
深入理解计算机系统(3.6)------汇编的流程控制
共 5483字,需浏览 11分钟
·
2021-04-02 11:49

前面我们所讲的所有指令,代码执行顺序都是一条接着一条顺序的执行。但是实际上在编码过程中,会有某些结构,比如条件语句(if-else),循环语句(for,do-while)和分支语句(switch)等等,都要求有条件的执行,根据数据测试的结果来决定操作执行的顺序。
在机器代码中,提供两种基本的低级机制来实现有条件的行为:测试数据值,然后根据测试的结果来改变控制流或者数据流。
那么本篇博客我们就来详细介绍在汇编语言中的流程控制。
1、条件码
前面我们在 操作数指示符和数据传送指令 中介绍了整数寄存器,在 32位 CPU 中包含一组 8 个存储 32 位值的寄存器,即整数寄存器。它可以存储一些地址或者整数的数据,有的用来记录某些重要的程序状态,有的则用来保存临时数据。
而这里我们要介绍的是条件码(condition code)寄存器。它与整数寄存器不同,它是由单个位组成的寄存器,也就是它们当中的值只能为 0 或者 1。当有算术与逻辑操作发生时,这些条件码寄存器当中的值会相应的发生变化。
也就是说可以检测这些寄存器来执行条件分支指令。常用的条件码如下:
①、CF:进位标志寄存器。最近的操作是最高位产生了进位。它可以记录无符号操作的溢出,当溢出时会被设为1。
②、ZF:零标志寄存器,最近的操作得出的结果为0。当计算结果为0时将会被设为1。
③、SF:符号标志寄存器,最近的操作得到的结果为负数。当计算结果为负数时会被设为1。
④、OF:溢出标志寄存器,最近的操作导致一个补码溢出(正溢出或负溢出)。当计算结果导致了补码溢出时,会被设为1。
从上面可以看出,CF和OF可以判断有符号和补码的溢出,ZF判断结果是否为0,SF判断结果的符号。这是底层机器的设定,而我们所编程用的高级语言(比如C,Java)就是靠这四个寄存器,演化出各种各样的流程控制。
2、设置条件码
通常情况下,条件码寄存器的值无法主动被改变,它们大多时候是被动改变,这算是条件码寄存器的特色。这其实理解起来并不困难,因为条件码寄存器是1位的,而我们的数据格式最低为b,也就是8位,因此你无法使用任何数据传送指令去传送一个单个位的值。
几乎所有的算术与逻辑指令都会改变条件码寄存器的值,不过改变的前提是触发了条件码寄存器的条件。比如对于subl %edx,%eax这个减法指令,假设%edx和%eax寄存器的值都为0x10,则两者相减的结果为0,此时ZF寄存器将会被自动设为1。对于其它的指令运算,都是类似的,会根据结果的不同而设置不同的条件码寄存器。
