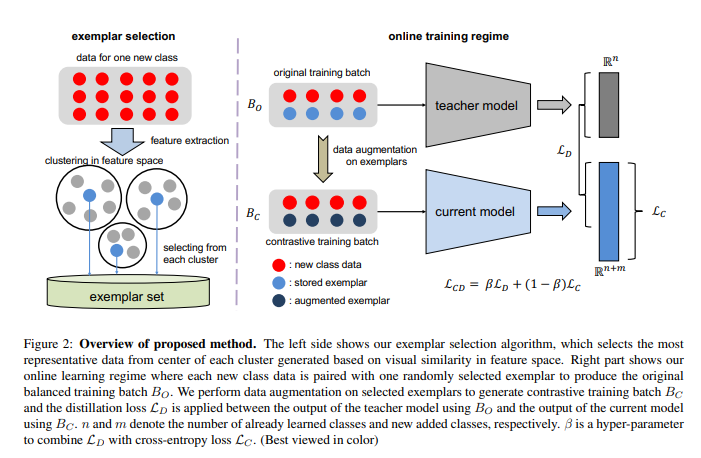
Online Continual Learning For Visual Food Classification

论文:https://arxiv.org/abs/2108.06781
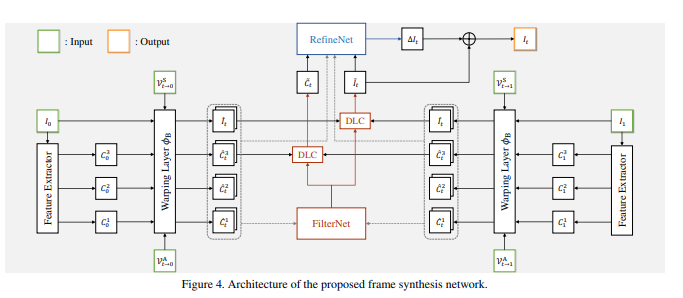
Asymmetric Bilateral Motion Estimation for Video Frame Interpolation

论文:https://arxiv.org/abs/2108.06815
代码:https://github.com/JunHeum/ABME
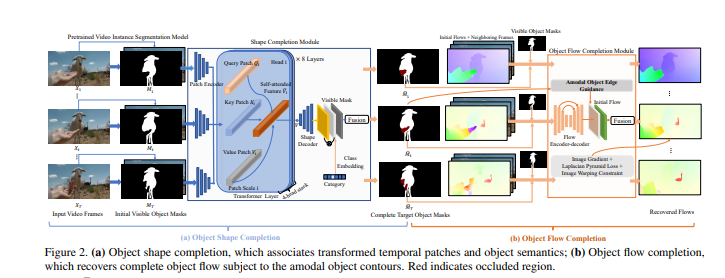
Occlusion-Aware Video Object Inpainting
遮挡感知视频对象修复

https://arxiv.org/abs/2108.06765
摘要:传统的视频修复既不是面向对象的,也不是遮挡感知的,这使得在修复大的遮挡对象区域时容易产生明显的伪影。该文提出了一种基于遮挡的视频对象修复方法,该方法在给定遮挡对象可见遮罩分割的情况下,恢复视频中遮挡对象的完整形状和外观。为了促进这项新的研究,我们构建了第一个大规模视频对象修复基准YouTube VOI,以提供具有遮挡和可见对象遮罩的真实遮挡场景。我们的技术贡献VOIN联合执行视频对象形状完成和遮挡纹理生成。特别是,形状完成模块建模远程对象一致性,而流完成模块恢复具有尖锐运动边界的精确流,以便跨帧将时间一致的纹理传播到同一运动对象。为了获得更真实的结果,我们使用T-PatchGAN和一种新的基于时空注意的多类鉴别器对VOIN进行了优化。最后,我们在YouTube VOI上比较VOIN和强基线。实验结果清楚地证明了我们的方法的有效性,包括修复复杂和动态对象。VOIN随着不准确的输入可见遮罩而优雅地降解。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
