
学习大数据从安装Hadoop开始(单机版)
共 4096字,需浏览 9分钟
·
2021-12-27 14:36
文章已收录到我的Github精选,欢迎Star:https://github.com/yehongzhi/learningSummary
前言
最近上手学习大数据,大数据当然离不开核心的Hadoop,所以首先要搭建一个Hadoop环境。我本机电脑配置不太高,又是学习阶段,所以就整个单机版的玩玩,下面记录一下步骤,希望对大家有所帮助。
前期准备
| 名称 | 版本 | 来源 |
|---|---|---|
| 虚拟机CentOS | CentOS 7 | 略 |
| JDK | 1.8 | Oracle官网 |
| hadoop | 3.2.2 | hadoop官网 |
虚拟机安装,和JDK安装就不多说了,对于做Java开发的来说都是小菜一碟。
关闭防火墙
要关闭防火墙首先得看开没开,查看防火墙状态,使用命令systemctl status firewalld.service。
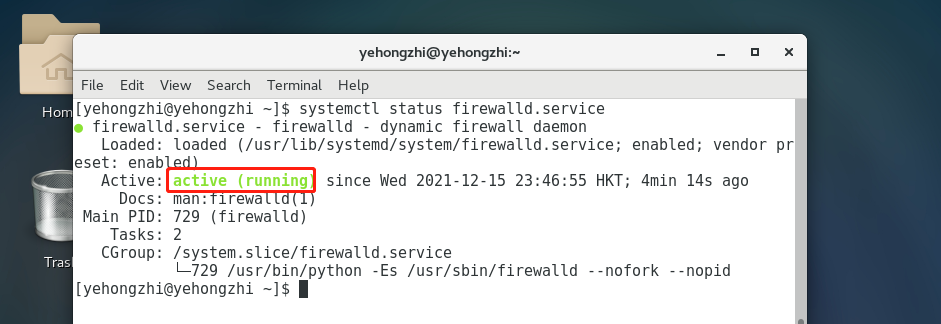
得先用su root,切换到root,然后使用关闭防火墙命令systemctl status firewalld.service。关了之后在查看状态,如图所示已经关闭了。

但是如果重新开机还是会自动启动,所以要设置开机禁止防火墙。使用命令systemctl disable firewalld.service。相反,开机启动防火墙就是systemctl enable firewalld.service。
设置静态IP
为什么要设置静态IP呢,因为有时候虚拟机设置的网络IP地址是自动分配的,自动分配的IP问题就出在每次启动虚拟机的时候会随机分配一个IP,这个IP是不固定的,那么当我们用远程工具连接的时候就很不方便,每次都得先使用命令ip addr查询虚拟机的IP地址。
废话不多说,打开vim /etc/sysconfig/network-scripts/ifcfg-enp0s3文件编辑。
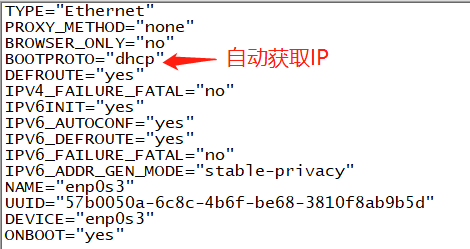
上面这个就是自动获取IP地址的配置,怎么改成静态IP呢?很简单,看下面配置。
1)BOOTPROTO="static"
2)ONBOOT="yes"
3)配置IPADDR、NETMASK、GATEWAY、DNS1、DNS2。
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="enp0s3"
UUID="57b0050a-6c8c-4b6f-be68-3810f8ab9b5d"
DEVICE="enp0s3"
ONBOOT="yes"
IPADDR=192.168.1.4
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=119.29.29.29
DNS2=8.8.8.8
接着重新加载systemctl restart network。
然后验证的话,可以输入ip addr命令查看一下IP地址。最后ping一下百度,看网络是否通畅。
关闭selinux服务
打开vim /etc/selinux/config编辑文件,修改如下配置:
SELINUX=disabled
重启服务器生效,命令为reboot。
修改主机名
修改主机名+域名映射,在访问的时候就可以不用IP地址而用域名,方便很多。
使用命令vim /ect/hostname,修改主机名为hadooptest100。
域名映射,使用命令vim /ect/hosts,修改以下配置:
192.168.1.4 hadooptest100
接着重启服务器生效。
设置SSH免密登录
执行以下命令。
ssh-keygen -t rsa
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
chmod 700 /home/hadoop/.ssh
chmod 600 /home/hadoop/.ssh/authorized_keys
使用ssh localhost验证,如果不需要密码即可登录则表示设置成功。使用exit命令退出登录。
安装Hadoop
首先把压缩包放在usr/local/目录下,然后解压tar -zxvf /usr/local/hadoop-3.2.2。

