
从零实现爬虫和情感分类模型(二)

大家好,我是Giant,这是我的第5篇文章。
上一篇文章中我们完成了python环境搭建和百万级评论爬虫,本文将利用爬取的数据训练评论分类模型。
开源代码:
https://github.com/yechens/RestaurantCrawler/blob/main/demo_01.ipynb
01 数据处理三剑客
pandas、numpy、matplotlib功能强大使用方便,被誉为python数据处理三剑客。
之前爬取的数据保留在mongodb中,可以用mogoexport或数据库可视化软件将其导出到csv文件。
数据清洗
简单起见,这里分别导出评分5星和1星的评论各6800条。后续处理中,每类情感取6000条用于模型训练和校验,剩余800条作为测试。
将导出的数据分别命名为10_star.csv、50_star.csv,借助pandas库导入。

接下来遍历评论列的每一行,过滤其中的非中文字符和长度小于10的无效评论。
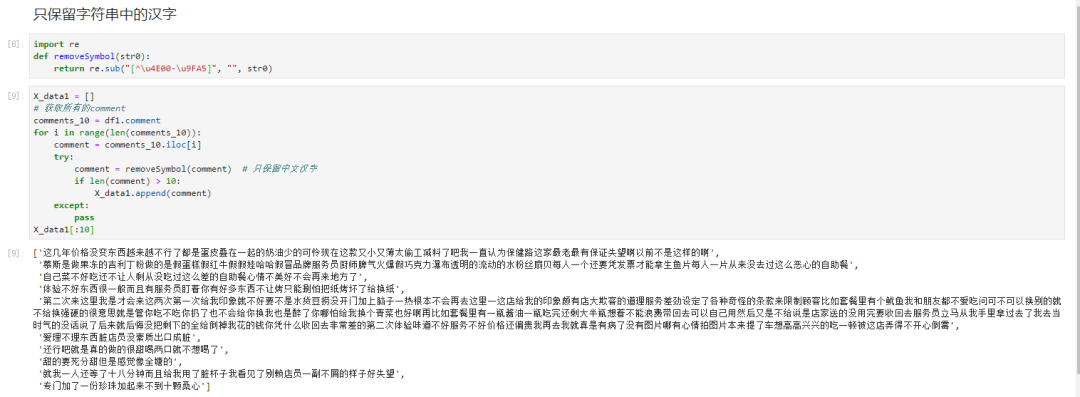
得到训练数据后,我们手工创建一个labels数组存放标签,将其转换为numpy对象,便于后期输入到神经网络中。
import numpy as np
y_data = [0 for i in range(6000)] + [1 for i in range(6000)]
y_data = np.asarray(y_data, dtype=np.float32)
y_test_data = [0 for i in range(800)] + [1 for i in range(800)]
y_test_data = np.asarray(y_data, dtype=np.float32)
乱序处理
聪明的读者可能发现了一个问题:这份数据太有规律啦,正负情感刚好前后各占一半。假如前3000条评论机器全判断为负面,能证明准确率有100%吗?
为了避免数据分布不规律的现象,我们需要为数据“洗牌”。
X_train, y_train = [], []
nums = np.arange(12000)
# 随机打乱12000个训练数据
np.random.shuffle(nums)
for i in nums:
X_train.append(X_data[i])
y_train.append(y_data[i])
简单的数据预处理完成后,还有一个问题。
这儿的数据全都是中文,即便是英文字母,计算机也一概不认识。所以需要一个额外的“翻译”步骤。
02 快速获得中文词向量
在自然语言处理任务中,需要考虑词如何在计算机中表示。常见的表示方法有两种:
one-hot representation (独热编码) distribution representation
第一种是离散表示方法,得到高维度的稀疏矩阵;第二种方法是将词表示成固定长度的密集型向量,即词向量。
从头训练一个有效的语言模型耗时又耗能。本例中,我们借助腾讯AI实验室发布的bert-as-service接口,通过两行代码,即可使用预训练的Bert模型生成句向量和词向量。
这两行代码怎么用呢?
