
万字长文讲透AI艺术:缘起、意义和未来(下篇)


作者| 刘秋杉 来源 | 巴比特资讯 排版 | 王纪珑琰
前言
AI 艺术更为直接的是一场新消费变革,但以未来为终局,其必将是一场新技术变革,这是自十多年前移动互联网革命以来久违的一幕,让开源生态点燃的这星星之火燃遍新十年创业的每个角落。与区块链引领的加密变革稍有不同,AIGC(AI 艺术所归属的大类)带给人们的兴奋感并不来自纯金融和财富预期(“多巴胺”),更多的是发自人类内心本质的对崭新未来的渴望,那是一种真正的“内啡肽”。
未来:技术为王
由于当前最大的开源生态是以 SD 为导向,因此本文所谈论的技术动向皆来自于 SD 大生态。MJ 在算法本质上与 SD 同宗同源且大同小异,其关键为不断进化的数据集和美学算法增强,期待 MJ 开源的那一日,与世人共享其普惠万物的力量。
(一)二次元模型开辟可商用垂直模型先河
以 NovelAI Diffusion、Waifu Diffusion、trinart 等为代表的二次元模型以其惊人的“平图”效果极大地拓展了 SD 模型和生态的想象空间,其近乎可商业化的使用体验也开辟了“万物皆可垂直”的垂直模型先河,弥补了像 SD 这种大通用模型在个别美学领域的“力不从心”。当然在这个过程中也是伴随着诟病、质疑和抨击,但商业与技术应该一分为二去看待。
以 NovelAI Diffusion 为例
由原本做 AIGC 生成小说内容的商业实体 Novel 推出,基于 SD 算法框架和 Danbooru 二次元图库数据集进行训练和优化,被外网称为“最强二次元生成模型”。除去手部细节,NovelAI 的出图质量可谓上乘。最大的功劳来自 Danbooru,是一个二次元图片堆图网站,会标注画师名、原作、角色,以及像文字描述一遍画面内容的详细 tag(可能会详细到角色的发型发色、外貌特征、服装、姿势表情、包含一些其他可识别内容的程度),而这些对扩散模型的训练尤为重要,省去了大量的人工筛选标注工作。Danbooru 的商业定位也给了 NovelAI “可乘之机”:根据搜索结果内容量来看,这个网站是其他用户自发保存(例如在推上有一些热度的绘画作品)并上传上去的,所以在日本一直有这个网站无授权转载的争议。关于这次 AI 学习素材库的事情,Danbooru方面也有做出回应:与包括NovelAI 在内的 AI 作画网站没什么关系,且不认可他们的行为。
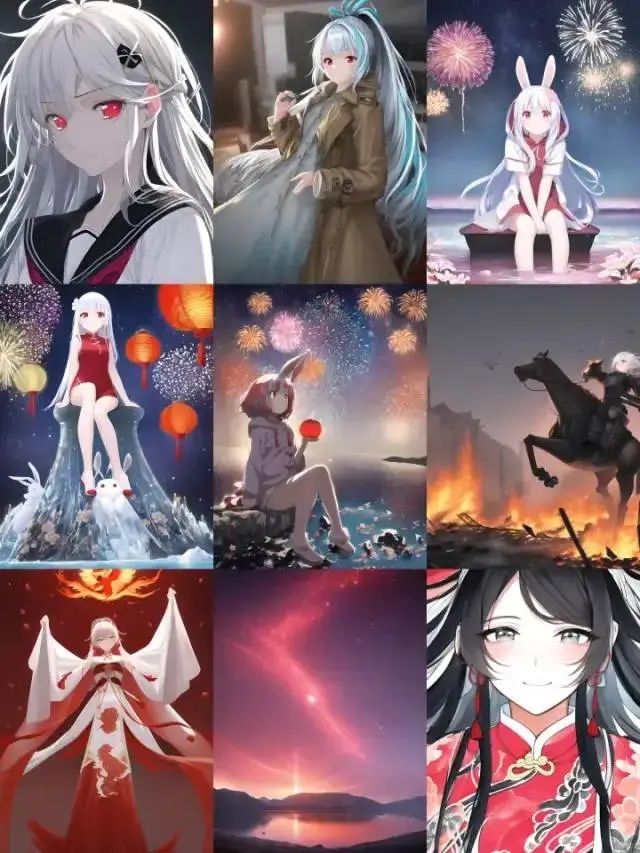
但从正面意义来看,NovelAI 的确也在技术上给 SD 带来了新的空间,就连 StabilityAI 的老板 Emad 也在推特上宣传到:“NovelAI 的技术工作是对 SD 极大的提升,包括手指修复、任意分辨率等等。”对技术感兴趣的可以看一看官方博客blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac中对 SD 的改进工作,大致是修改了 SD 模型架构及训练过程。