这里我们需要说明的是,leal 指令作为地址计算的时候,是不改变任何条件码的。
前面我们所讲的算术逻辑指令,在改变整数寄存器的值后,会根据结果设置不同的条件码。而这里还有另外两种指令,它们只设置条件码,而不改变任何其他寄存器的值。如下图:
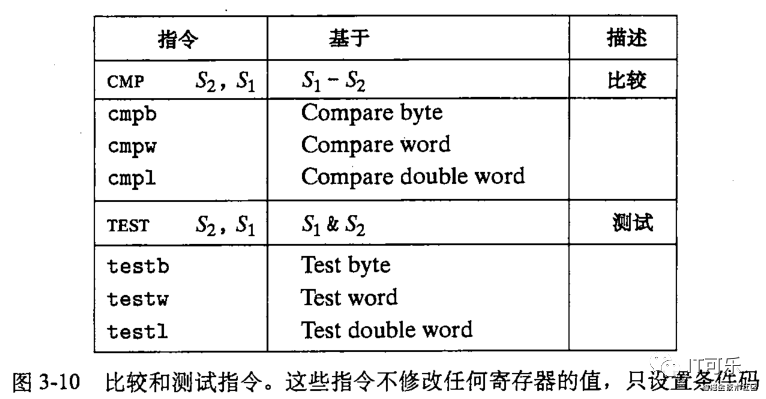 ①、CMP 指令,指令形式 CMP S2,S1。然后会根据 S1-S2 的差来设置条件码。除了只设置条件码而不更新目标寄存器外,CMP 指令和 SUB 指令的行为是一样的。比如两个操作数相等,那么之差为0,那么就会将零标志设置为 1;其他的标志也可以用来确定两个数的大小关系。
①、CMP 指令,指令形式 CMP S2,S1。然后会根据 S1-S2 的差来设置条件码。除了只设置条件码而不更新目标寄存器外,CMP 指令和 SUB 指令的行为是一样的。比如两个操作数相等,那么之差为0,那么就会将零标志设置为 1;其他的标志也可以用来确定两个数的大小关系。
②、TEST 指令,和 AND 指令一样,除了TEST指令只设置条件码而不改变目的寄存器的值。比如对于如下指令:
MOV AL,40H
TESTB AL,08H
上面的指令就是用来测试 AL 寄存器的左起第四位是否为0,结果就是 0100 0000(40H)& 0000 1000(08H),测试结果左起第4位是0,所以各个标志位:CF=0,OF=0,SF=0,ZF=1
3、访问条件码
对于普通寄存器来讲,使用的时候一般是直接读取它的值,而对于条件码,通常不会直接读取。常用的有如下三种方法:
①、可以根据条件码寄存器的某个组合,将一个字节设置为0或1。
②、可以直接条件跳转到程序的某个其它的部分。
③、可以有条件的传送数据。
对于第一种情况,下图描述的指令便是根据条件码的某个组合,将一个字节设置为0或1,这一整类指令称为 SET 指令,它们的区别就在与它们考虑的条件码的组合是什么,这些指令名字的不同后缀指明了它们所考虑的条件码的组合。
注意:这些指令的后缀表示不同的条件而不是操作数的大小。比如指令 setl 和 setb 表示 “小于时设置(set less)”和“低于时设置(set below)”,而不是“设置长字(set long word)”和“设置字节(set byte)”。
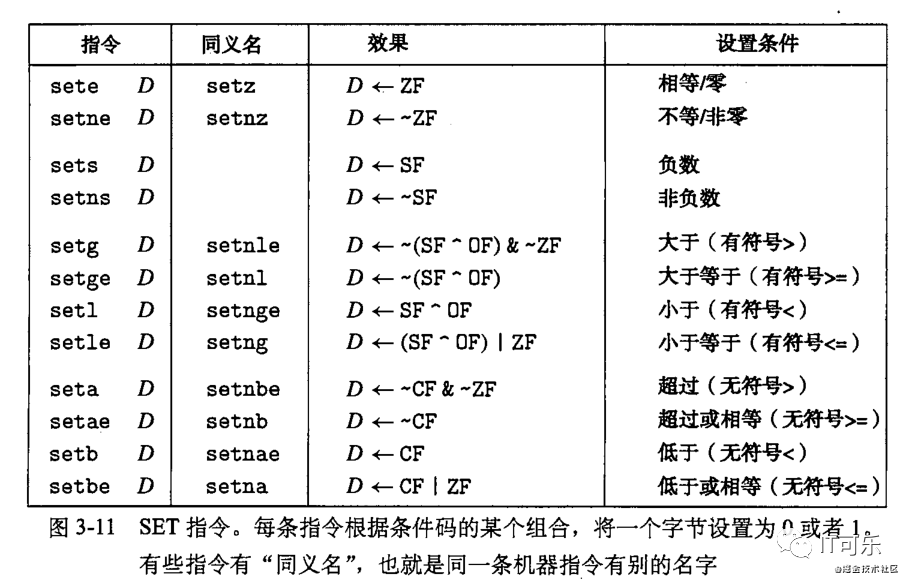 上图所说的同义名,比如说setg(表示“设置大于”)和 setnle(表示“不小于等于”)指的就是同一条机器指令,编译器和反编译器会随意决定使用哪个名字。
上图所说的同义名,比如说setg(表示“设置大于”)和 setnle(表示“不小于等于”)指的就是同一条机器指令,编译器和反编译器会随意决定使用哪个名字。
