
2020年AI领域有哪些让人惊艳的研究?
极市平台
共 3458字,需浏览 7分钟
·
2021-01-30 22:13

极市导读
2020年AI领域涌现了许多优秀的研究成果和文章,本文为大家节选了transformer、自然语言处理、迁移学习等领域的一些令人眼前一亮的研究成果,回顾2020年AI科研界的足迹。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Switch Transformer
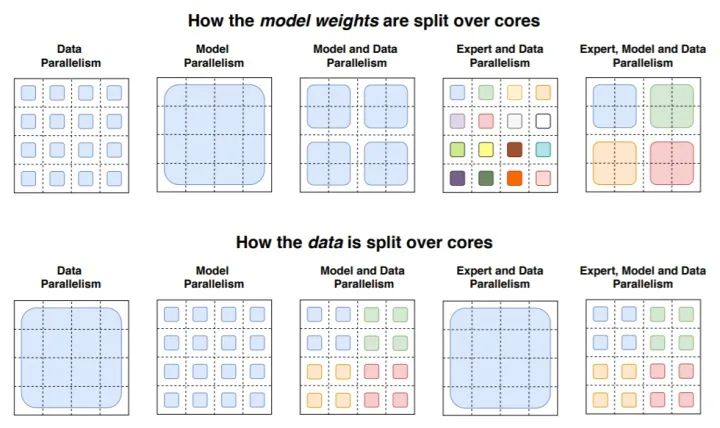
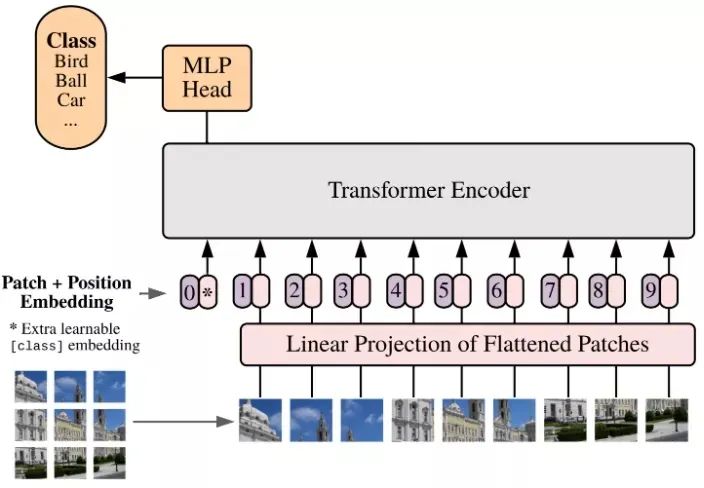
Image Transformers
Few-shot Learning

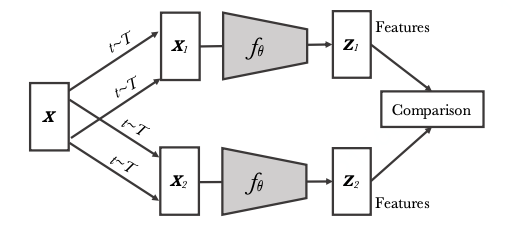
Contrastive Learning
Multilinguality

SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d'Hoffschmidt et al., 2020) Natural Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020) MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020) the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020) the CNN/Daily Mail dataset: MLSUM (Scialom et al., 2020)
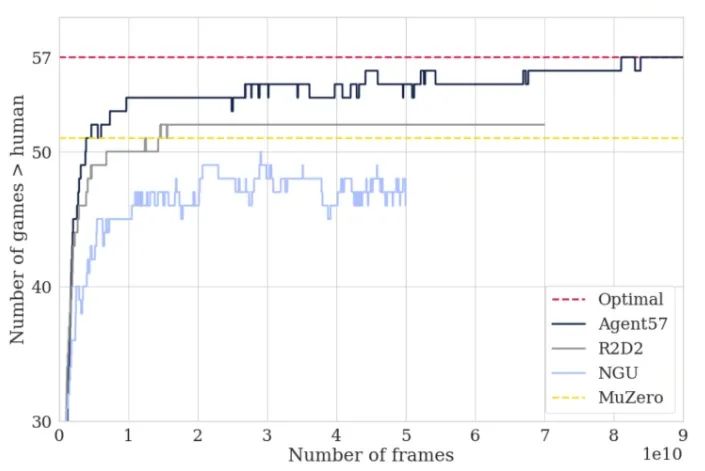
Reinforcement Learning
参考内容
2、https://ruder.io/research-highlights-2020/
推荐阅读


评论
好用的ai客服机器人有哪些?
前言:这个问题没有标准答案,LIVE800认为企业应该综合考虑自己对AI智能客服机器人的需求后,再进行选择。
每个企业对好的评价标准都不相同,因此没有百分百完美的ai智能客服机器人,只有适合的ai智能客服机器人。因此企业在选择ai智能客服机器人时,可以综合考虑,企业需求、供应商实力资质、售后服务等方面。
机器人产品上来说:Live800有智能客服机器人、智能营销机器人等机器人产品,满足企业多方面的使用需求,同时还可以根据企业的实际需求做定制开发。
如果企业看重机器人的营销价值,那么推荐使用Live800智能营销机器人
如果企业仅需要机器人做简单的回答,那么Live800智能客服机器人就足够了。
机器人功
Live800智能客服系统
0