像 NovelAI 这类的二次元模型对于用户输入的描述词的专业程度要求较高,如下所示:
colorful painting, ((chinese colorful ink)), (((Chinese color ink painting style))), (((masterpiece))), (((best quality))),((Ultra-detailed, very precise detailed)),
(((a charming Chinese girl,1girl,solo,delicate beautiful face))), (Floating),(illustration),(Amazing),(Absurd),((sharp focus)), ((extremely detailed)), ((high saturation)), (surrounded by color ink splashes),((extremely detailed body)),((colorful))
不仅需要描述人物,更是要对人物的二次元细节进行刻画,甚至还要加一些有助于画质增强的词汇,这一系列操作被网友戏称为“咒语”,就像要进入一个二次元世界一般,首先你要学会“念咒”。好在社区力量是无限的,陆续出现了很多“宝典”,如《元素法典》元素法典——Novel AI 元素魔法全收录docs.qq.com/doc/DWHl3am5Zb05QbGVs和元素法典 第二卷——Novel AI 元素魔法全收录docs.qq.com/doc/DWEpNdERNbnBRZWNL,将二次元的“心法口诀”公诸于众,且全民共创,这很“二次元”。
(二)AI 画二次元漫画逐渐可行
二次元模型对于画特定形象的人物十分擅长,比如在如下的连续出图中,我们大致可以认为都是一个“主人公”(称之为白小苏苏)在变 Pose 或者换装。因为我们给予 AI 的描述中对该人物进行了极为细致的刻画,就像固定了她的基因一般,加上二次元模型本身对于人物的勾画(平图)相对于真实人物就“粗放”一些,只要重要人物特征一致,便可以判别为同一个人。

{profile picture},{an extremely delicate and beautiful girl}, cg 8k wallpaper, masterpiece, cold expression, handsome, upper body, looking at viewer, school uniform, sailor suit, insanity, white hair, messy long hair, red eyes, beautiful detailed eyes {{a black cross hairpin}}, handsome,Hair glows,dramatic angle
直译为:
{头像},{一个极其精致美丽的女孩},cg 8k墙纸,杰作,冷漠的表情,英俊,上半身,看着观众,校服,水手服,疯狂,白发,凌乱的长发,红色的眼睛,美丽细致的眼睛{{一个黑色的十字发夹}},英俊,头发发光,戏剧性的角度

于是进一步的,可以通过“底图模式”去约束人物的动作表达或者情节表达,再配上同样的人物特征关键词描述,便可以输出该人物动漫剧情般的“生命周期”,她不再活在一幅图中。何为“底图”控制,如下所示:

图片来源:wuhu动画人空间《AI 随便画画就在二次元绘画区杀疯了?!》

图片来源:wuhu动画人空间《AI 随便画画就在二次元绘画区杀疯了?!》
最后再配上文字、漫画格式框,稍微经过 PS 整合,便能出来一幅像模像样的漫画了。

当然上述都是基于现在 AI 模型的发展所提出的“妥协”手段,实际上我们在画二次元漫画时应该追求绝对的主人公一致性(真正是同一个人物)和更为精准的动作控制、背景控制甚至数量控制和表情控制等等,而这些都需要借助更为先进的技术,即如下所要讲述的模型训练和以交叉注意力为代表的精准控制技术。
(三)开放模型训练催生“万物皆可垂直”
随着二次元模型的成功流行,人们也越来越渴望更多类似的模型出现,以解决五花八门的创作需求。一个中心化的商业平台便需要做出一个大而全的产品以迎合用户需求,但面对指数级的市场增长,这显然是不现实的。最佳解决办法便是交给一个去中心化的自组织生态,像迸发二次元模型一样实现模型的“涌现”,去解决人们日益增长的创作需求。这便特别需要一种开放模型的力量,而 SD 在开源之处便将这种力量完全交给了所有人,每个人都可以去获得算法模型,都可以去训练自己的模型。于是,创作无限,模型涌现!
模型训练技术分 Checkpoint Merger(检查点合并)、Textual Inversion(Embedding 嵌入模型)、Hypernetwork(超网络模型)、Aesthetic Gradient(审美梯度)以及重量级的 Dreambooth 等。其中以 Textual Inversion 和 Dreambooth 最为流行,分别有着不同的技术原理和优势。