还有set指令中的目的操作数,只能是前面我们所讲的8个单字节的寄存器或者是存储一个字节的存储器位置。
下面我们分别对 set 指令出现的后缀做简单介绍:
①、e->ZF(相等):equals的意思,这里代表的组合是ZF,因为ZF在结果为0时设为1。因此ZF代表的意义是相等。
②、ne->~ZF(不相等):not equals 的意思,这里代表的组合是~ZF,也就是ZF做“非运算”,则很明显是不相等的意思。
③、s->SF(负数):这里代表的组合是SF,因为SF在计算结果为负数时设为1,此时可以认为b为0,即a<0。因此这里是负数的意思。
④、ns->~SF(非负数):与s相反,加上n则是not的意思,因此这里代表非负数。
⑤、l->SF^OF(有符号的小于):l代表的是less。这里的组合是SF^OF,即对SF和OF做“异或运算”。“异或运算”的意思则是代表,SF和OF不能相等。那么有两种情况,当OF为0时,则代表没有溢出,此时SF必须为1,SF为1则代表结果为负。即a-b<0,也就是a<b,也就是小于的意思。当OF为1时,则代表产生了溢出,而此时SF必须为0,也就是说结果最后为正数,那么此时则是负溢出,也可以得到a-b<0,即a<b。综合前面两种情况,SF^OF则代表小于的意思。
⑥、le->(SF^OF)|ZF(有符号的小于等于):le是less equals的意思。有了前面小于的基础,这里就很容易理解了。SF^OF代表小于,ZF代表等于,因此两者的“或运算”则代表小于等于。
⑦、g->~(SF^OF)&~ZF(有符号的大于):g是greater的意思。这里的组合是~(SF^OF)&~ZF,相对来说就比较复杂了。不过有了前面的铺垫,这个也非常好理解。SF^OF代表小于,则~(SF^OF)代表大于等于,而~ZF代表不等于,将~(SF^OF)与~ZF取“与运算”,则代表大于等于且不等于,也就是大于。
⑧、ge->~(SF^OF)(有符号的大于等于):ge是greater equals的意思。
⑨、b->CF(无符号的小于):b是below的意思。CF是无符号溢出标志,这里的意思是指如果a-b结果溢出了,则代表a是小于b的,即a<b。其实这个结论很显然,关键点就在于,无符号减法只有在减出负数的时候才可能溢出,也就是说只要结果溢出了,那么一定有a-b<0。因此这个结论就显而易见了。
⑩、be->CF|ZF(无符号的小于等于):这里是below equals的意思。因此这里会与ZF计算“或运算”,字面上也很容易理解,即CF(小于)|(或)ZF(等于),也就是小于等于。
