
【机器学习基础】(六):通俗易懂无监督学习K-Means聚类算法及代码实践
共 4743字,需浏览 10分钟
·
2021-04-23 17:26
K-Means是一种无监督学习方法,用于将无标签的数据集进行聚类。其中K指集群的数量,Means表示寻找集群中心点的手段。
一、 无监督学习 K-Means
贴标签是需要花钱的。
所以人们研究处理无标签数据集的方法。(笔者狭隘了)
面对无标签的数据集,我们期望从数据中找出一定的规律。一种最简单也最快速的聚类算法应运而生---K-Means。
它的核心思想很简单:物以类聚。
用直白的话简单解释它的算法执行过程如下:
随便选择K个中心点(大哥)。 把距离它足够近的数据(小弟)吸纳为成员,聚成K个集群(组织)。 各集群(组织)内部重新选择中心点(大哥),选择标准是按照距离取均值作为中心点(大哥)。 重复2、3步骤直到收敛(组织成员相对稳定)。
这就是黑涩会形成聚类的过程。
二、 K-Means代码实践
2.1 鸢尾花数据集
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 大家不用在意这个域名
df = pd.read_csv('https://blog.caiyongji.com/assets/iris.csv')
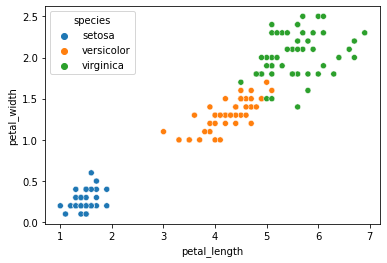
sns.scatterplot(x='petal_length',y='petal_width',data=df,hue='species')
我们得到带标签的数据如下:
2.2 K-Means训练数据
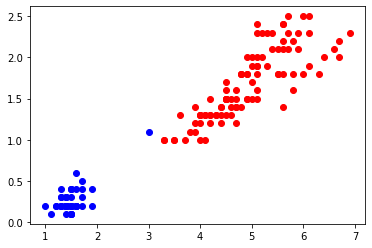
我们移除数据标签,仅使用花瓣长、宽作为数据输入,并使用无监督学习方法K-Means进行训练。
X = df[['petal_length','petal_width']].to_numpy()
from sklearn.cluster import KMeans
k = 2
kmeans = KMeans(n_clusters=k, random_state=42)
y_pred = kmeans.fit_predict(X)
plt.plot(X[y_pred==1, 0], X[y_pred==1, 1], "ro", label="group 1")
plt.plot(X[y_pred==0, 0], X[y_pred==0, 1], "bo", label="group 0")
# plt.legend(loc=2)
plt.show()
得到分类数据如下,我们并不知道下方数据类别分别代表什么意义。
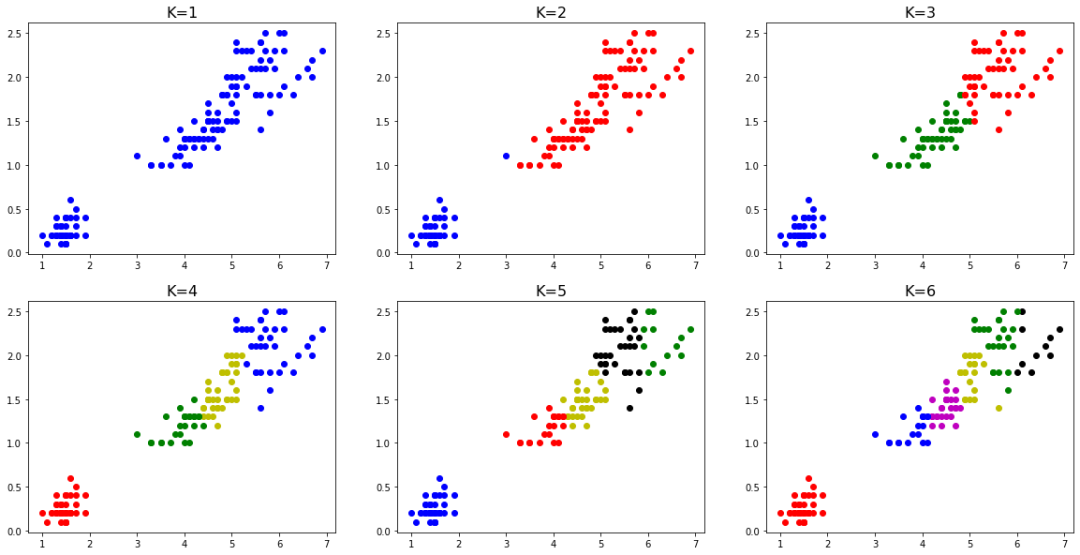
我们将K分别取1-6的值,可得到如下图所示分类结果:
那么K值的选择有什么意义呢?我们如何选择?
