
浅谈高斯混合模型!
共 11783字,需浏览 24分钟
·
2021-11-05 16:27
高斯分布与高斯混合模型
1733年,法国数学家棣莫弗在一个赌博问题的探索中首次发现了正态分布的密度公式,而后由德国数学家高斯将正态分布发扬光大。高斯在拓展最小二乘法的工作中,引入正态分布作为误差分布,解决了对误差影响进行统计度量的问题,为后世的参数估计、假设检验等一系列统计分析奠定了基础。高斯关于正态分布的工作对数理统计的发展做出了杰出的贡献,因此正态分布也称为高斯分布 (Gaussian distribution)。值得说明的是,高斯分布并不是由高斯或棣莫弗“发明”的,而是本身在自然界中大量存在的,它反映了大样本下数据分布的一种一般规律。例如向某某大学的男生、女生统计身高,身高的分布大概如下图高斯分布所示,这样的分布在形态上有着明显的特征:单峰、对称、中间高两边低。
 图1 某某大学男生、女生身高分布
图1 某某大学男生、女生身高分布
在数据分析的课程学习中,高斯分布恐怕是我们打交道最多的分布了。它的密度函数公式为
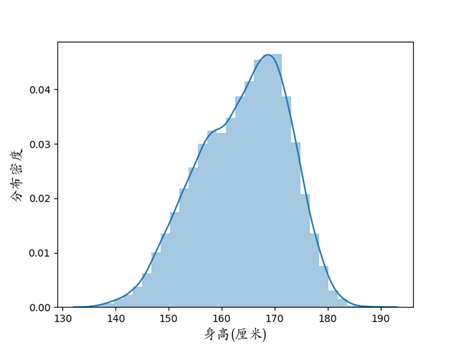 图2 某某大学全体学生身高分布
图2 某某大学全体学生身高分布
高斯混合模型的EM求解
EM算法是1977年由Dempster等整理提出的一种迭代算法,可以处理含隐变量的极大似然估计问题。如果把更新参数估计这件事类比为走路(空间位置的更新),EM算法就好比人用两只脚交替地走路,左脚控制隐变量,右脚控制参数估计,左脚站稳了迈右脚,右脚站稳了迈左脚,这样左一步右一步,步步为营,就可以到达终点,也就是最终收敛到的参数估计。
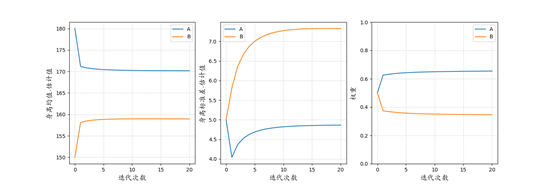 图3 EM算法求解高斯混合模型
图3 EM算法求解高斯混合模型
表1 估计结果
| A | B | |
|---|---|---|
| 均值 | 170.41 | 158.67 |
| 标准差 | 4.70 | 6.94 |
| 权重 | 0.65 | 0.35 |
| 男生 | 女生 | |
| 均值 | 169.93 | 157.85 |
| 标准差 | 4.93 | 6.93 |
高斯混合模型的应用
高斯混合模型在许多领域有着广泛应用。许多复杂的分布都可以用高斯混合模型来拟合,例如Singh et al. (2009) 应用高斯混合模型来近似电力负载的分布,为电力网络的分析和调度优化提供数据支持。Wang et al. (2011) 使用高斯混合模型结合多维传递函数来建模三维的体积数据,如图5所示,对CT扫描的零件、骨骼等能够很好地区分不同形态特征的区块。
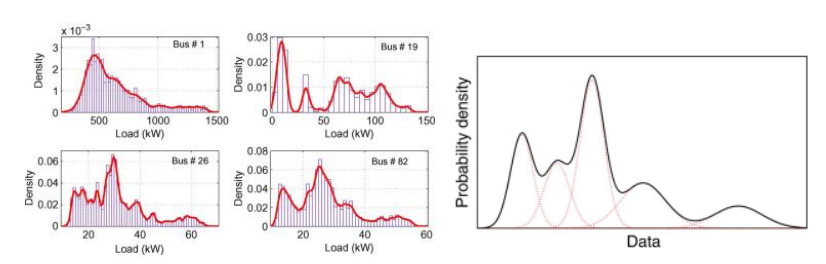 图4 利用高斯混合模型分析电力负载
图4 利用高斯混合模型分析电力负载
来源:Singh, R., Pal, B. C., & Jabr, R. A. (2009). Statistical representation of distribution system loads using Gaussian mixture model. IEEE Transactions on Power Systems, 25(1), 29-37.