⑪、a->~CF&~ZF(无符号的大于):a代表的是above。这个组合也是非常好理解的,CF代表小于,则~CF代表大于等于,~ZF代表不等于,因此~CF&~ZF则代表大于等于且不等于,即大于。
⑫、ae->~CF(无符号的大于等于):ae是above equals的意思。
比如对于setae %al指令来说,%al是%eax寄存器中的最后一个字节,这个指令的含义是,将~CF的值设置到%eax寄存器的最后一个字节。
4、跳转指令 jump
正常情况下,指令会按照他们出现的顺序一条一条地执行。而跳转指令(jump)会导致执行切换到程序中一个全新的位置,我们可以理解为方法或者函数的调用。在汇编代码中,这些跳转的目的地通常用一个标号(label)指明。比如如下代码:
movl $0,%eax
jmpl .L1
movl (%eax),%edx
.L1:
popl %edx
指令 jmpl .L1 会导致程序跳过 movl 指令,从 popl 开始执行。在产生目标代码文件时,汇编器会确定所有带标号指令的地址,并将跳转目标(目的指令的地址)编码为跳转指令的一部分。
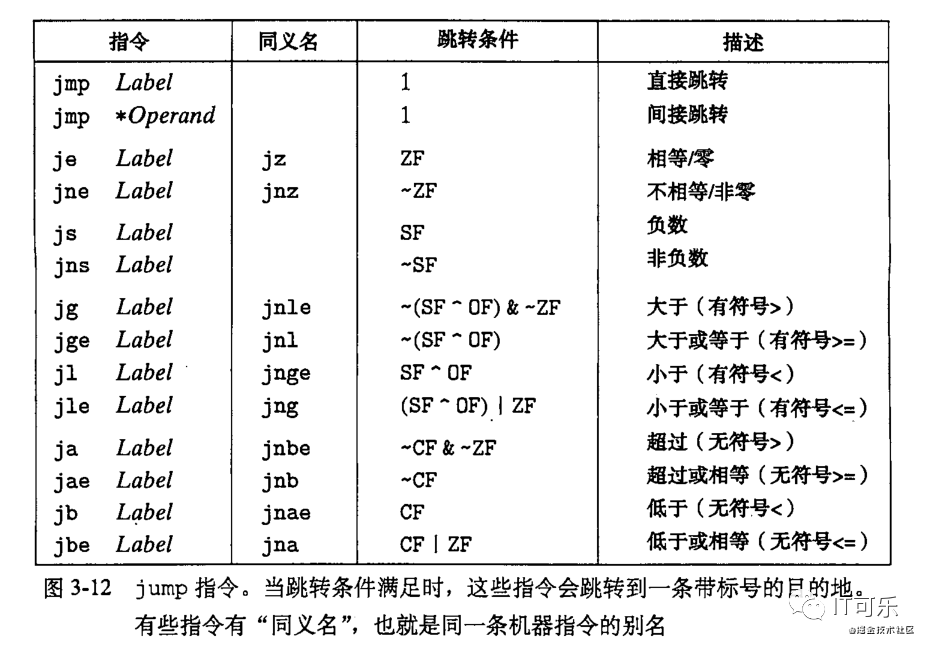
如下图所示,jump 指令有三种跳转方式:
①直接跳转:跳转目标是作为指令的一部分编码的,比如上面的直接给一个标号作为跳转目标
②间接跳转:跳转目标是从寄存器或者存储器位置中读出的,比如 jmp *%eax 表示用寄存器 %eax 中的值作为跳转目标;再比如 jmp *(%eax) 以 %eax 中的值作为读地址,从存储器中读取跳转目标。
③其他条件跳转:根据条件码的某个组合,或者跳转,或者继续执行代码序列中的下一条指令。
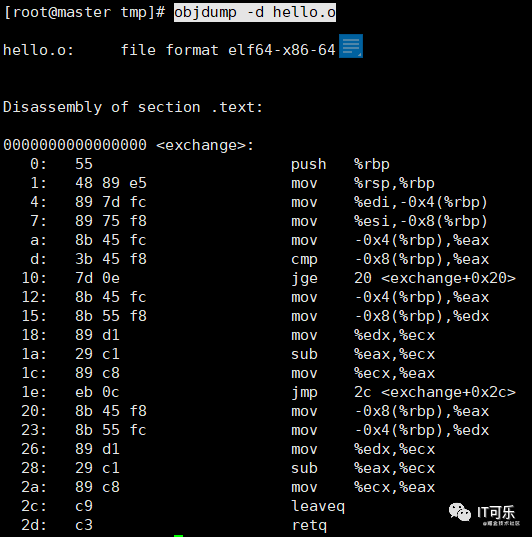
 比如对于如下代码:文件名为 hello.c
比如对于如下代码:文件名为 hello.c
int exchange(int x,int y)
{
if(x < y){
return y-x;
}else{
return x-y;
}
}
我们执行如下命令,将C程序hello.c变为汇编程序 hello.s
gcc -O0 -S hello.c
-O0是优化选项,还有O0 -->> O1 -->> O2 -->> O3,分别是从没有优化到优化级别最高。
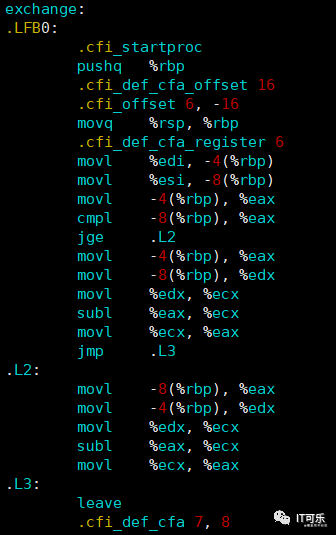
相信看了前面几篇博客的相关指令介绍,这个汇编代码不难理解。x,y分别存放于栈顶地址偏移量为-4和-8的位置,然后比较x-y的值,也就是指令 cmpl -8(%rbp),%eax,如果x大于或等于y,那么跳转到 .L2 的位置,然后计算 subl %eax,%ecx 的值,即x-y。