配置环境变量
使用命令vim /etc/profile编辑,在末尾加上:
export JAVA_HOME=/usr/local/jdk1.8.0_161
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop-3.2.2
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS=-Djava.library.path=$HADOOP_HOME/lib
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
wq保存退出之后,使用命令source /etc/profile重新加载配置。最后我们使用hadoop version验证。

核心文件设置
进入到hadoop安装目录的${HADOOP_HOME}/etc/hadoop/目录,设置core-site.xml文件:
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/hadoop/data/tmpvalue>
<description>hadoop tmp dirdescription>
property>
<property>
<name>fs.default.namename>
<value>hdfs://hadooptest100:9000value>
property>
configuration>
设置hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
<description>设置副本数description>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///hadoop/data/dfs/namevalue>
<description>nameNodedescription>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///hadoop/data/dfs/datavalue>
<description>dataNodedescription>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
<description>permissiondescription>
property>
<property>
<name>dfs.secondary.http.addressname>
<value>hadooptest100:50070value>
<description>SNN pathdescription>
property>
configuration>
设置mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
设置yarn-site.xml文件:
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hosttest100value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
设置hadoop_evn.sh文件:
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/usr/local/jdk1.8.0_161
export HADOOP_HOME=/usr/local/hadoop-3.2.2
cd到sbin目录下,设置start-dfs.sh、stop-dfs.sh文件,在前面加上:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
设置start-yarn.sh、stop-yarn.sh文件,在前面加上:
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=yarn
YARN_NODEMANAGER_USER=root
启动hadoop
首先需要格式化,切换到bin目录下,使用以下命令。
hdfs namenode -format
接着就cd到sbin目录下,使用命令./start-all.sh一键启动hadoop。
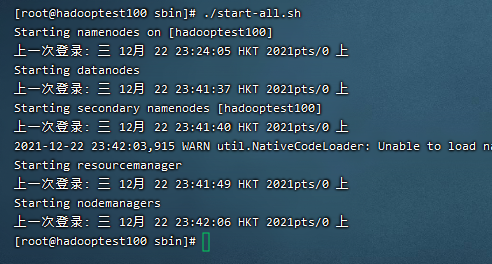
然后使用jps命令查看java进程。
[root@hadooptest100 sbin]# jps
24530 NameNode
24738 DataNode
25198 SecondaryNameNode
26110 NodeManager
1918 Jps
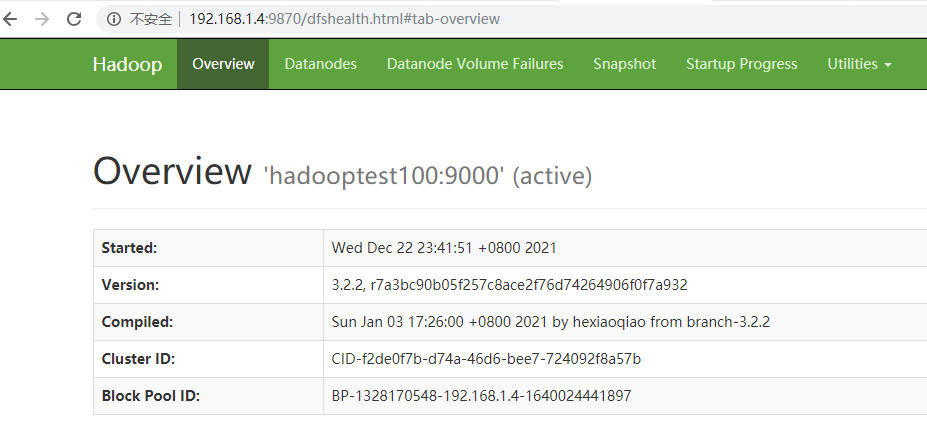
最后可以在浏览器输入hadoop服务器的ip加上9870端口号,访问hadoop的管理界面。
总结
这里需要说明的是,我是为了方便才使用root用户部署hadoop,在生产环境切记不可使用root用户。所谓万事开头难,部署完hadoop环境之后,下一步我们就可以学习MapReduce了。感谢大家的阅读,希望能对你有所帮助。
觉得有用就点个赞吧,你的点赞是我创作的最大动力~
我是一个努力让大家记住的程序员。我们下期再见!!!
能力有限,如果有什么错误或者不当之处,请大家批评指正,一起学习交流!