三、K的选择
3.1 惯性指标(inertia)
K-Means的惯性计算方式是,每个样本与最接近的集群中心点的均方距离的总和。
kmeans_per_k = [KMeans(n_clusters=k, random_state=42).fit(X)
for k in range(1, 10)]
inertias = [model.inertia_ for model in kmeans_per_k]
plt.figure(figsize=(8, 3.5))
plt.plot(range(1, 10), inertias, "bo-")
plt.xlabel("$k$", fontsize=14)
plt.ylabel("Inertia", fontsize=14)
plt.annotate('Elbow',
xy=(2, inertias[2]),
xytext=(0.55, 0.55),
textcoords='figure fraction',
fontsize=16,
arrowprops=dict(facecolor='black', shrink=0.1)
)
plt.axis([1, 8.5, 0, 1300])
plt.show()
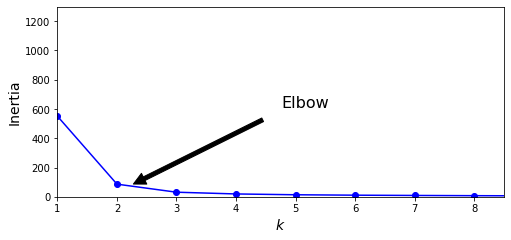
以上代码中model.inertia_即K-Means方法中的惯性指标。
一般地,惯性越小模型越好,但伴随K值的增大,惯性下降的速度变的很慢,因此我们选择“肘部”的K值,作为最优的K值选择。
3.2 轮廓系数指标(silhouette)
K-Means的轮廓系数计算方式是,与集群内其他样本的平均距离记为a,与外部集群样本的平均距离记为b,轮廓系数(b-a)/max(a,b)。
from sklearn.metrics import silhouette_score
silhouette_scores = [silhouette_score(X, model.labels_)
for model in kmeans_per_k[1:]]
plt.figure(figsize=(8, 3))
plt.plot(range(2, 10), silhouette_scores, "bo-")
plt.xlabel("$k$", fontsize=14)
plt.ylabel("Silhouette score", fontsize=14)
plt.axis([1.8, 8.5, 0.55, 0.8])
plt.show()
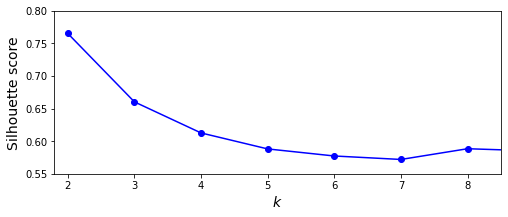
以上代码中silhouette_score方法可取得K-Means的轮廓系数值。
一般地,轮廓系数指标越大越好,我们可以看到当K为2、3时均可取得不错的聚类效果。
四、自动选择K值(拓展)
4.1 简单理解贝叶斯定理
白话解释贝叶斯:当有新的证据出现时,不确定的事情更加确信了。 这里的“确信”是指对不确定的事情的信心程度。
公式(可忽略):
其中,P(A) 表示事件A发生的概率,P(A|B)表示事件B发生时事件A发生的概率。上面的公式中B就是所谓的证据。这里要注意的是,P(B)的出现让P(A|B)变的更确定了,并不是说概率变高了或者变低了。概率的高或者低都是一种确定。它是一种信心程度的体现。
4.2 贝叶斯高斯混合模型
我们使用BayesianGaussianMixture方法,而无需指定明确的K值。
from sklearn.mixture import BayesianGaussianMixture
bgm = BayesianGaussianMixture(n_components=10, n_init=10, random_state=42)
y_pred = bgm.fit_predict(X)
np.round(bgm.weights_, 2)
输出: array([0.4 , 0.33, 0.27, 0. , 0. , 0. , 0. , 0. , 0. , 0. ])
以上代码的执行逻辑是,初始化10个集群,不断调整有关集群数贝叶斯先验知识,来将不必要的集群权重设为0(或接近0),来确定最终K值。
五、总结(系列完结)
5.1 机器学习系列完结
我相信,截至到目前,大家对机器学习已经有了一个基本的认识。最重要的是,大家亲手实践了机器学习的代码。无论你对机器学习有多么模糊的认识,都能近距离的接触到机器学习,这一点很重要。
当初,我发现市面上大部分的教程都对数学有强依赖,让很多人敬而远之。我觉得,无论顶尖的科学研究还是普罗大众的教育科普都有其不可替代的巨大价值。流于表面的广泛未必没有其意义,因此我选择了舍弃严谨,贴近通俗。
当然,想要深耕于AI领域,数学是充分且必要的条件。如果付得起时间和机会成本,请认真且努力,绝不会辜负你。
5.2 深度学习系列开始
深度学习是一台结构复杂的机器,但它的操作却相对简单。甚至,会给你比传统机器学习算法更简单的感受。
我们拭目以待!感谢大家!
往期文章:
往期精彩回顾
本站qq群851320808,加入微信群请扫码: