
Nature封面:AI与人类斗嘴谁更强?IBM团队发布“AI辩论家”最新研究进展
来源:学术头条、大数据文摘 本文约4200字,建议阅读8分钟
本文带你了解AI的辩论能力。

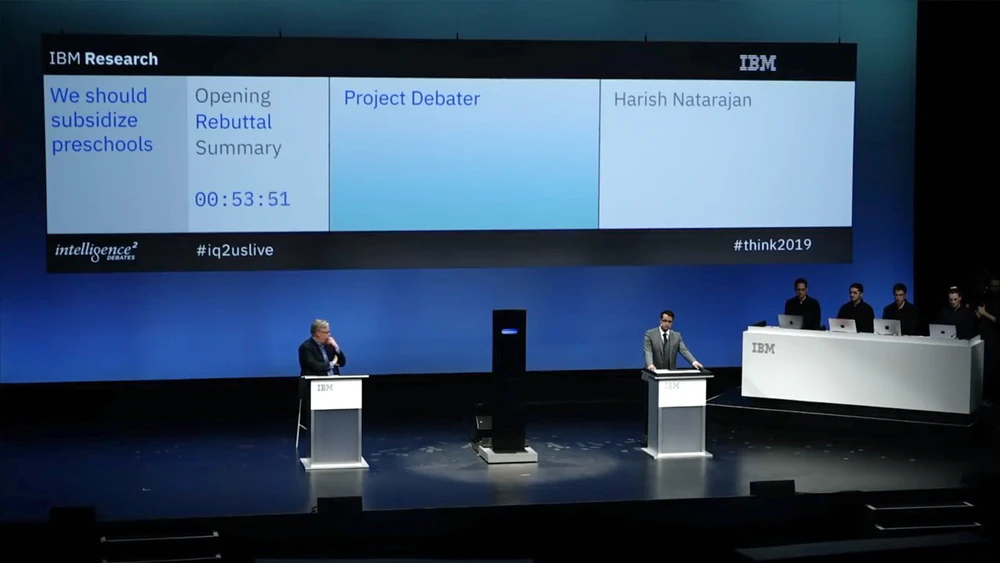

图|Project Debater 与人类选手辩论(来源:IBM)
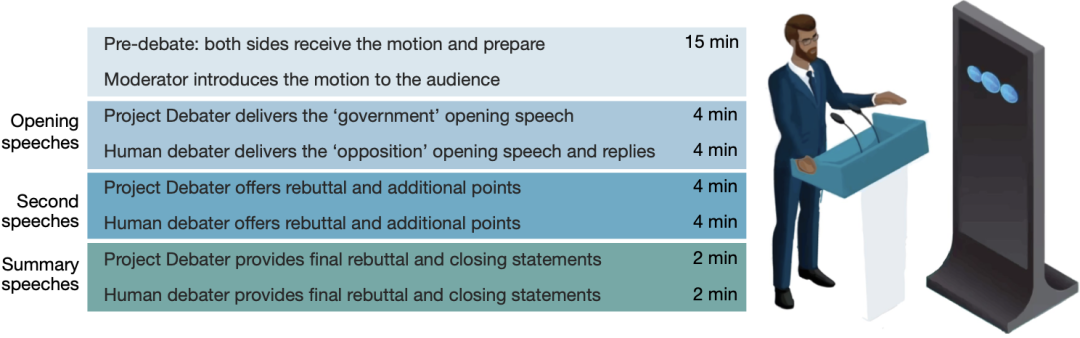
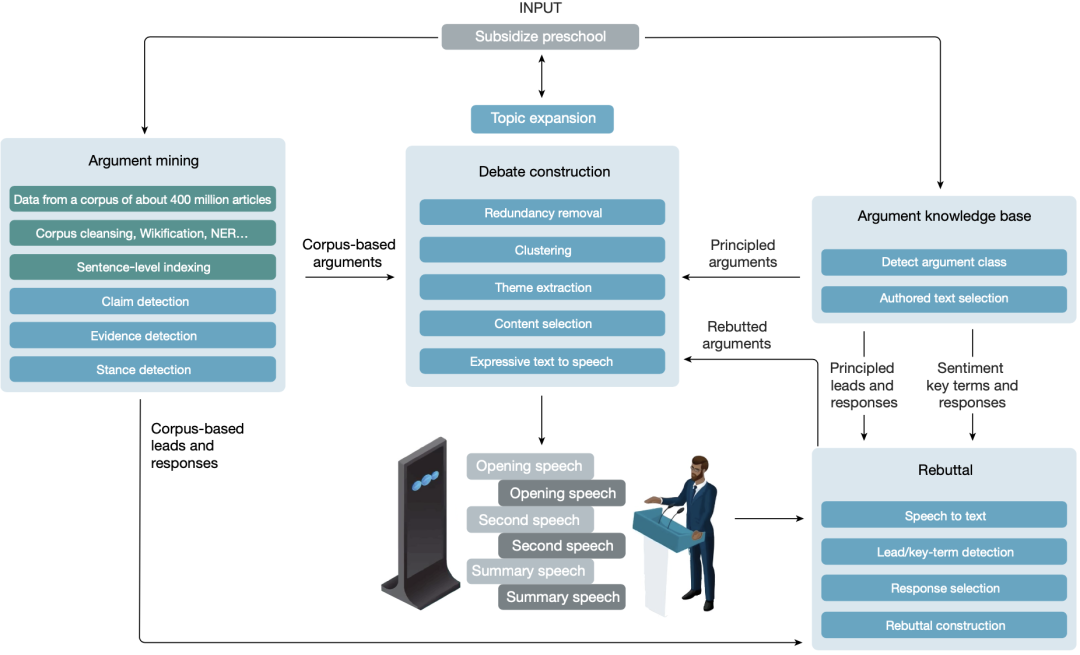
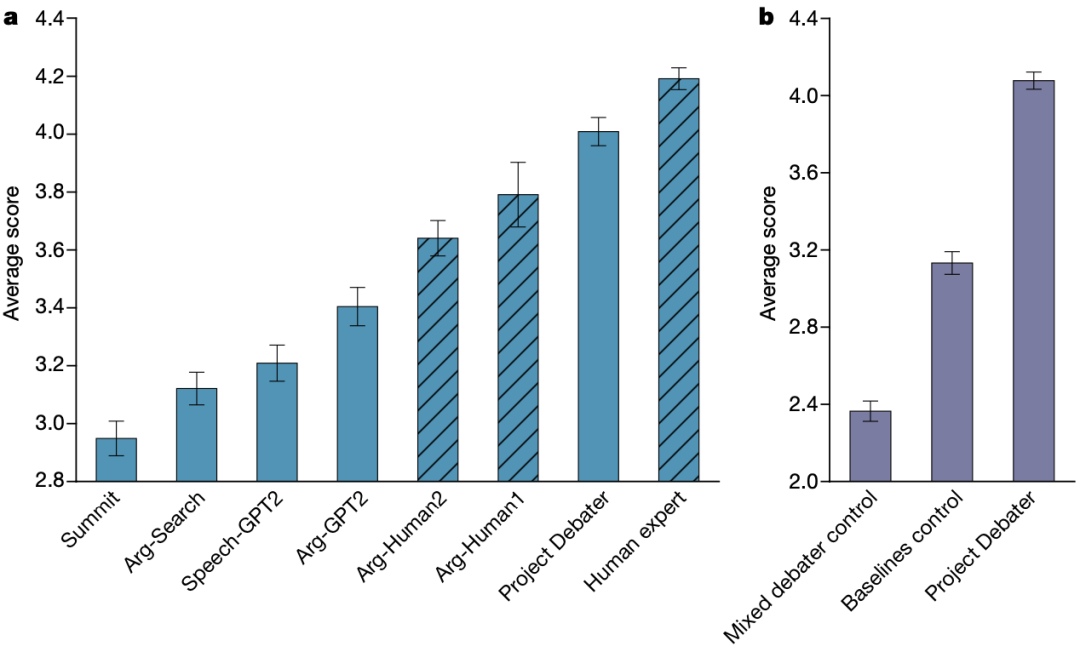

参考资料:
https://www.nature.com/articles/s41586-021-03215-w
https://www.nature.com/articles/d41586-021-00539-5https://www.research.ibm.com/artificial-intelligence/project-debater/https://www.mercurynews.com/2019/02/11/ibms-ai-loses-debate-to-human-but-has-strong-showing/
https://www.mercurynews.com/2019/02/11/ibms-ai-loses-debate-to-human-but-has-strong-showing/
评论