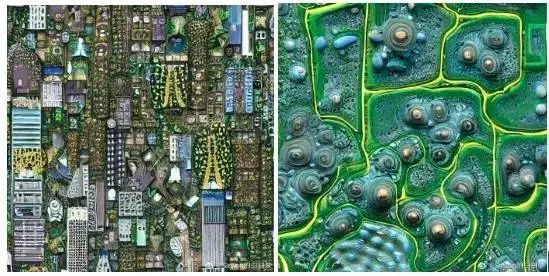
知名博主“Simon 的白日梦“在微博分享了自己使用 SD 的 Textual Inversion 技术训练的“黏菌卫星图”案例。首先需要准备训练数据集,大概一万张卫星地图;我们都知道 SD 模型本身要么只能单独出城市卫星图,要么只能出黏菌图;博主通过 Textual Inversion 再次训练之后,成功地把城市卫星图肌理和黏菌的微观结构融合在了一起。
再分享另外一个知名博主“大谷 Spitzer”使用 Textual Inversion 进行“分镜设计”的案例。我们在上面提到要做二次元漫画离不开固定主人公形象,所谓分镜设计便是能否用 AI 绘制出独特且相貌保持连续性的动漫角色。大谷用 Textual Inversion + 自制数据集训练了 6、7 种不同的相貌作为脸部基因。之后在输入给 AI 的文字中,即可通过改变训练好的几个相貌 tag 的比例权重,融合出现实里不存在,同时在系列图片里长相可以保持一致的角色。如下两幅图便是不同比例权重下出现的两位“主人公”,而对于同一位主人公,可以通过 AI 让其出现在各种各样的场景。比如“太空之声”里的女孩是同一个形象的不同故事表达,而“都市探员”里的主人公肤色更深、形象健硕,真的像一名探员。


在具体操作上,正如“Simon 的白日梦”所说:
当你输入一个模型中没有的概念,例如生成一个“Simon 的白日梦 up 主的照片”,因为 sd 模型没有见过我,自然不能生成我的照片。但是注意,其实 sd 模型中是具备生成我的照片的所有要素的的能力,毕竟我只是一个普通的中国技术宅,模型中应该有不少亚洲人的特征可以用于合成。
那这时候给出几张我的照片(坐标也可以通过编码图片获得),对比刚才说的文字提示,训练 textual inversion,其实是告诉模型“我是谁”,从而获得根据我的文字提示获得一个更准确的坐标。因此,训练完后,我们会发现并没有生成新的模型 ckpt 文件,而是得到了一个几十 k 大小的 .pt 文件,然后下次启动 stable diffuison webui 的时候就可以挂载这个文件,当我下次再输入“Simon 的白日梦 up 主的照片”这段文字的时候,模型就会读取这个 .pt 文件里边的准确坐标,并和其它文字描述包含的坐标融合,然后生成更符合文字描述的图片。
社区也在利用 Textual Inversion 为二次元模型丰富其尚不能绘制的形象,比如很多国产动漫角色,如秦时明月。只要有合法的数据集,技术都是现成的,通过算力让人物形象在 AI 的世界“凝聚”。
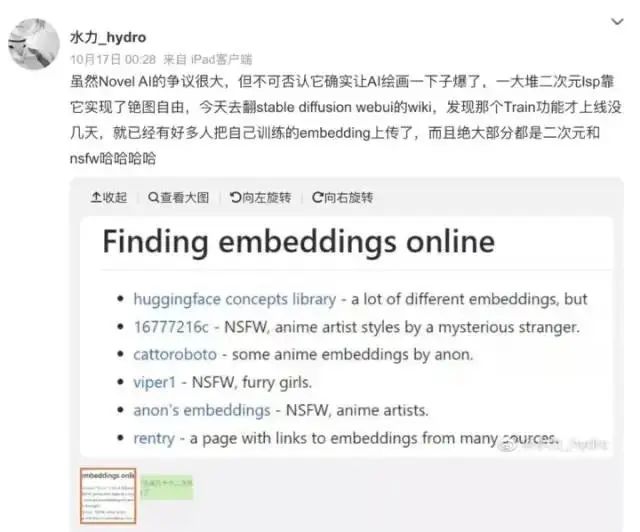
embedding即为Textual Inversion
Textual Inversion 的优势是轻量级、简单上手。它可以对主体(object)进行训练,让 AI 记住这个“人”或“物”,也可以对画风(style)进行训练,比如可以记住某位在世艺术家的画风然后让 AI 以此画风来画任何事物;训练出的模型文件可以直接挂载到 SD 模型框架中,类似 Linux 开放时代不断完善的动态连接库,因此对 SD 也是友好的。但劣势是,效果较为粗糙,目前尚未有可以进入商业化产品效果的模型出现,社区更多期待给予了另外一项技术——Dreambooth。
相较于 Textual Inversion 等在 SD 框架上的增添,Dreambooth 是直接调整整个 SD 模型本身,SD 模型是一个大概 4G 左右的 ckpt 文件,经过 Dreambooth 重训模型后,会生成一个新的 ckpt 文件,是一种深度融合。因此 Dreambooth 的训练会更为复杂苛刻。
由于 dreambooth 会将训练对模型的影响锁定在某一种物体的类别内,所以训练的时候不仅需要描述的文字、对应图片,还需要告诉模型你训练的物体的类别(训练完使用的时候,也要同时在 prompt 中包含类别和 token 关键字),并且用训练前的模型先生成一系列这一种类物体的正则化图片(regularization image)用于后续和你给的图片做半监督训练。所以,生成正则化图片要消耗额外的图片(一般要 1K+,但是可以用别人生成好的);训练的时候因为是调整整个模型(即便只是模型中的部分参数),对算力和时间要求也比较高。我在本地一块 3090 上训练时显存占用达到 23.7G,训练 10K 张 10000epoch 需要 4 个半小时。
—— Simon 的白日梦

黏菌卫星图模型两种训练效果对比,dreambooth更胜一筹
再回到二次元这个话题,同样有大 V 利用 Dreambooth 训练出了一个赛博风的二次元模型——Cyberpunk Anime Diffusion,由“大谷 Spitzer”开发,现已开源。
Cyberpunk Anime Diffusion开源huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion



 Dreambooth技术最早来自google论文,此为论文中的案例,一只现实小狗无限艺术分镜
Dreambooth技术最早来自google论文,此为论文中的案例,一只现实小狗无限艺术分镜




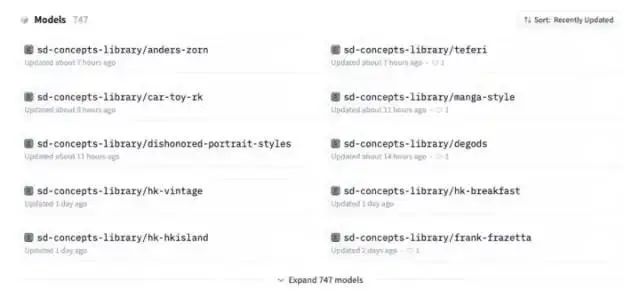 社区基于 Dreambooth 训练的模型大全开源库——
社区基于 Dreambooth 训练的模型大全开源库——
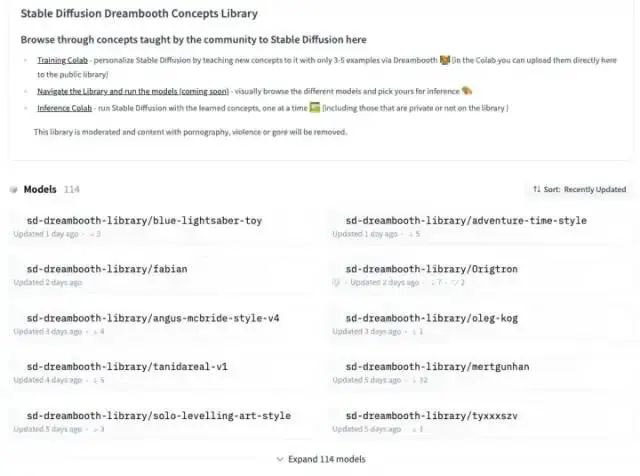
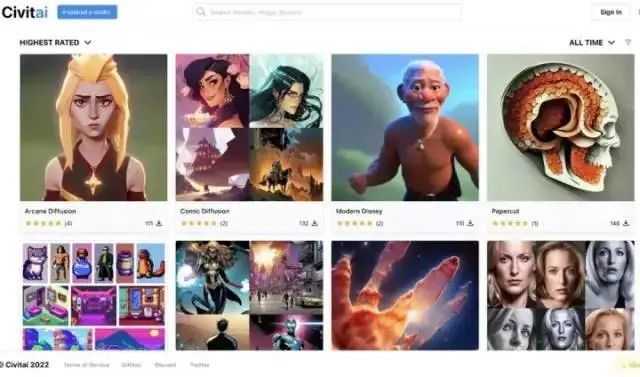


