
从整体视角了解情感分析、文本分类!
文本分类是自然语言处理(NLP)最基础核心的任务,或者换句话说,几乎所有NLP任务都是「分类」任务,或者涉及到「分类」概念。比如分词、词性标注、命名实体识别等序列标注任务其实就是Token粒度的分类;再比如文本生成其实也可以理解为Token粒度在整个词表上的分类任务。
本文侧重于从宏观角度(历史演变和基本流程)对文本情感分类任务进行介绍,目的是给读者提供一个整体视角,从高远处审视情感分析、文本分类、甚至NLP,期望能抛砖引玉,引发读者更多的思考。
本文同样适合于非算法岗位的工程师,以及没有技术背景但对NLP感兴趣的伙伴。
本文篇幅较长,主要分为四个部分。
01 背景介绍
情感分析是根据输入的文本、语音或视频,自动识别其中的观点倾向、态度、情绪、评价等,广泛应用于消费决策、舆情分析、个性化推荐等商业领域。包括篇章级、句子级和对象或属性级。可以分为以下三类:

工业界最常见的往往是这种情况。比如大众点评某家餐饮店下的评论:“服务非常赞,但味道很一般”,这句话其实表达了两个意思,或者说两个对象(属性)的评价,我们需要输出类似:<服务,正向>和<口味,负向>这样的结果(<属性-倾向>二元组),或者再细一点加入用户的观点信息(<属性-观点-倾向>三元组):<服务,赞,正向>和<口味,一般,负向>。这样的结果才更有实际意义。
从 NLP 处理的角度看,情感分析包括两种基础任务:文本分类和实体对象或属性抽取,而这也正好涵盖了 NLP 的两类基本任务:序列分类(Sequence Classification)和 Token 分类(Token Classification)。两者的区别是,前者输出一个标签,后者每个 Token 输出一个标签。
02 基本流程
一般来说,NLP 任务的基本流程主要包括以下五个:
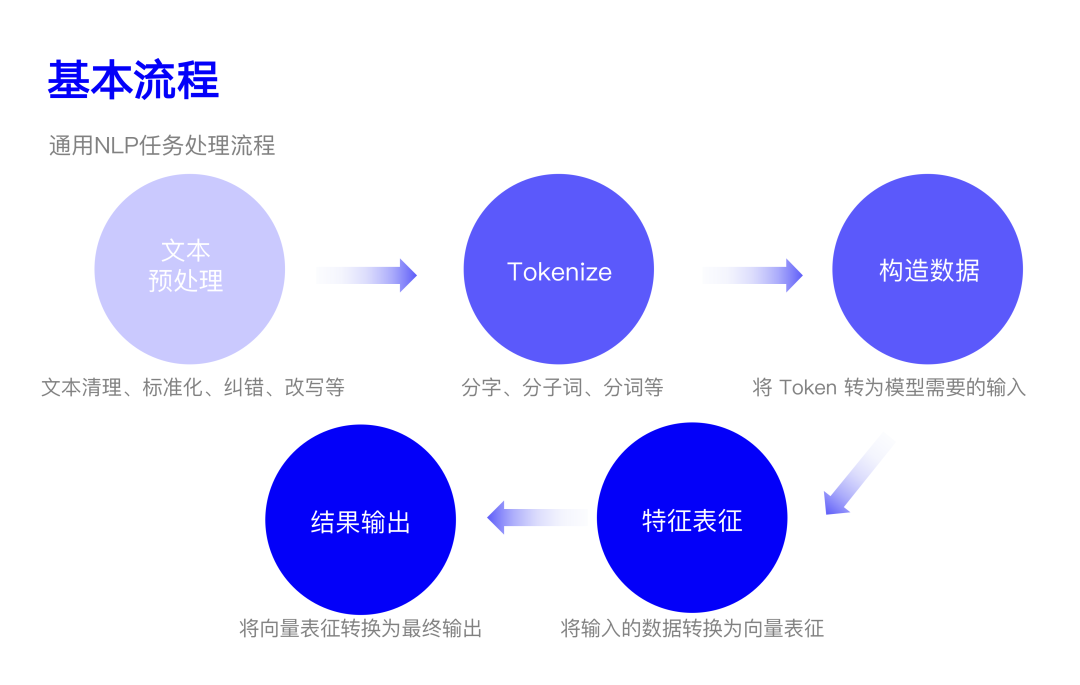
2.1 文本预处理
文本预处理主要是对输入文本「根据任务需要」进行的一系列处理。
文本清理:去除文本中无效的字符,比如网址、图片地址,无效的字符、空白、乱码等。
标准化:主要是将不同的「形式」统一化。比如英文大小写标准化,数字标准化,英文缩写标准化,日期格式标准化,时间格式标准化,计量单位标准化,标点符号标准化等。
纠错:识别文本中的错误,包括拼写错误、词法错误、句法错误、语义错误等。
改写:包括转换和扩展。转换是将输入的文本或 Query 转换为同等语义的另一种形式,比如拼音(或简拼)转为对应的中文。扩展主要是讲和输入文本相关的内容一并作为输入。常用在搜索领域。
需要注意的是,这个处理过程并不一定是按照上面的顺序从头到尾执行的,可以根据需要灵活调整,比如先纠错再标准化或将标准化放到改写里面。咱们不能被这些眼花缭乱的操作迷惑,始终谨记,文本预处理的目的是将输入的文本变为已有系统「喜欢且接受」的形式。举个例子,比如系统在训练时都使用「单车」作为自行车的称呼,那预处理时就应该把自行车、Bike、Bicycle 等都转为单车。或者甚至系统用了某个错别字,那输入也要变成对应的错别字。
2.2 Tokenizing(分词)
主要目的是将输入的文本 Token 化,它涉及到后续将文本转为向量。一般主要从三个粒度进行切分:
字级别:英文就是字母级别,操作起来比较简单。
词级别:英文不需要,中文可能会需要。关于中文分词,之前写过一点思考,简单来说,分词主要是「分割语义」,降低不确定性,要不要分词一般要看任务和模型。
子词:包括BPE(Byte Pair Encoding),WordPieces,ULM(Unigram Language Model)等。在英文中很常见,当然中文也可以做,是介于字级别和词级别中间的一种粒度。主要目的是将一些「统一高频」的形式单独拎出来。比如英文中 de 开头的前缀,或者最高级 est 等等。子词一般是在大规模语料上通过统计「频率」自动学习到的。
我们需要知道的是,字和词并非哪个一定比另一个好,都要需要根据具体情况具体分析的。它们的特点如下:
| 粒度 | 字 | 词 |
|---|---|---|
| 词表大小 | 固定 | 无法穷尽 |
| 未识别词(OOV) | 没有 | 典型问题,长尾、稀疏性 |
| 参数/计算量 | 多 | Token 变少,参数少,计算快 |
| 语义/建模复杂度 | 有不确定性 | 携带语义,能够降低不确定性 |
注:OOV=Out Of Vocabulary
2.3 构造数据
文本经过上一步后会变成一个个 Token,接下来就是根据后续需要将 Token 转为一定形式的输入,可能就是 Token 序列本身,也可能是将 Token 转为数字,或者再加入新的信息(如特殊信息、Token 类型、位置等)。我们主要考虑后两种情况。
Token 转数字:就是将每个「文本」的 Token 转为一个整数,一般就是它在词表中的位置。根据后续模型的不同,可能会有一些特殊的 Token 加入,主要用于「分割输入」,其实就是个「标记」。不过有两个常用的特殊 Token 需要稍加说明:<UNK> 和 <PAD>,前者表示「未识别 Token」,UNK=Unknown,后者表示「填充 Token」。因为我们在实际使用时往往会批量输入文本,而文本长度一般是不相等的,这就需要将它们都变成统一的长度,也就是把短的用 <PAD> 填充上。<PAD> 一般都放在词表第一个位置,index 为 0,这样有个好处就是我们在计算时,0 的部分可以方便地处理掉(它们是「填充」上去的,本来就算不得数)。
加入新的信息:又可以进一步分为「在文本序列上加入新的信息」和「加入和文本序列平行的信息」。
序列上新增信息:输入的文本序列有时候不一定『只』是一句话,还可能会加入其他信息,比如:「公司旁边的螺蛳粉真的太好吃了。<某种特殊分隔符>螺蛳粉<可能又一个分隔符>好吃」。所以,准确来说,应该叫「输入序列」。 新增平行信息:有时候除了输入的文本序列,还需要其他信息,比如位置、Token 类型。这时候就会有和 Token 序列 Token 数一样的其他序列加入,比如绝对位置信息,如果输入的句子是「今天吃了螺蛳粉很开心」,对应的位置编码是「1 2 3 4 5 6 7 8 9 10」。
需要再次强调的是,这一步和后续使用的模型直接相关,要根据具体情况进行相应处理。
2.4 文本特征
根据上面构造的数据,文本特征(也可以看作对文本的表征)从整体来看可以分为两个方面:Token 直接作为特征和 Token(或其他信息)编码成数字,然后转成向量作为特征。这一小节咱们主要介绍一下从 Token 到特征形态发生了哪些变化,至于怎么去做这种转换,为什么,下一节《模型发展》中会做进一步分析。