我们还可以通过如下命令生成目标文件 hello.c
gcc -O0 -c hello.c
然后通过如下命令查看反汇编代码
objdump -d hello.o
5、循环
C 语言提供了多种循环结构,比如 do-while、while和for。汇编中没有相应的指令存在,我们可以用条件测试和跳转指令组合起来实现循环的效果。而大多数汇编器会根据一个循环的do-while 循环形式来产生循环代码,即其他的循环一般也会先转换成 do-while 形式,然后在编译成机器代码。
比如如下 do-while 循环:
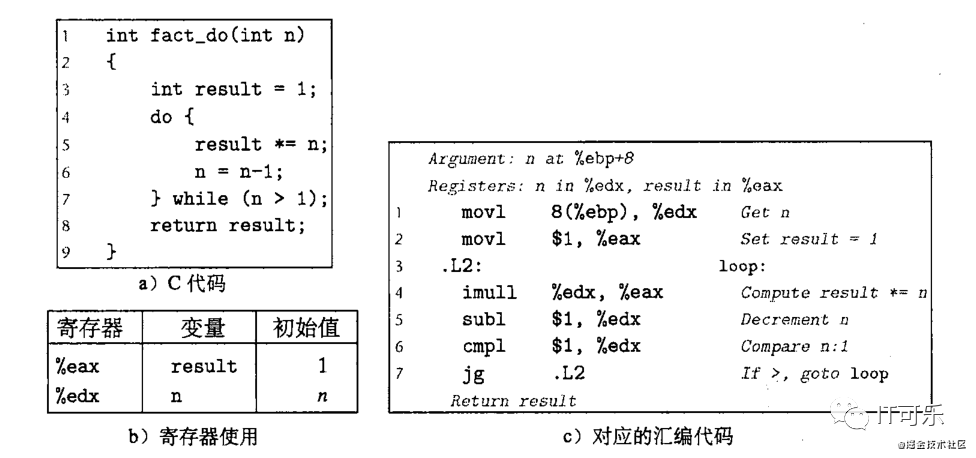 上面的汇编代码就不做过多的介绍了,应该很容易看明白。
上面的汇编代码就不做过多的介绍了,应该很容易看明白。
6、条件传送指令 cmov
条件传送指令。顾名思义,条件传送指令的意思就是在满足条件的时候进行传送的指令,也就是cmov指令。它与set指令十分相似,同样有12种,也就是加上12种条件码寄存器的组合即可,如下所示:
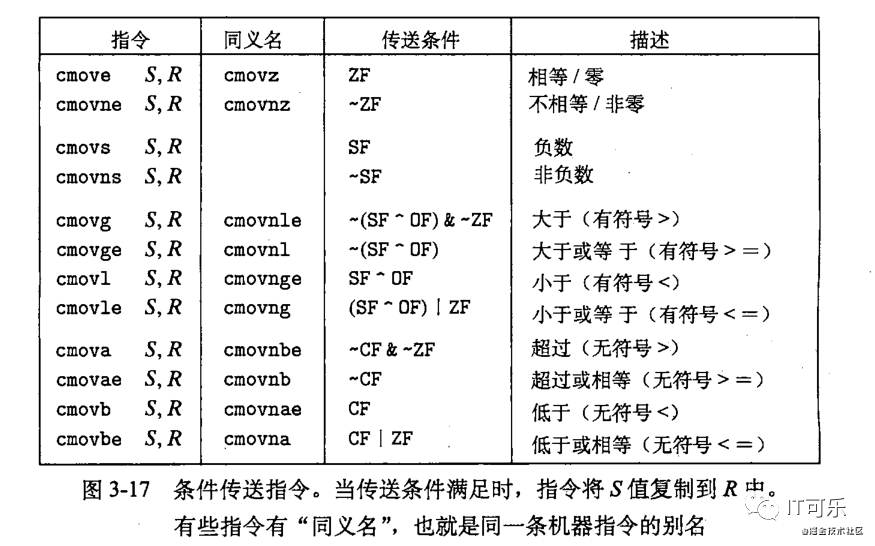 条件传送指令相当于一个if/else的赋值判断,一般情况下,条件传送指令的性能高于if/else的赋值判断。但是因为条件传送指令将对两个表达式都求值,因此如果两个表达式计算量很大时,那么条件传送指令的性能就可能不如if/else的分支判断了。不过总的来说,这种情况还是很少的,因此条件传送指令还是很有用的,只是并不是所有的处理器都支持条件传送指令,这依赖于处理器以及编译器的编译方式。
条件传送指令相当于一个if/else的赋值判断,一般情况下,条件传送指令的性能高于if/else的赋值判断。但是因为条件传送指令将对两个表达式都求值,因此如果两个表达式计算量很大时,那么条件传送指令的性能就可能不如if/else的分支判断了。不过总的来说,这种情况还是很少的,因此条件传送指令还是很有用的,只是并不是所有的处理器都支持条件传送指令,这依赖于处理器以及编译器的编译方式。
条件传送指令最大的缺点便是可能引起意料之外的错误,比如对于下面这一段代码。
int cread(int *xp){
return (xp ? *xp : 0);
}
咋一看,这一段代码是没问题的,不过如果使用条件传送指令去实现这段代码的话,将可能引起空指针引用的错误。因为条件传送指令会先对两个表达式进行计算,也就是说无论xp是否有值,都将计算*xp这个表达式,因此当xp为空指针0时,则会产生错误。由此可见,条件传送指令也不是哪都能用的,通常情况下,编译器会帮我们尽力处理这种错误。