
金融文本信息情感分析(负面及主体判定)

向AI转型的程序员都关注了这个号???
机器学习AI算法工程 公众号:datayx
给定一条金融文本和文本中出现的金融实体列表,
负面信息判定:判定该文本是否包含金融实体的负面信息。如果该文本不包含负面信息,或者包含负面信息但负面信息未涉及到金融实体,则负面信息判定结果为0。
负面主体判定:如果任务1中包含金融实体的负面信息,继续判断负面信息的主体对象是实体列表中的哪些实体。
分析:
给定一条金融信息X以及对应的实体集合S, 我们首先要判断该金融信息是否包含负面信息;如果包含负面信息,需要找出负面信息的主体E。
输入:金融信息
输出:是否包含负面信息(0/1);负面信息主体的集合E(其中E是S的子集)
简单来说就是需要判定给定金融文本是否包含金融实体的负面信息,并从给定实体列表中找出负面实体。
开源代码 数据集 获取:
关注微信公众号 datayx 然后回复 金融 即可获取。
AI项目体验地址 https://loveai.tech


通过统计发现在训练集合测试集中有大量的title和text是相似的,这需要作数据处理去除掉这些冗余信息,涉及到输入文本的选择问题。
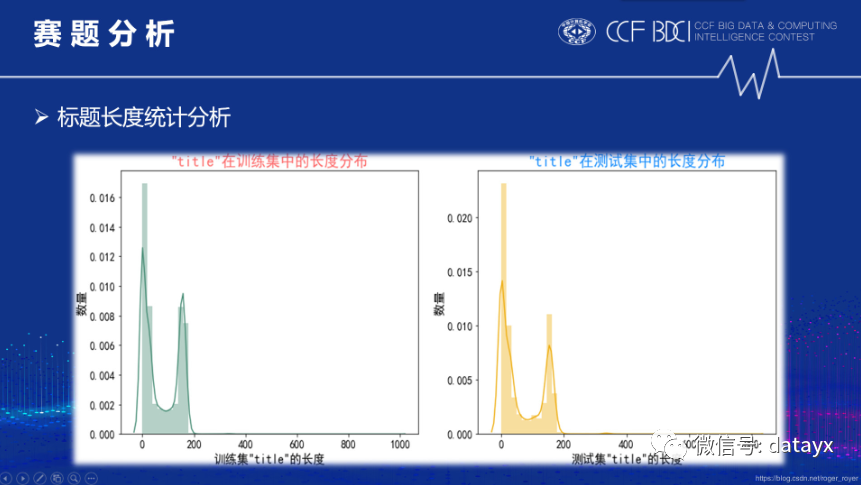
由上图可知,title和text长度在训练集和测试集中的分布几乎一致。
由于数据集中很多样本的title和text一样或者很相近,因此不是所有样本都需要考虑将title和text拼接作为文本,因此统计了title与text的编辑距离小于100的样本数量在训练集和测试集中的占比,如下图所示:

经大致分析发现,实体列表中很多实体与该列表中其它实体存在包含关系,而大多数子实体都不是key_entity;因此我们统计了实体列表中含有子实体的样本数量在训练集和测试集中的占比,可视化结果如下:

以下是我们对本题的难点描述和解题思路展示:
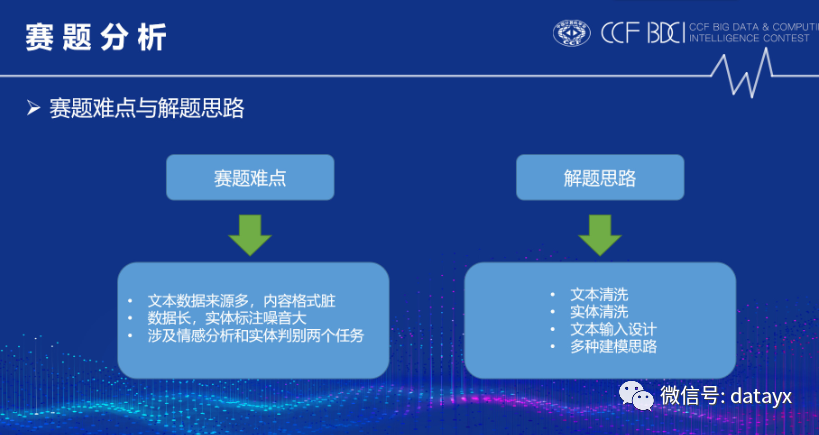
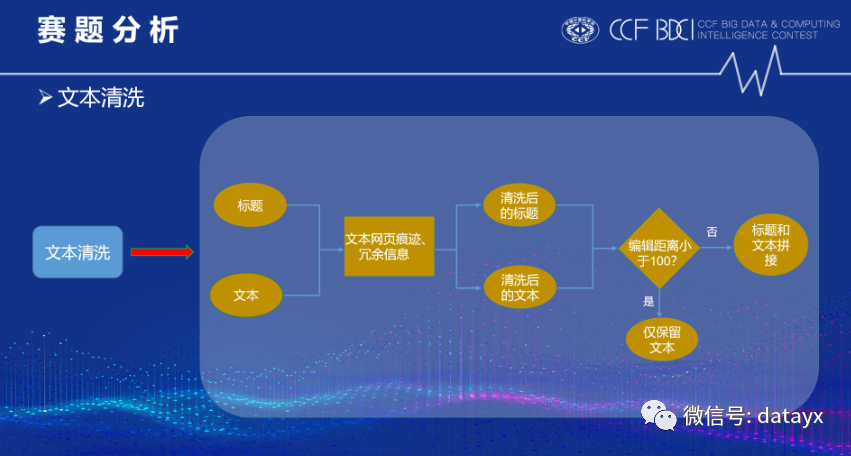
因为该题数据不规范,含有噪声,因此需要对文本进行清洗,清洗流程如下图所示:
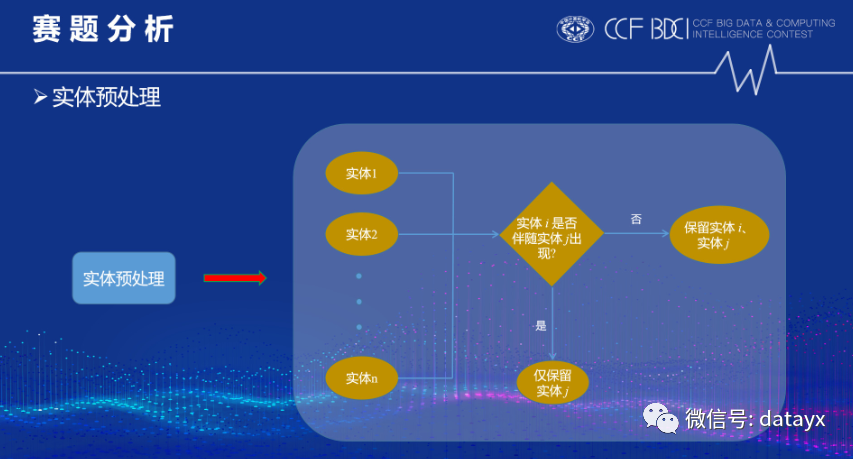
我们还对实体列表进行了相关处理,即去子词:
方案设计
首先展示我们团队的整体方案,如下图所示:
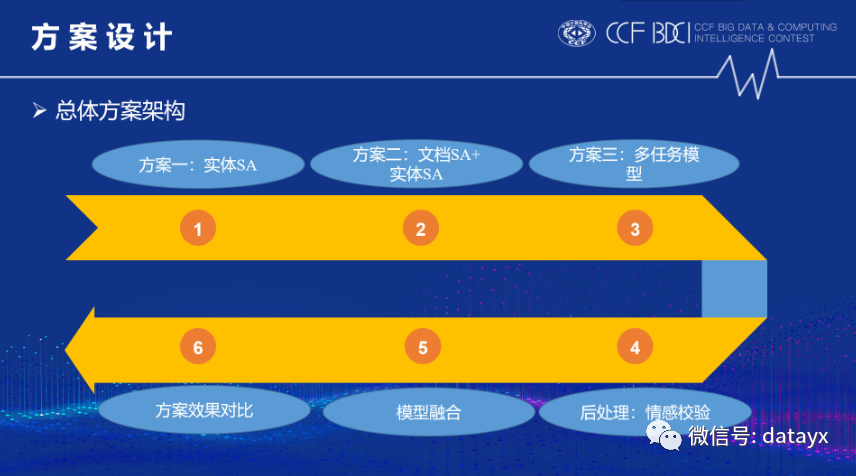
我们总共提出了三种不同方案来解决该问题,分别是:
实体SA(Sentiment Analysis)
文档SA+实体SA
多任务模型
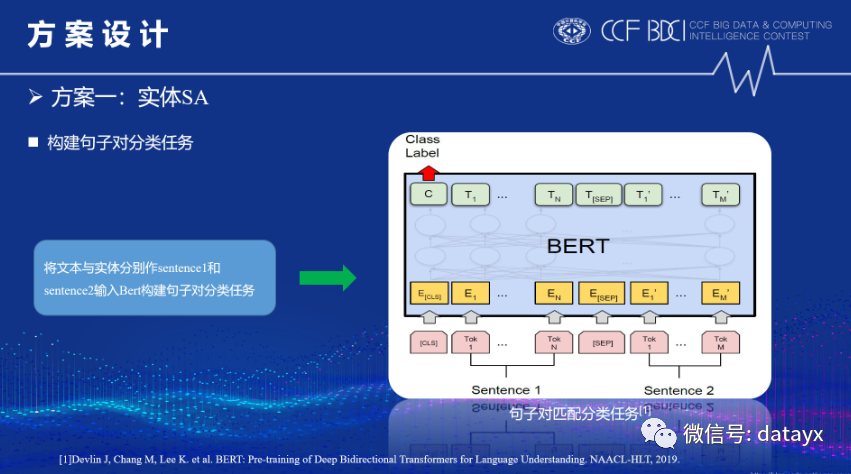