a. OneHot
首先,要先明确下输入的文本最终要变成什么样子,也就是特征的外形长啥样。注意,之前得到的整数并不能直接放到模型里去计算,因为数字的大小并没有语义信息。
那么,最简单的表示方式就是某个 Token 是否出现在给定的输入中。我们假设实现已经有一个做好的很大的词表,里面有 10w 个 Token。当我们给定 Token 序列时,词表中的每个 Token 是否出现在给定的序列中就可以构造出一个 01 向量:
[0, 0, 1, 0, ..., 0, 1] # 10w 个
其中 1 表示那个位置的 Token 在出现在了给定的序列中,0 则表示未出现。可以想象,对于几乎所有的输入,对应的 01 向量绝大多数的位置都是 0。假设有 m 个句子,那么会得到一个矩阵:
# m * 10w
[[0, 0, 1, 0, ..., 0, 1],
[0, 1, 0, 0, ..., 0, 0],
[0, 0, 1, 1, ..., 0, 1],
[0, 1, 1, 0, ..., 0, 0],
...
[1, 0, 0, 0, ..., 0, 1]]
其中的每一列就表示该位置 Token 的向量表示,换句话说,在表示句子的同时,Token 也被成功地表示成了一个向量。
上面的这种编码方式就叫 OneHot 编码,也就是把 Token 编成一个只有一个 1 其余全是 0 的向量,然后通过在语料上计算(训练)得到最后的表示。
b. TF-IDF
聪明的您一定会想到,既然可以用「出现」或「不出现」来表示,那为啥不用频率呢?没错,我们可以将上面的 1 都换成该词在每个句子中出现的频率,归一化后就是概率。由于自然语言的「齐夫定律」,高频词会很自然地占据了主导地位,这对向量表示大有影响,想象一下,那些概率较高的词几乎在所有句子中出现,它们的值也会更大,从而导致最终的向量表示向这些词倾斜。
齐夫定律:在自然语言语料库中,一个单词出现的频率与它在频率表里的排名成反比。即第 n 个常见的频率是最常见频率的 1/n。举个例子来说,中文的「的」是最常见的词,排在第 1 位,比如第 10 位是「我」,那「我」的频率就是「的」频率的 1/10。
于是,很自然地就会想到使用某种方式去平和这种现象,让真正的高频词凸显出来,而降一些类似的、是这种常见词的影响下降。咱们很自然就会想到,能不能把这些常见词从词表给剔除掉。哎,是的。这种类似的常见词有个专业术语叫「停用词」,一般呢,停用词主要是虚词居多,包括助词、连词、介词、语气词等,但也可能会包括一些「没用」的实词,需要根据实际情况处理。
除了停用词,还有另一种更巧妙的手段处理这个问题——TF-IDF,TF=Term Frequency,IDF=Inverse Document Frequency。TF 就是刚刚提到的词频,这不是有些常用词吗,这时候 IDF 来了,它表示「有多少个文档包含那个词」,具体等于文档总数/包含该词的文档数。比如「的」在一句话(或一段文档)中概率很高,但几乎所有句子(或文档)都有「的」,IDF 接近 1;相反如果一个词在句子中概率高,但包含该词的文档比较少,IDF 就比较大,最后结果也大。而这是满足我们预期的——词在单个文档或句子中是高概率的,但在所有文档或句子中是低概率的,这不正说明这个词对所在文档或句子比较重要吗。实际运算时,一般会取对数,并且防止 0 除:
这时候的向量虽然看着不是 OneHot,但其实本质还是,只是在原来是 1 的位置,变成了一个小数。
c. Embedding
刚刚的得到的矩阵最大的问题是维度太大,数据稀疏(就是绝大部分位置是 0),而且词和词之间是孤立的。最后这个问题不用多解释,这样构建的特征肯定「不全面」。但是维度太大和数据稀疏又有什么影响呢?首先说前者,在《文献资料:文本特征》第一篇文章提到了在超高维度下的反直觉现象——数据不会变的更均匀,反而会聚集在高维空间的角落,这会让模型训练特别困难。再说后者,直观来看,数据稀疏最大的问题是使得向量之间难以交互,比如「出差住酒店」和「出差住旅店」,酒店和旅店在这里意思差不多,但模型却无法学习到。
既然如此,先辈们自然而然就想能不能用一个连续稠密、且维度固定的向量来表示。然后,大名鼎鼎的「词向量」就登场了——它将一个词表示为一个固定维度大小的稠密向量。具体来说,就是首先随机初始化固定维度大小的稠密向量,然后用某种策略通过词的上下文自动学习到表征向量。也就是说,当模型训练结束了,词向量也同时到手了。具体的过程可参考《文献资料:文本特征》第二篇文章。
「词向量」是一个划时代的成果,为啥这么说呢?因为它真正把自然语言词汇表征成一个可计算、可训练的表示,带来的直接效果就是自然语言一步跨入了深度学习时代——Embedding 后可以接各种各样的模型架构,完成复杂的计算。
2.5 结果输出
当用户的输入是一句话(或一段文档)时,往往需要拿到整体的向量表示。在 Embedding 之前虽然也可以通过频率统计得到,但难以进行后续的计算。Embedding 出现之后,方法就很多了,其中最简单的当然是将每个词的向量求和然后平均,复杂的话就是 Embedding 后接各种模型了。
那么在得到整个句子(或文档)的向量表示后该如何得到最终的分类呢?很简单,通过一个矩阵乘法,将向量转为一个类别维度大小的向量。我们以二分类为例,就是将一个固定维度的句子或文档向量变为一个二维向量,然后将该二维向量通过一个非线性函数映射成概率分布。
举个例子,假设最终的句子向量是一个 8 维的向量,w 是权重参数,计算过程如下:
import numpy as np
rng = np.random.default_rng(seed=42)
embed = rng.normal(size=(1, 8)).round(2)
# array([[ 0.3 , -1.04, 0.75, 0.94, -1.95, -1.3 , 0.13, -0.32]]) 维度=1*8
w = rng.normal(size=(8, 2)).round(2)
""" 维度=8*2
array([[-0.02, -0.85],
[ 0.88, 0.78],
[ 0.07, 1.13],
[ 0.47, -0.86],
[ 0.37, -0.96],
[ 0.88, -0.05],
[-0.18, -0.68],
[ 1.22, -0.15]])
"""
z = embed @ b # 矩阵乘法
# array([[-2.7062, 0.8695]]) 维度=1*2
def softmax(x):
return np.exp(x) / np.sum(tf.exp(x), axis=1)
softmax(z)
# array([[0.0272334, 0.9727666]])
这个最后的概率分布是啥意思呢?它分别表示结果为 0 和 1 的概率,两者的和为 1.0。
您可能会有疑问或好奇:参数都是随机的,最后输出的分类不对怎么办?这个其实就是模型的训练过程了。简单来说,最后输出的概率分布会和实际的标签做一个比对,然后这个差的部分会通过「反向传播算法」不断沿着模型网络往回传,从而可以更新随机初始化的参数,直到最终的输出和标签相同或非常接近为止。此时,我们再用训练好的网络参数计算,就会得到正确的标签。
03 模型简史
这部分我们主要简单回顾一下 NLP 处理情感分类任务模型发展的历史,探讨使用了什么方法,为什么使用该方法,有什么问题等。虽然您看到的是情感分类,其实也适用于其他类似的任务。
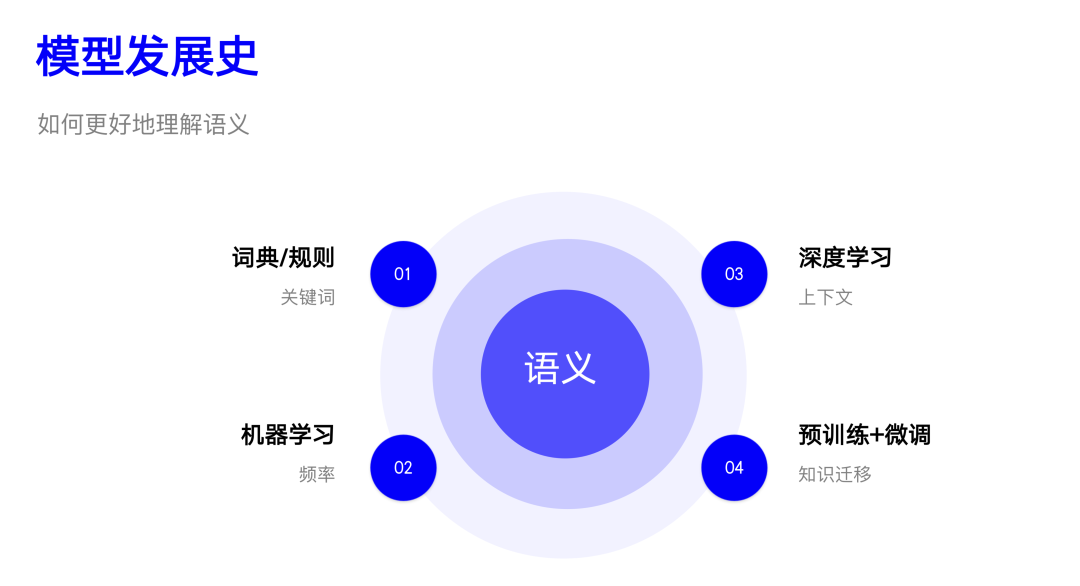
3.1 词典/规则
在 NLP 发展的初级阶段,词典和规则的方法是主流。算法步骤也非常简单:
事先收集好分别代表正向和负向的词表。比如正向的「开心、努力、积极」,负向的「难过、垃圾、郁闷」 对给定的文本分词 分别判断包含正向和负向词的数量 包含哪类词多,结果就是哪一类
可以看出这个非常简单粗暴,模型就是这两个词表,整个算法的核心就是「基于匹配」,实际匹配时,考虑到性能一般会使用 Trie 或自动机进行匹配。这种方法的主要特点包括:
简单:意味着成本低廉,非常容易实施。
歧义:因为一个个词是独立的,没有考虑上下文,导致在否定、多重否定、反问等情况下会失败,比如「不开心、不得不努力、他很难过?不!」
无法泛化:词表是固定的,没有出现在词表中的词,或稍微有些变化(比如单个字变了)就会导致识别失败。
虽然有不少问题,但词典/规则方法直到现在依然是常用的方法之一,这背后根本的原因就在于我们在自然语言理解时往往会特别关注到其中的「关键词」,而语序、助词等往往没啥别特影响^_^
3.2 机器学习
随着统计在 NLP 领域的使用,「基于频率」的方法开始风靡,最简单常用的模型就是 Ngram,以及基于 Ngram 构建特征并将之运用在机器学习模型上。这一阶段的主要特点是对数据进行「有监督」地训练,效果自然比上一种方法要好上很多。
Ngram 其实很简单。比如给定一句话「人世间的成见就像一座大山」,如果以字为粒度,Bigram 结果是「人世 世间 间的……」,Trigram 自然就是「人世间 世间的 间的成……」,4-Gram,5-Gram 以此类推。不过实际一般使用 Bigram 和 Trigram 就够了。
Ngram 本质是对句子进行语义分割(回想前面提到的「分词的意义」),也可以看成是一种「分词」。所以之前构建文本特征的 Token 也都可以换成 Ngram。现在从概率角度考虑情感分类问题,其实就是解决下面这个式子:
这里给定的 Token 可以是字、词或任意的 Ngram,甚至是彼此的结合。由于分母在不同类型下是一样的,所以可以不考虑,主要考虑分子部分。又由于类别的概率一般是先验的,因此最终就成了解决给定情感倾向得到给定 Token 序列的概率。上面的式子也叫贝叶斯公式,如果不考虑给定 Token 之间的相关性,就得到了朴素贝叶斯(Naive Bayes):
此时,我们只需要在正向和负向语料上分别计算 Token 的概率即可,这个过程也叫训练,得到的模型其实是两个 Token 概率表。有了这个模型,再有新的句子过来时,Token 化后,利用(2)式分别计算正向和负向的概率,哪个高,这个句子就是哪种类别。深度学习之前,Google 的垃圾邮件分类器就是用该算法实现的。
可以发现,这种方法其实是考虑了两种不同类型下,可能的 Token 序列概率,相比上一种方法容错率得到了提高,泛化能力增加。需要注意的是,歧义本质是使用 Ngram 解决的,这也同样适用于上一种方法。由于类似于直接查表,所以这种方法本质上是 OneHot 特征,只不过是直接用了 Token 本身(和它的概率)作为特征。另外,无论是哪种「文本特征」,都是可以直接运用在机器学习模型上进行计算训练的。
这里的核心其实是「基于频率」建模,实际会使用 Ngram,通过 OneHot、TF-IDF 等来构建特征。这种方法的主要问题是:维度灾难、数据稀疏、词孤立等,在『文本特征』一节已做相应介绍,这里不再赘述。
3.3 深度学习
深度学习时代最大的不同是使用了稠密的 Embedding,以及后面可接各式各样的神经网络,实际上是一种「基于上下文」的建模方式。我们以 NLP 领域经典的 TextCNN 架构来进行说明。
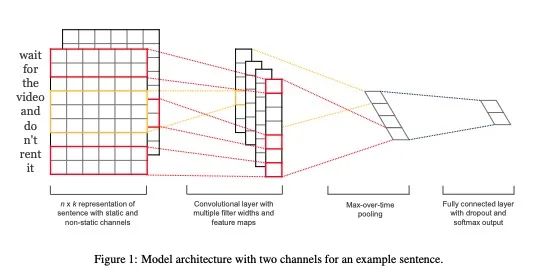
假设每个词是 6 维的(如图所示),每个词旁边的格子里都对应着该词的 Embedding,整个那一片可以叫输入句子的 Embedding 矩阵。我们现在假设有一个 3×6 的矩阵,里面的值是要学习的参数,一开始是随机初始化的。这个 3×6 的矩阵叫 Kernel,它会沿着句子 Embedding 矩阵从上往下移动,图例中的步幅是 1,每移动一步,Kernel 和 3 个词的 Embedding 点乘后求和后得到一个值,最后就会得到一个一维向量(卷积层 Convolutional layer),然后取最大值或平均值(池化层 Pooling),就会得到一个值。如果我们每次使用一个值不一样的 Kernel,就会得到一组不同的值,这个就构成了输入句子的表征,通过类似前面『结果输出』中的计算,就会得到最终的概率分布。
这里有几点需要说明一下:
第一,我们可以使用多个不同大小的 Kernel,刚刚用了 3,还可以用 2、4 或 5,最后得到的向量会拼接在一起,共同作为句子的标准。
第二,Embedding 矩阵也是可以作为参数在训练时初始化的,这样模型训练完了,Embedding 顺便也就有了(此时因为最终结果都已经有了,往往该矩阵也没啥意义,不需要单独拿出来考虑),或者也可以直接使用已经训练好的 Embedding 矩阵。
第三,除了 TextCNN 还有其他很多模型也可以做类似的事,大同小异。
Embedding 有效地解决了上一种方法的问题,但它本身也是有一些问题的,比如没考虑外部知识,这就进入了我们下一个时代——预训练模型。
3.4 预训练+微调
预训练模型「基于大规模语料训练」,其本质是一种迁移学习——将大规模语料中的知识学习到模型中,然后用在各个实际的任务中,是对上一种方法的改进。我们以百度的 ERNIE 为例说明。
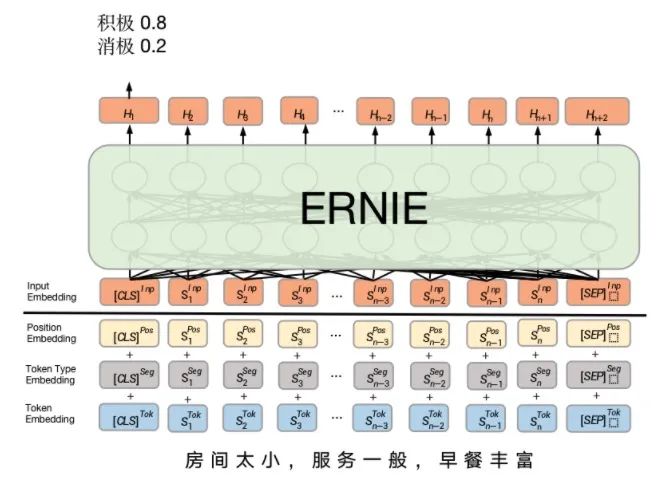
首先是它的输入比上一种方法多了新的信息,但最终每个 Token 依然会得到一个 Embedding,然后经过一个复杂的预训练模型 ERNIE 就会得到最终的输出向量(类似上个方法的中间步骤),进而就可以得到标签的概率分布。预训练模型已经在很多 NLP 任务上达到了最好的效果。
当然,要说预训练模型有什么不好,那就是太大太贵了,大是指模型大以及参数规模大(起码上亿),贵则是训练过程需要消耗的资源很多。不过大多数情况下,我们并不需要自己训练一个,只要使用开源的即可,因为预训练的语料足够大,几乎涵盖了所有领域,大部分时候会包含您任务所需要的信息。
以上涉及的代码可以参考:http://nbviewer.org/github/hscspring/All4NLP/blob/master/Senta/senta.ipynb
04 探讨展望
4.1 实际应用
上面介绍了那么多的方法和模型,这里主要探讨一下在实际应用过程中的一些取舍和选择。
规则 VS 模型:纯规则、纯模型和两者结合的方法都有。规则可控,但维护起来不容易,尤其当规模变大时,规则重复、规则冲突等问题就会冒出来;模型维护简单,有 bad case 重新训练一下就行,但可能需要增加语料,另外过程也不能干预。实际中,简单任务可以使用纯模型,复杂可控任务可以使用模型+规则组合,模型负责通用大多数,规则覆盖长尾个案。
深度 VS 传统:这个选择其实比较简单,当业务需要可解释时,可以选择传统的机器学习模型,没有这个限制时,应优先考虑深度学习。
简单 VS 复杂:当任务简单,数据量不大时,可以用简单模型(如 TextCNN),此时用复杂模型未必效果更好;但是当任务复杂,数据量比较多时,复杂模型基本上是碾压简单模型的。
总而言之,使用什么方案要综合考虑具体的任务、数据、业务需要、产品规划、资源等多种因素后确定。
4.2 情感的未来
主要简单畅想一下未来,首先可以肯定的是未来一定是围绕着更深刻的语义理解发展的。从目前的发展看,主要有以下几个方向。
1、多模态:多种不同形态的输入结合。包括:文本、图像、声音等,或者文本、视频。这个也是目前比较前沿的研究方向,其实也是很容易理解的。因为我们人类往往都会察言观色,听话听音,其实就是从多个渠道接收到「信息」。换成机器,自然也可以做类似的事情,预期来看,效果必然是有提升的。举个例子,比如就是简单的「哈哈哈哈」几个字,如果单纯从文本看就是「大笑」,但如果配上图像和声音,那可能就变成「狂暴」、「淫邪」、「假笑」等可能了。
2、深度语义:综合考虑率多种影响因素。包括:环境、上下文、背景知识。这点和第一点类似,也是尽量将场景「真实化」。
环境指的是对话双方当前所处的环境,比如现在是冬天,但用户说「房间怎么这么热」,其实可能是因为房间空调或暖气开太高。如果不考虑环境,可能就会难以理解(这对人来说也是一样的)。