 图5 利用高斯混合模型建模
图5 利用高斯混合模型建模
来源:Wang, Y., Chen, W., Zhang, J., Dong, T., Shan, G., & Chi, X. (2011). Efficient volume exploration using the gaussian mixture model. IEEE Transactions on Visualization and Computer Graphics, 17(11), 1560-1573.
在图像处理、计算机视觉中,高斯混合模型可用于区分背景和运动的物体,实现背景提取、目标检测(Zivkovic, 2004; Singh, 2016; Cho et al., 2019)。图6是一个典型的例子:一个摄像头持续监控一片区域,那么背景部分的像素值应该相对稳定,变化不大,而运动目标对应的像素值在拍摄的不同帧之间应该变动剧烈。因此可以用高斯混合模型对像素值的分布进行建模,然后对拍摄到的每一帧,都可以计算所有像素关于各个高斯成分的权重系数。若一个像素的权重系数在不同帧之间出现剧烈变化,那么这个像素对应的应该是运动目标,反之则对应静态的背景。可以看到在图6中,基于高斯混合模型的方法能够识别出公路两侧为背景区域,而公路的车道是运动目标出现的位置。需要补充说明的是,在图像的高斯混合模型中,每个高斯成分都是2维的,和身高数据中一维的场景不同。在多维的高斯混合模型中,需要估计的高斯分布参数为均值向量和协方差矩阵,可类似一维时的求解,应用EM算法来迭代地估计。
 图6 原始图片(左)和基于高斯混合模型提取的背景部分(右)
图6 原始图片(左)和基于高斯混合模型提取的背景部分(右)
来源:Zivkovic, Z. (2004). Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004. (Vol. 2, pp. 28-31). IEEE.
贝叶斯高斯混合模型
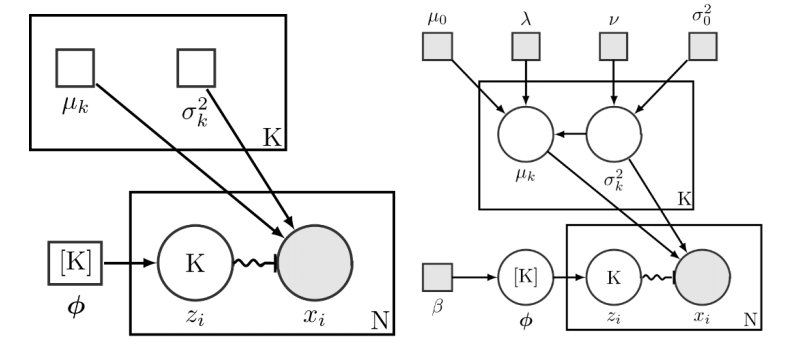 图7 高斯混合模型(左)和贝叶斯高斯混合模型(右)示意图
图7 高斯混合模型(左)和贝叶斯高斯混合模型(右)示意图
来源:Wiki百科
对贝叶斯高斯混合模型的估计,在EM算法之外,通常可采用Markov chain Monte Carlo (MCMC)方法来近似计算后验分布,主要思路为迭代地抽样数据,产生一个Markov链,并且使该Markov链的平稳分布和目标后验分布相同,那么通过大量迭代,就可以近似模拟后验分布的表现。在MCMC中具体的每次迭代里,可应用Gibbs采样方法或Metropolis-Hastings方法,通过基于当前估计值的条件分布来抽样数据。类似前面提到EM算法的“两步交替前进”,在MCMC估计贝叶斯高斯混合模型时,对隐变量和参数(此时视为随机变量)的抽样也是交替进行,并产生隐变量和参数的两个抽样链条,通过这两个链收敛到的平稳分布,即可近似计算相应的后验估计。关于贝叶斯高斯混合模型,可以参考Robert (1996) 在著作《Markov Chain Monte Carlo in Practice》中的综述,Mengersen et al. (2010) 的著作《Mixtures: Estimation and Applications》。值得注意的是,通过贝叶斯框架来审视高斯混合模型,能够带来“翻天覆地”的新知。例如,在贝叶斯高斯混合模型中,我们的关注点已经从“用若干个高斯分布的混合来拟合数据”转变为了“探索拟合数据的后验分布”。而从先验分布、似然、再到后验分布的方式建模时,限制高斯成分的个数并不是非常必要。Rasmussen (1999)在计算机领域顶会NIPS上就曾提出基于贝叶斯框架的无限高斯混合模型(infinite Gaussian mixture model),去掉了关于高斯成分个数的限制。
