
【深度学习】从0学习YOLOV5:科大讯飞X光安检检测
共 7039字,需浏览 15分钟
·
2022-07-09 07:12
赛事背景
X光安检是目前在城市轨交、铁路、机场、物流业广泛使用的物检手段。使用人工智能技术,辅助一线安检员进行X光安检判图,可以有效降低因为安检员经验、能力或工作状态造成的错漏检问题。在实际场景中,因待检测物品的多样性、成像角度、重叠遮挡等问题,X光安检图像检测算法研究存在一定挑战。
比赛链接:http://challenge.xfyun.cn/topic/info?type=Xray-2022&ch=ds22-dw-zmt05
赛事任务
本赛事的任务是:基于科大讯飞提供的真实X光安检图像集构建检测模型,对X光安检图像中的指定类别的物品进行检测。
评审规则
数据说明
此次比赛提供带标注的训练数据,即待检测物品在包裹中的X光图像及其标注文件。
本次比赛标注文件中的类别为8类,包括:
刀(knife)、剪刀(scissors)、打火机(lighter)、优盘(USBFlashDisk)、压力容器(pressure)、带喷嘴塑料瓶(plasticBottleWithaNozzle)、公章(seal)、电池(battery)。
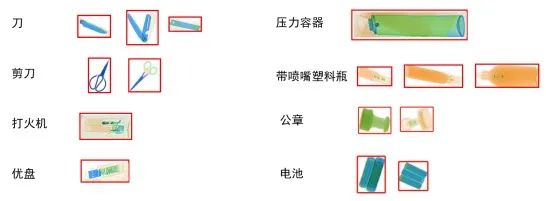
待识别物品的X光成像示意图如图所示。
比赛提供的X光图像及其矩形框标注的文件按照数据来源存放在不同的文件夹中,图像文件采用jpg格式,标注文件采用xml格式,各字段含义参照voc数据集。voc各字段含义对应表为:
filename 文件名 size 图像尺寸 width 图像宽度 height 图像高度 depth 图像深度 object 图像中的目标,可能有多个 name 该目标的标签名称 bndbox 该目标的标注框 xmin 该目标的左上角宽度方向坐标 ymin 该目标的左上角高度方向坐标 xmax 该目标的右下角宽度方向坐标 ymax 该目标的右下角高度方向坐标
评估指标
评测方式采用计算mAP(IoU = 0.5)的方式。首先计算每个类的AP:
根据预测框和标注框的IoU是否达到阈值0.5判断该预测框是真阳性还是假阳性; 每个预测框的置信度进行从高到低排序; 计算精确率和召回率,计算PR值; 绘制PR曲线并计算AP值。 然后计算mAP:把所有类的AP值求平均得到mAP。
作品提交要求
选手需要提交json格式文件,详情见示例。其中,坐标值必须为大于0的正数且不能超过图像的宽高。
按照赛题数据页面2022gamedatasettest1.txt里面的顺序组织json
提交文件需按序排列,首先按图片顺序排列,然后按类别顺序排列,置信度顺序随意。图片顺序,请按照图片编号顺序。

(b) 类别顺序,请参照下列顺序:{'knife': 1, 'scissors': 2, 'lighter': 3, 'USBFlashDisk': 4, 'pressure': 5, 'plasticBottleWithaNozzle': 6, 'seal': 7, 'battery': 8}
初赛结束后进入决赛的选手需要提交模型文件和详细的实验过程说明文档。其中,模型大小不能超过600MB,鼓励使用模型压缩和轻量化方法,并酌情加分;提交的模型须为单模型,禁止使用多模型融合方法;说明文档须实事求是、清晰明了,本领域研究者可据此复现结果。建议参赛者在参加初赛过程中记录实验过程。
数据下载
| 文件名 | 下载 |
|---|---|
| X光安检图像检测挑战赛2022一阶段公开数据.zip | 点击下载 |
| 2022gamedatasettest1.txt | 点击下载 |
解题过程
赛题是一个典型的物体检测赛题,接下来我们讲解具体的训练和解题过程。我们选择使用YOLOV5来训练和进行预测。
步骤1:读取并转换数据集
首先我们需要读取所有的图片路径,并尝试将图片转换为YOLO格式。
train_anns = glob.glob('讯飞研究院-X光安检图像检测挑战赛2022公开数据/训练集/*/XML/*.xml')
train_paths = glob.glob('讯飞研究院-X光安检图像检测挑战赛2022公开数据/训练集/*/*.jpg')
Yolo标注格式保存在.txt文件中,一共5个数据,用空格隔开,举例说明如下图所示:
假设图像的高和宽分别为h, w,bbox的左上角坐标为(x1, y2),右下角坐标为(x2, y2),则可求得bbox中心坐标(x_c, y_c)为:
假设Yolo的5个数据分别为:, , , , ,则有对应关系:
具体的从XML转换为Yolo格式的代码为:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
classes = ["knife", 'scissors', 'lighter', 'USBFlashDisk', 'pressure', 'plasticBottleWithaNozzle', 'seal', 'battery'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(in_path, out_path):
in_file = open(in_path, encoding='UTF-8')
out_file = open(out_path, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
存储的数据文件夹参考:
- xray
-image
- train#存放训练图片
- x.jpg
- val##存放验证图片
-label
- train#存放训练label
- x.txt
- val#存放验证label
步骤2:定义yaml
在Yolo中数据集(需要提前下载https://github.com/ultralytics/yolov5)配置通过yaml格式给出,可以参考如下的格式:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/xray # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # train images (relative to 'path') 128 images
# Classes
nc: 8 # number of classes
names: ["knife", 'scissors', 'lighter', 'USBFlashDisk', 'pressure', 'plasticBottleWithaNozzle', 'seal', 'battery'] # class names
注意此时的yaml里面的path需要xray文件夹写为相对路径。
步骤3:训练模型
batch:训练时batch size epoch:训练轮数 data:yaml文件路径
python3 train.py --img 640 --batch 2 --epochs 30 --data data/xunfei-xray2022.yaml --weights yolov5x.pt
步骤4:模型预测
save-txt:表示将预测结果写为txt
python3 detect.py --weights runs/train/exp7/weights/best.pt --source test1/domain1/ --save-txt
最终将预测结果转换为比赛需要的json格式即可,比赛的json格式为制定文件顺序,并在每个文件的列表内部写每个类别的预测结果。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码