接下来分别对三种方案进行讲解,第一种是实体SA,即把两个子任务当成一个实体情感分析-分类任务:

样本构造样例:

以下是文本构造方法设计:

文本构造之后我们对该样本实体列表中的其它实体进行了替换,起到了标记其它实体位置的作用,替换方案如下:

最后是模型设计,我们通过构造句子对分类任务,微调bert模型:
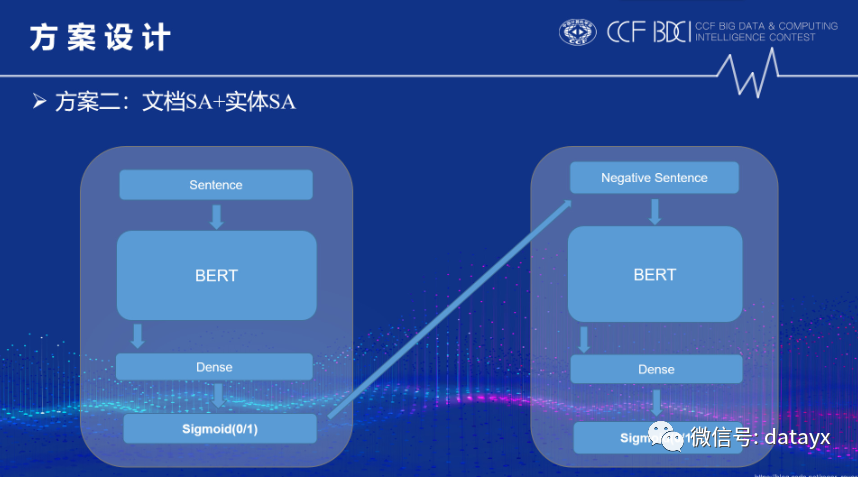
第二种是文档SA+实体SA,该方法就是先判断样本是否是负面的,如果样本是负面的再判断该样本的实体列表中每个实体的情感:
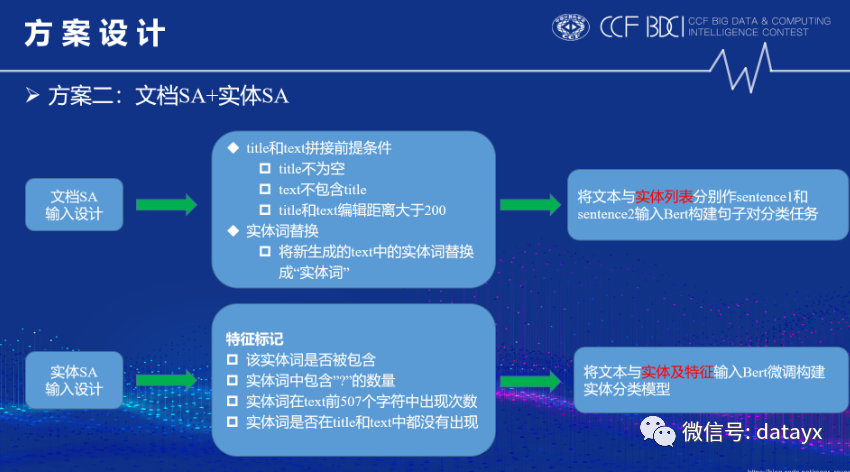
下图是文档SA、实体SA的输入设计和模型构建方法:
第三种是多任务模型,该方法将两个子任务结合起来共同学习;该方法启发于层次性多任务模型[2] 和多任务中的特征共享[3]:
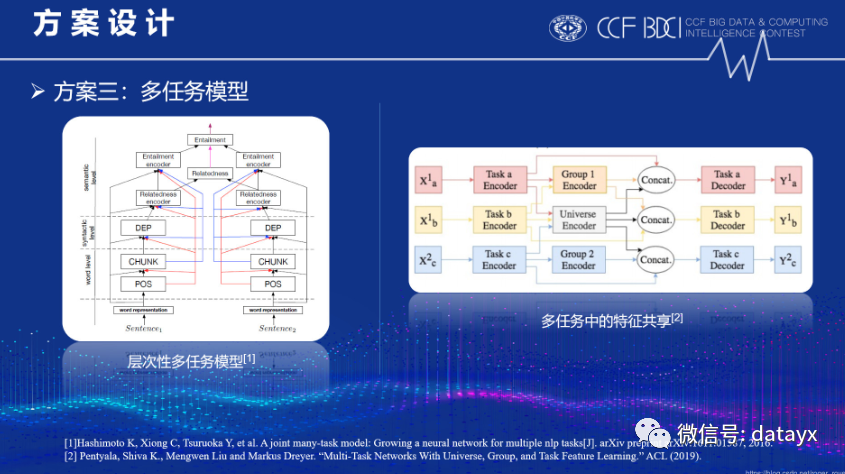
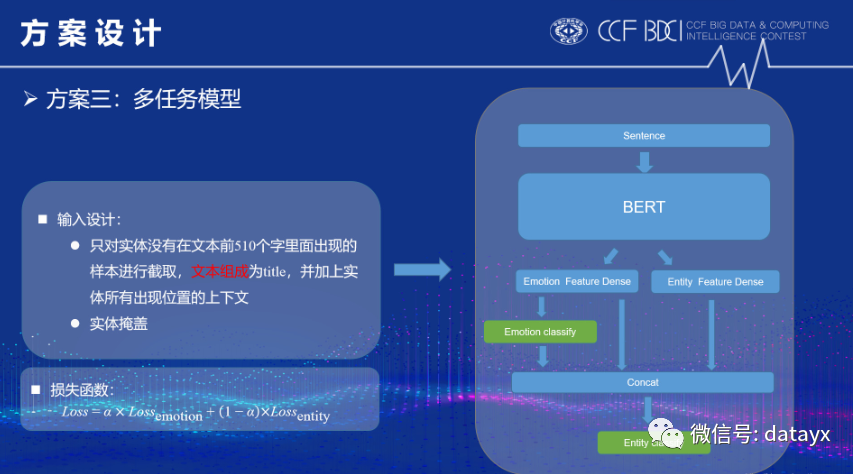
将多任务模型应用到本赛题中,将bert的最底层[CLS]向量取出来,在其后接两个单独的全连接层;两个全连接层分别对应文档情感二分类任务和实体二分类任务的特征表示,最后再在两个特征表示后面加上相应的输出层;微调过程中损失函数由上图的公式计算得出。
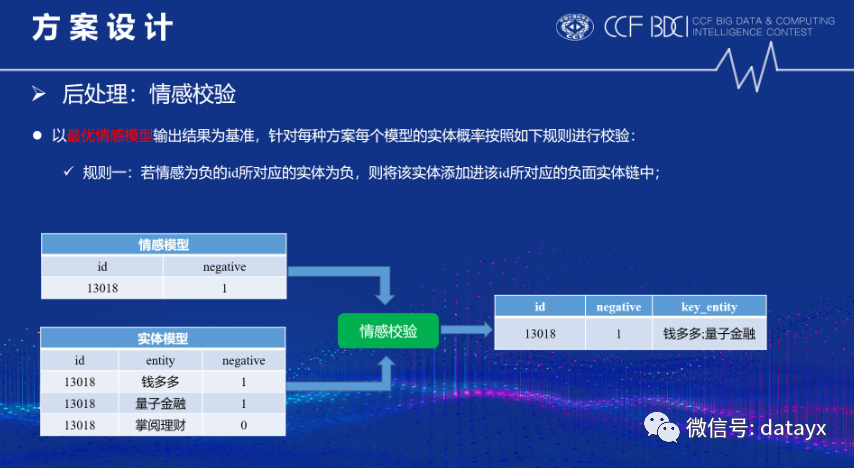
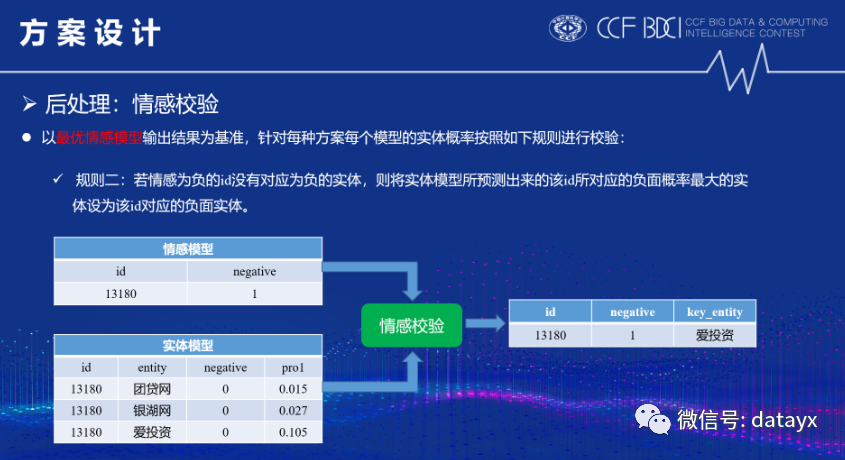
经过线上验证,我们的文档SA效果应该就比其它团队高至少将近一个千分点,因此为了方便后期模型融合和纠正方案一和方案三的negative准确性,本团队提出了情感校验的后处理方法,如下图所示:
最后是模型融合,我们分别尝试了stacking和voting,最终决定采用voting,因为voting效果更好,鲁棒性更强。
