
蒙特利尔骑行数据分析 小案例
三步加星标
你好,我是 zhenguo
Python 领域,数据分析的利器非 Pandas 莫属,关于它的基本原理、数据结构和 API,之前总结过不少这类文章。结合施工专题,这阶段先总结数据分析的实践相关话题,直接使用实际数据分析,解决实际问题。
今天参考github中的一个Pandas练习,来做一把蒙特利尔的自行车骑行数据分析。
导入使用的包:
import pandas as pd
import matplotlib.pyplot as plt
读入数据:
fixed_df = pd.read_csv('../data/bikes.csv', sep=';',
encoding='latin1', parse_dates=['Date'],
dayfirst=True, index_col='Date')
fixed_df[:3]
注意read_csv的几个参数:
此数据集使用;分割,
编码方式为 latin1,parse_dates 参数表示解析哪些列为日期类型,
dayfirst参数是欧洲常用的一种时间格式,
index_col 参数指定使用Date作为行索引
展示Berri 1列,返回Series类型,Pandas表达键值对的一种数据结构,类似字典。
因为数据读入时,指定Date为行索引,输出结果时可以看到。键的值表示当天骑自行车出行人数:
fixed_df['Berri 1']
结果为:
Date
2012-01-01 35
2012-01-02 83
2012-01-03 135
2012-01-04 144
2012-01-05 197
...
2012-11-01 2405
2012-11-02 1582
2012-11-03 844
2012-11-04 966
2012-11-05 2247
Name: Berri 1, Length: 310, dtype: int64
画画日期与骑自行车出行人数的折线图,此出直接使用Series自带的 plot 方法,绘制 Berri 1 地区的骑行数据折线图:
fixed_df['Berri 1'].plot()
绘制的折线图如下:
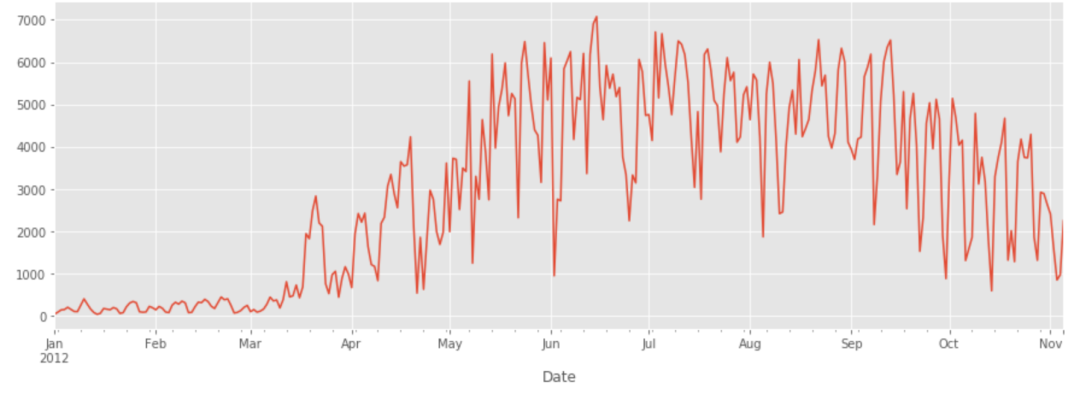
看到1月、2月骑自行车出行人数不多。
实际上,我们可以直接绘制蒙特利尔所有地方的骑行数据:
fixed_df.plot(figsize=(15, 10))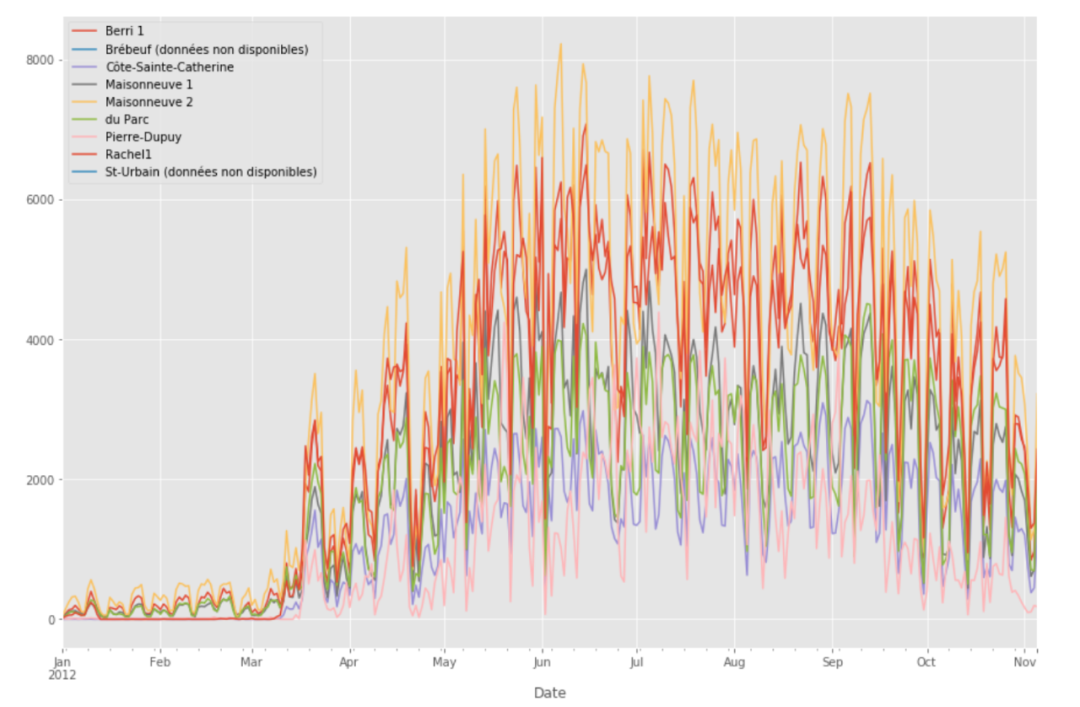
上图观察看到,如果某天骑行人数少,所有地区的情况就都会少。
以上就是导入数据后的一个简单数据分析,如果你有兴趣,获取数据和源码,微信我备注:骑行
评论