https://github.com/nousr/robo-diffusion
(四)交叉注意力实现画面的精准控制
开放模型的出现给予了降维解决一切难题的方式,真正实现了“创造”二字。与此同时,也不能忽略一些辅助技术的发展,还是拿二次元漫画为例,我们不免要对一些更细节的绘制表现进行控制。如下,我们希望保留汽车和树木背景,但改变在它上面的“主人公”;或者将一幅现实照片进行漫画风格的变化,以做漫画叙事背景设计。


开源连接——
Cross Attention Controlgithub.com/bloc97/CrossAttentionControl/blob/main/CrossAttention_Release.ipynb
这就是所谓的交叉注意力控制(Cross-Attention Control)技术,连 StabilityAI 创始人也不禁为这项技术点赞:“在类似技术帮助下,你可以去创造任何你梦想的事物。”
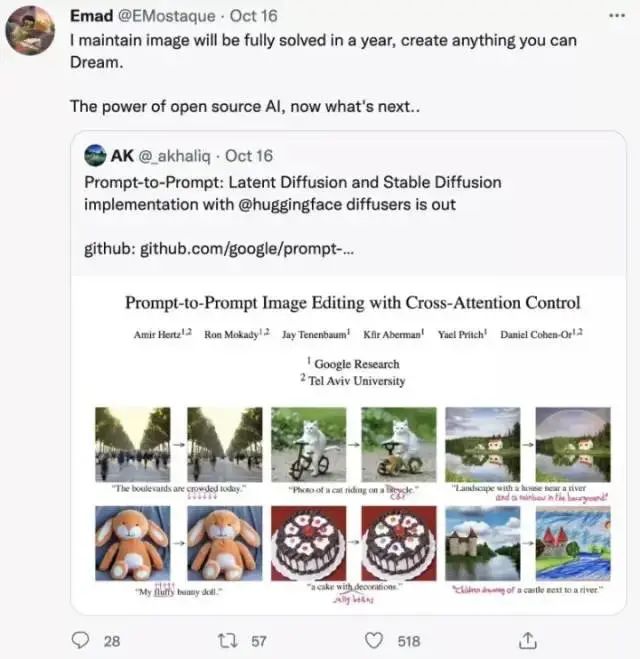
该项目开源连接——
GitHub - google/prompt-to-promptgithub.com/google/prompt-to-prompt
在这个项目 demo 中,可以改变主人公“小猫”的坐骑,可以给背景画一道彩虹,可以让拥挤的路上变得空旷。在如下类似的研究项目中,还可以做到让主人公竖大拇指、让两只鸟 kiss、让一个香蕉变两个。


不论是【Imagic】还是【Prompt-to-Prompt】,精准控制技术对于实现 AI 绘图的自主可控十分重要,也是构建二次元漫画体系比较重要的技术动向之一,目前尚处于行业研究前沿。
(五)精准控制系列之 Inpainting 和 Outpainting
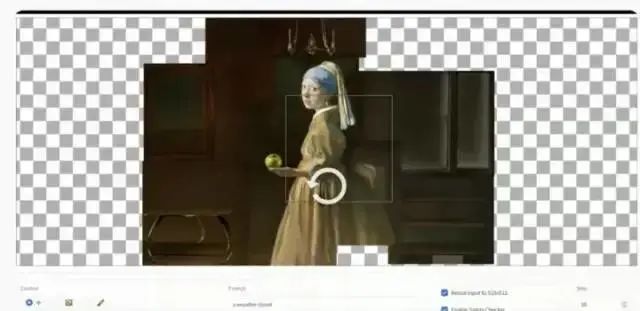
说到了精准控制,它不是某一项技术,交叉注意力是其一,还有很多辅助性手段为其服务,最为流行和商业成熟的是 inpainting 和 outpainting 技术。这是传统设计领域的概念,AI 艺术也继承了过来。当前 SD 也推出了 inpainting 功能,可翻译为“涂抹”,即对于画面中不满意的部分进行“涂抹”,然后 AI 会在涂抹区重新生成想要替换的内容,具体见下图操作。