高斯混合模型的调优和拓展
男生女生身高的估计显示了一个成功使用EM算法求解高斯混合模型的例子,但这样的成功可能是非常“脆弱”的。例如,算法的开始我们对所有参数赋予了初始估计值,即确定了初始状态,实际上初始状态的选择对最后算法收敛到的结果是有影响的。图8即是一个失败的例子:初始状态设置为A和B的均值估计相同,结果使得算法收敛结果为A和B两组无法区分开(对应的曲线完全重叠),参数估计陷入失败。这也启发我们,一个良好的初始状态应当使得不同组的初始参数尽可能有差异。为此,一个常用的方法是先对全体观测到的样本用K-means粗略聚成多个簇,以不同簇的簇中心作为初始的参数估计,从而让EM算法从一个比较分散的初始状态开始。
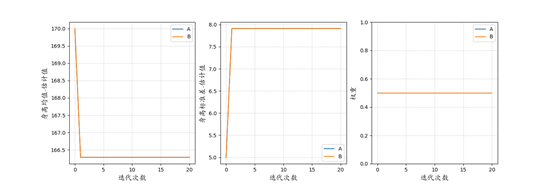 图8 EM算法求解高斯混合模型——一个失败的例子
图8 EM算法求解高斯混合模型——一个失败的例子
初始状态如果选择不当,EM算法求得的结果很可能陷入局部最优解,尤其是在初始状态和真实参数偏离很远时。对此,可采用改进的EM算法。例如确定性退火EM算法(Ueda & Nakano, 1998),它在EM算法中加入了模拟退火机制,使得参数估计在每次迭代更新时能够在一定范围内波动,从而有几率跳出局部最优解。
上述工作关注于如何选择合适的高斯成分个数,事实上还存在另一种思路:在EM迭代估计的过程中,动态调整高斯成分的个数。Ueda et al. (2000)提出split and merge EM (SMEM),在EM算法的迭代更新中,动态将部分高斯成分合并成一个,或者将一个高斯成分替换成若干个。该方法中高斯成分的总个数时不变的。Zhang et al. (2004) 在此基础上提出一种Competitive EM算法,它在EM算法的迭代中以似然函数为标杆,也能够分裂或者合并高斯成分,同时对高斯成分的个数不做限制,可以自动选择使当前似然函数值最大化的高斯成分个数。
最后,既然高斯分布可以作为混合模型的基本成分,那么其他的分布是否也可以用来构建混合模型呢?答案是肯定的。Weibull分布、t分布、对数高斯分布、Gamma分布,甚至不限定形式的任意分布函数,都可以用于混合模型。关于这样更为一般性的混合分布,可参考McLachlan et al.(2019)对有限混合模型的综述。虽然多种分布形式都可以用于有限混合模型的建模,但高斯混合模型无疑是混合模型中最常见、最实用的一类。这得益于高斯分布的优良数学性质。Li & Barron (1999) 指出,若考察所有高斯混合分布函数构成的集合,以及所有分布函数组成的集合,那么L1度量下,前者在后者中是稠密的。因而,对任意一个未知的分布密度函数,都可以用一组高斯成分的混合来估计。高斯混合模型的优良性质和计算上的便捷奠定了它在各种数据分析、数据挖掘任务中难以动摇的地位。
参考文献
Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39(1), 1-22.