from bert_serving.client import BertClient
bc = BertClient
# 将待训练的中文数据转换为(,768)维的句向量
input_train = bc.encode(X_train)
bert-as-service服务将一个句子统一转换成768维的句向量,最终我们得到了[12000 * 768]维度的特征矩阵,也就是神经网络的真正输入。
03 情感分类模型实现
有了输入特征,模型训练部分就比较简单了,尤其是有Keras这样的工具。
Keras是一个高层神经网络API,纯python编写并使用Tensorflow等框架作为后端,特点是简洁、快速。
直接使用pip或conda指令即可安装Keras和Tensorflow。
# 使用国内镜像加速安装
$ pip install keras -i https://pypi.douban.com/simple
$ pip install tensorflow -i https://pypi.douban.com/simple
使用Keras实现一个神经网络模型大致分四步:
定义训练数据:输入张量和目标张量 逐层定义网络,将输入映射到目标 配置学习过程:选择损失函数、优化器和监控指标 调用模型的 fit 方法在训练数据上多次迭代
我们直接使用使用Sequential类来定义模型(仅用于层的线性堆叠,是最常见的网络架构)。
from keras.models import Sequential
from keras.layers import Dense, Dropout
import tensorflow as tf
model = Sequential()
# 搭建模型
model.add(Dense(32, activation='relu', input_shape=(768,)))
model.add(Dropout(0.3))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
对于简单的二分类问题,使用Dense全连接层已经足够,最后的输出是0~1之间的小数,代表了正面/负面情感的概率。为了防止过拟合,在模型中加入了Dropout层,
接下来,我们指定模型使用的优化器和损失函数,以及训练过程中想要监控的指标。
model.compile(
loss='binary_crossentropy',
optimizer=tf.train.AdamOptimizer(),
metrics=['acc']
)
最后,通过fit方法将输入数据传入模型。我们留出20%的数据作为验证集:
history = model.fit(
X_train, y_train,
epochs=30,
batch_size=128,
validation_split=0.2,
verbose=1
)
模型开始迭代训练了!
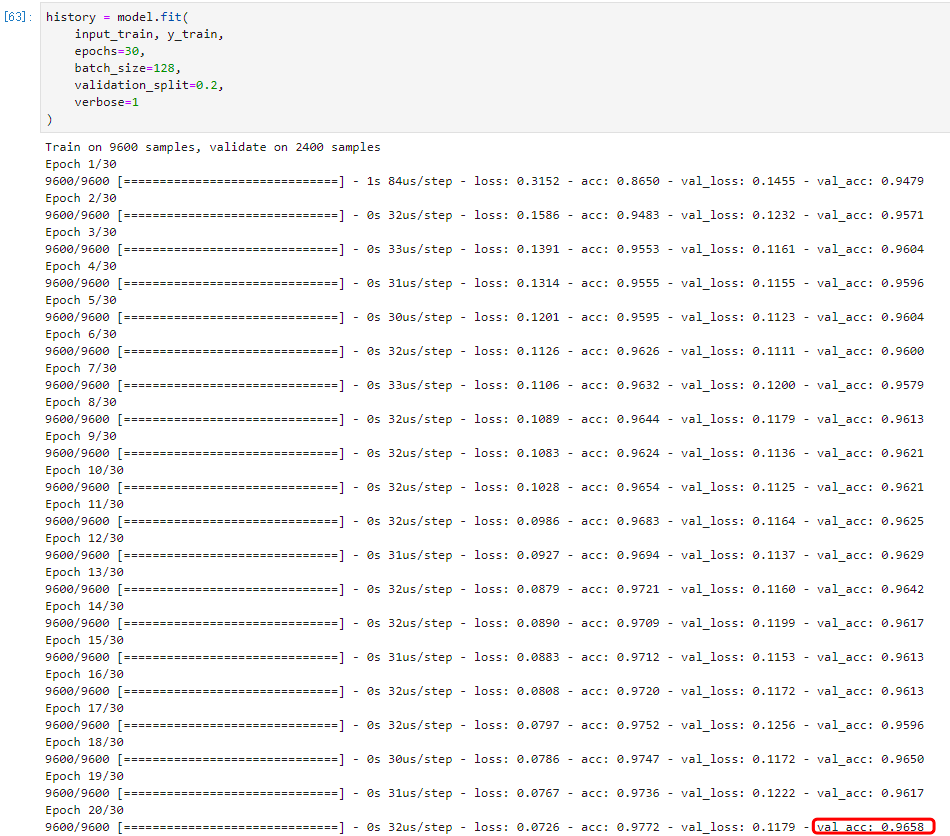
观察发现,随着迭代次数的增加,模型损失逐渐下降,准确度逐渐上升,直到趋于稳定。
运行结束后,使用matplotlib库将结果可视化呈现。
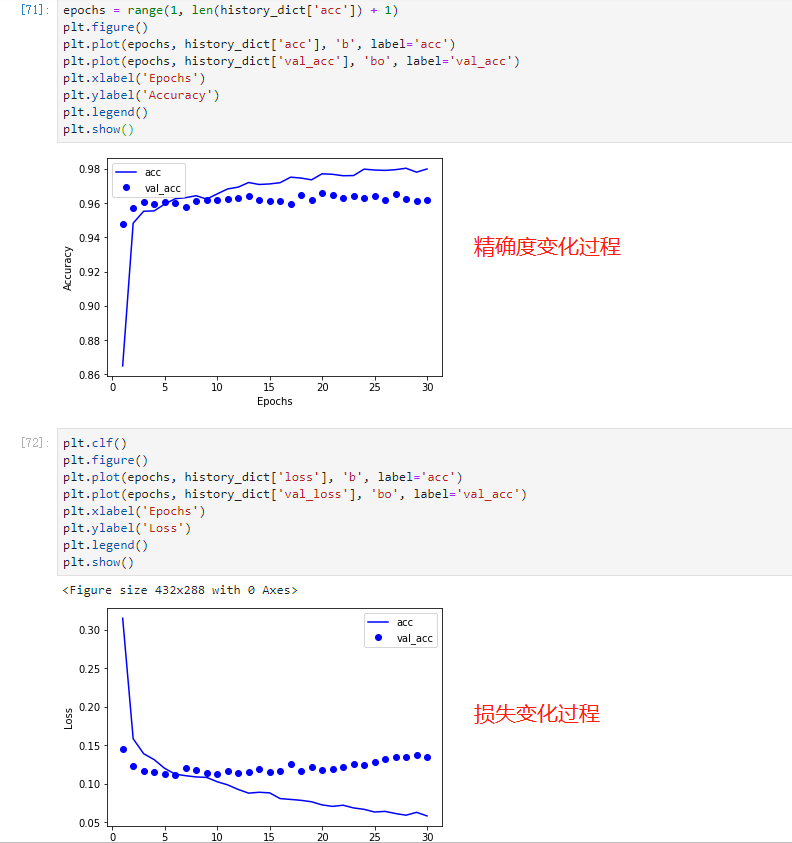
因为任务比较简单,加上Bert的特征抽取能力,模型对于判别好评还是差评有96%的准确率!
另外还有1600条数据当作测试集没有使用,调用evaluate方法测试:
test_loss = model.evaluate(
X_test,
y_test,
batch_size=64,
verbose=1
)
print(test_loss)
得到结果:[0.079560, 0.973125],表示测试集损失和准确率分别为0.07和97%。
04 小结
本文是NLP情感分类任务的入门和实现,可以让读者利用简单的数据和工具实现一个分类模型。整个过程涉及了数据处理、特征编码、模型训练和结果分析。
实际开发中,使用的模型和特征抽取方法会更加复杂,涉及更严格的测试和部署环节。今后的文章中我们将为读者继续呈现!
推 荐 阅 读
参考资料
由于微信平台算法改版,订阅号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们帮我们点【在看】。星标具体步骤:
(1)点击页面最上方“NLP情报局”,进入主页
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦
感谢支持❤️
原创不易,有收获的话请帮忙点击分享、点赞、在看🙏