开源地址——
Runway MLgithub.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion
同样以二次元漫画这个终极追求为例,当需要给女主人公增加一位帅气的男士时,便可以在她旁边区域进行涂抹,然后附上一段霸道总裁的关键词 prompt,AI 便会给女主一段“姻缘”。
另外一项技术 outpainting,被誉为“无限画布”,最早出现在 Dalle2 的商业产品体系中,当时也是震惊世人。简单来讲,将一张需要扩展的图上传给 AI,outpainting 便会在这张图的四周扩展出“无限的”画布,至于填充什么内容,也完全交给用户自己输入的 prompt 决定,无限画布,无限想象空间。如下利用 outpainting 为一幅经典名画填充了大量背景,产生了令人惊喜的效果。如今 SD 生态也拥有了自己的 outpainting 技术,开源地址——
Stablediffusion Infinity - a Hugging Face Space by lnyanhuggingface.co/spaces/lnyan/stablediffusion-infinity?continueFlag=27a69883d2968479d88dcb66f1c58316


在 outpainting 的加持下,不仅可以为一幅单调的图加无限的背景,更可以极大拓展 AI 艺术出图的尺寸,在 SD 生态一般出图为几百像素,远远不能满足大尺寸海报的需求,而 outpainting 技术便可以极大扩展 AI 艺术原生出图的尺寸。同样对于二次元漫画,甚至可以在一幅图中展现所有“参演人员”的形色百态。
(六)其他更多技术概念
除了上述重要技术外,还有很多细分技术被社区津津乐道。
可以利用 Deforum 做 SD 动画
SD动画colab.research.google.com/github/deforum/stable-diffusion/blob/main/Deforum_Stable_Diffusion.ipynb
知名博主“海辛 Hyacinth”也给出了一个完整制作 AI 动画的工作流——

prompt 逆向反推

还有一款名为 CLIP Interrogator 的工具,使用连接如下——
CLIP Interrogator - a Hugging Face Space by pharmahuggingface.co/spaces/pharma/CLIP-Interrogator


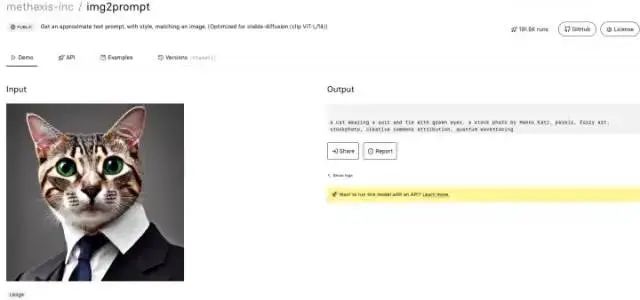
类似的还有 methexis-inc 发布的 img2prompt——
Run with an API on Replicatereplicate.com/methexis-inc/img2prompt
除了直接以图片进行反推外,还有一种工具如 Prompt Extend,可以一键加长 Prompt,可以将一个小白用户输入的“太阳”一键加长到带有丰富艺术修饰的“大神级”描述,工具地址——
Prompt Extend - a Hugging Face Space by dasparthohuggingface.co/spaces/daspartho/prompt-extend


搜索引擎
OpenArtopenart.ai/?continueFlag=df21d925f55fe34ea8eda12c78f1877d
KREA — explore great prompts.www.krea.ai/

Krea开源地址github.com/krea-ai/open-prompts
Just a moment...lexica.art/

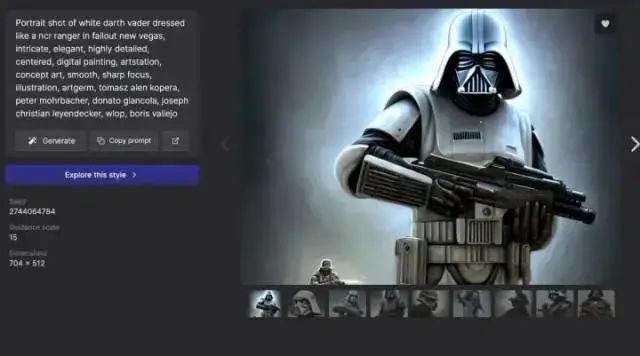
在搜索引擎中搜索自己想要的画面,便会呈现符合主题的配图及其对应的 prompt。还有不直接给 prompt 搜索,而是引导用户一步步构建 prompt 的提示性工具——
Stable Diffusion prompt Generator - promptoMANIApromptomania.com/stable-diffusion-prompt-builder/