上下文指的是对话中的历史信息,比如开始对话时用户说「今天有点感冒」,后面如果再说「感觉有点冷」,那可能是生病导致的。如果没有这样的上下文记忆,对话可能看起来就有点傻,对情感的理解和判断也会不准确。其实上下文在多轮对话中已有部分应用,但还远远不够,主要是难以将和用户所有的历史对话都结构化地「连接」在一起。目前常用的也是根据用户的「行为」数据对其「画像」。
背景知识是指关于世界认知的知识。比如用户说「年轻人,耗子尾汁」,如果机器人没有关于马保国相关的背景知识就很难理解这句话是啥意思。这块目前在实践的是知识图谱,其实就是在做出判断时,多考虑一部分背景知识的信息。
3、多方法:综合使用多种方法。包括:知识图谱、强化学习和深度学习。这是从方法论的角度进行思考,知识图谱主要是世界万物及其基本关系进行建模;强化学习则是对事物运行的规则建模;而深度学习主要考虑实例的表征。多种方法组合成一个立体完整的系统,这里有篇不成熟的胡思乱想对此进行了比较详细的阐述。
文献资料
这部分作为扩展补充,对相应领域有兴趣的伙伴可以顺着链接了解一下:
业界应用
情感分析技术在美团的探索与应用:https://mp.weixin.qq.com/s/gXyH4JrhZI2HHd5CsNSvTQ
情感计算在UGC应用进展:https://mp.weixin.qq.com/s/FYjOlksOxb255CvNLqFjAg
预处理
NLP 中的预处理:使用 Python 进行文本归一化:https://cloud.tencent.com/developer/article/1625962)
当你搜索时,发生了什么?(中) | 人人都是产品经理:http://www.woshipm.com/pd/4680562.html
全面理解搜索 Query:当你在搜索引擎中敲下回车后,发生了什么?:https://zhuanlan.zhihu.com/p/112719984
Tokenize
深入理解NLP Subword算法:BPE、WordPiece、ULM:https://zhuanlan.zhihu.com/p/86965595
Byte Pair Encoding — The Dark Horse of Modern NLP:https://towardsdatascience.com/byte-pair-encoding-the-dark-horse-of-modern-nlp-eb36c7df4f10
文本特征
The Curse of Dimensionality in Classification:https://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/
word2vec 前世今生:https://www.cnblogs.com/iloveai/p/word2vec.html
情感未来
多模态情感分析简述:https://www.jiqizhixin.com/articles/2019-12-16-7
千言数据集:情感分析:https://aistudio.baidu.com/aistudio/competition/detail/50/0/task-definition

太子长琴
算法工程师
个人博客:https://yam.gift/