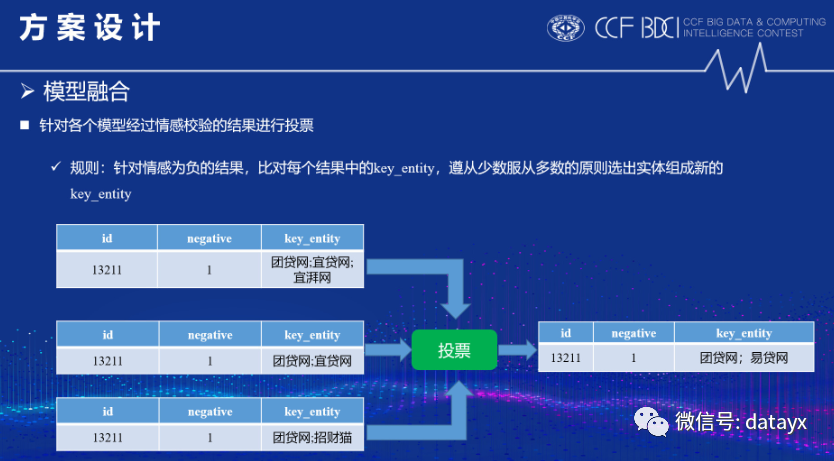
方案总结
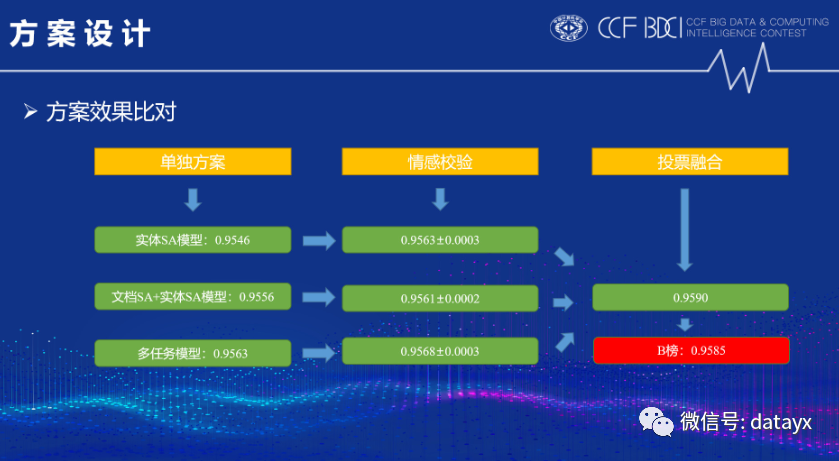
三种方案对比下来,多任务模型表现优于另外两种方案。
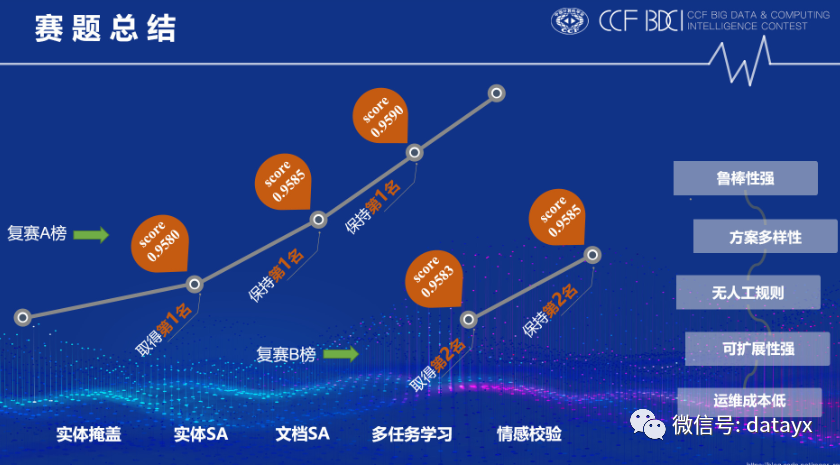
初赛受规则的影响,有点过拟合A榜;到了复赛阶段,摒弃了所有后处理人工规则,因此在B榜切换之后只降了5个万分点,足以说明模型的稳定性。在文本预处理方面我们团队进行了充分地探索,提出了实体掩盖和多种文本构造方法;在模型方面,我们提出了bert+特征三输入、多任务模型;最后还提出了情感校验,进一步提升了预测的准确性。
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码