Public Promptspublicprompts.art/
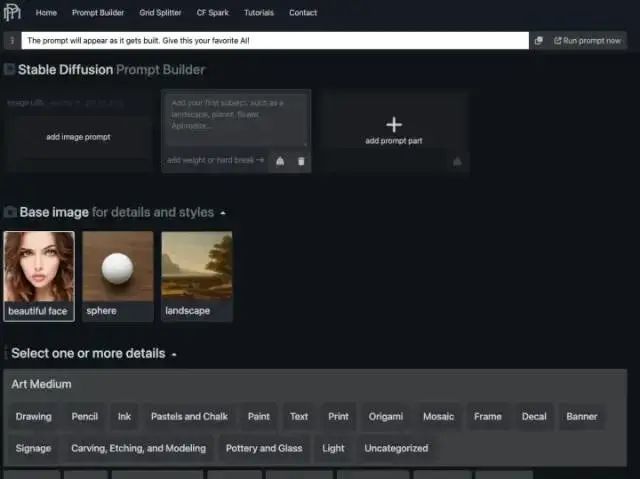
如上图,可根据网站提示,一步步构建出一幅“美丽的面孔”。在这些工具的加持下,即便从未接触过 AI 艺术的用户,在短短几天内也能逐渐摸清构建 prompt 的精髓。
(七)除了作图,更多 AI 艺术领域
text-to-3D

图片来源:量子位《Text-to-3D!建筑学小哥自称编程菜鸟,攒了个AI作画三维版,还是彩色的》
在给 AI 输入“一幅美丽的花树画,作者 Chiho Aoshima,长镜头,超现实主义”,就能瞬间得到一个长这样的花树视频,时长 13 秒。这个 text-to-3D 项目叫 dreamfields3D,现已开源——
dreamfields3Dgithub.com/shengyu-meng/dreamfields-3D
除此之外,还有个项目叫 DreamFusion,地址——
DreamFusion: Text-to-3D using 2D Diffusiondreamfusionpaper.github.io
演示视频地址video.weibo.com/show?fid=1034:4819230823219243
DreamFusion 有着较好的 3D 效果,也被 SD 生态嫁接到了 SD 实现中,开源地址——
DreamFusiongithub.com/ashawkey/stable-dreamfusion
还有 如 3DiM, 可以从单张 2D 图片直接生成 3D 模型;英伟达开源 3D 模型生成工具,GET3D——
GET3D开源地址github.com/nv-tlabs/GET3D
text-to-Video
Phenaki 演示video.weibo.com/show?fid=1034:4821392269705263
文本生成视频对技术要求极大,目前只有 google 和 meta 在争相发布体验性质的产品,知名的如 Phenaki、Imagen Video 和 Make-A-Video。其中 Phenaki 可以在 22 秒内生成一个 128*128 8fps 的长达 30 秒的短视频。而 Imagen Video 可以生成清晰度更高的视频,可达 1280*768 24fps。
text-to-Music
文本生成音乐,如项目 Dance Diffusion,试玩地址——
Dance Diffusioncolab.research.google.com/github/Harmonai-org/sample-generator/blob/main/Dance_Diffusion.ipynb#scrollTo=HHcTRGvUmoME
可以通过文本描述生成“在风声中吹口哨”、“警报器和嗡嗡作响的引擎接近后走远”等特殊声音效果。
写在最后
技术,永无止境,则 AI 艺术,永无止境。最后,以 StabilityAI 首席信息官 Daniel Jeffries 的一段话做结束——
“我们要建立一个充满活力、活跃、智能内容规则的世界,一个充满活力、你可以与之互动的数字世界,共同创造的内容,那是你的。加入到这股大潮吧,你将不再只是在未来的网络上冲浪、被动地消费内容。你将创造它!“
(注:全文已完结,分上、中、下三篇,共计 2.5 万字,将 2022 年全年对 AI 艺术的研究与创业综述总结,以飨读者。)
万字长文讲透AI艺术:缘起、意义和未来(上篇) 万字长文讲透AI艺术:缘起、意义和未来(中篇) Web 3化的迈阿密,20年前的硅谷? 字节跳动社交转向:押注元宇宙 律师解读:元宇宙仲裁第一案,仲裁适用性如何?