Singh, R., Pal, B. C., & Jabr, R. A. (2009). Statistical representation of distribution system loads using Gaussian mixture model. IEEE Transactions on Power Systems, 25(1), 29-37.
Wang, Y., Chen, W., Zhang, J., Dong, T., Shan, G., & Chi, X. (2011). Efficient volume exploration using the gaussian mixture model. IEEE Transactions on Visualization and Computer Graphics, 17(11), 1560-1573.
Zivkovic, Z. (2004). Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004. (Vol. 2, pp. 28-31). IEEE.
Singh, N., Arya, R., & Agrawal, R. K. (2016). A convex hull approach in conjunction with Gaussian mixture model for salient object detection. Digital Signal Processing, 55, 22-31.
Cho, J., Jung, Y., Kim, D. S., Lee, S., & Jung, Y. (2019). Moving object detection based on optical flow estimation and a Gaussian mixture model for advanced driver assistance systems. Sensors, 19(14), 3217.
Melnykov, V., & Maitra, R. (2010). Finite mixture models and model-based clustering. Statistics Surveys, 4, 80-116.
Scrucca, L., Fop, M., Murphy, T. B., & Raftery, A. E. (2016). Mclust 5: clustering, classification and density estimation using Gaussian finite mixture models. The R Journal, 8(1), 289.
Robert, C. P. (1996). Mixtures of distributions: inference and estimation. Markov Chain Monte Carlo in Practice, 441, 464.
Mengersen, K. L., Robert, C., & Titterington, M. (2011). Mixtures: Estimation and Applications (Vol. 896). John Wiley & Sons.
Rasmussen, C. E. (1999, November). The infinite Gaussian mixture model. In NIPS (Vol. 12, pp. 554-560).
Ueda, N., & Nakano, R. (1998). Deterministic annealing EM algorithm. Neural Networks, 11(2), 271-282.
Chen, J. (1995). Optimal rate of convergence for finite mixture models. The Annals of Statistics, 221-233.
Schwarz, G. (1978). Estimating the dimension of a model. The annals of Statistics, 461-464.
Hartigan, J. A. (1985). Statistical theory in clustering. Journal of Classification, 2(1), 63-76.
McLachlan, G. J. (1987). On bootstrapping the likelihood ratio test statistic for the number of components in a normal mixture. Journal of the Royal Statistical Society: Series C (Applied Statistics), 36(3), 318-324.
Tibshirani, R., Walther, G., & Hastie, T. (2001). Estimating the number of clusters in a data set via the gap statistic. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 63(2), 411-423.
Chen, H., Chen, J., & Kalbfleisch, J. D. (2004). Testing for a finite mixture model with two components. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 66(1), 95-115.
Aitkin, M., & Rubin, D. B. (1985). Estimation and hypothesis testing in finite mixture models. Journal of the Royal Statistical Society: Series B (Methodological), 47(1), 67-75.
Ueda, N., Nakano, R., Ghahramani, Z., & Hinton, G. E. (2000). SMEM algorithm for mixture models. Neural Computation, 12(9), 2109-2128.
Zhang, B., Zhang, C., & Yi, X. (2004). Competitive EM algorithm for finite mixture models. Pattern Recognition, 37(1), 131-144.
Li, J. Q., & Barron, A. R. (1999). Mixture Density Estimation. In NIPS (Vol. 12, pp. 279-285).
McLachlan, G. J., Lee, S. X., & Rathnayake, S. I. (2019). Finite mixture models. Annual Review of Statistics and Its Application, 6, 355-378.
- END -