
ECCV 2020 | 可解释和泛化的行人再辨识
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转载自机器之心。
作者:廖胜才
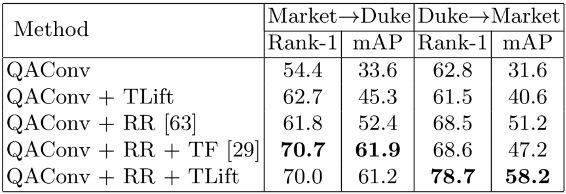
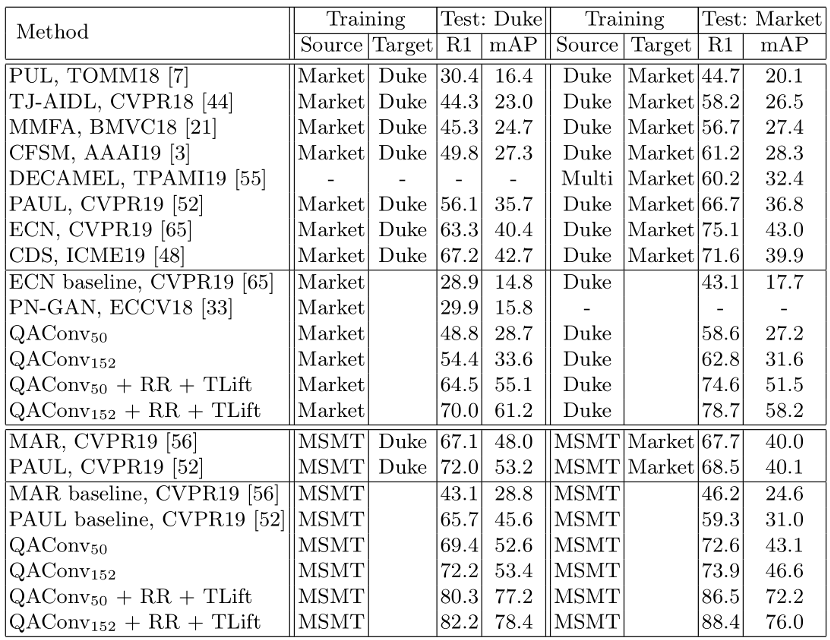
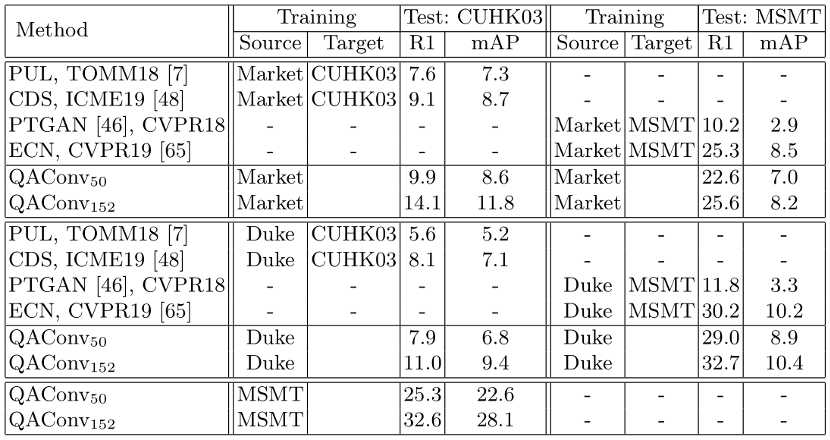
阿联酋起源人工智能研究院(IIAI)科学家提出一种可解释和泛化的行人再辨识方法,通过查询图自适应的卷积和相似度的时序提举,该方法的预训练模型无需迁移学习即可在 Market-1501 上达到 88.4% 的 Rank-1 和 76.0% 的 mAP,从而为实际应用发展了开箱即用的行人再辨识。相关论文已被 ECCV 2020 接收。

论文地址:https://arxiv.org/abs/1904.10424
代码地址:https://github.com/ShengcaiLiao/QAConv

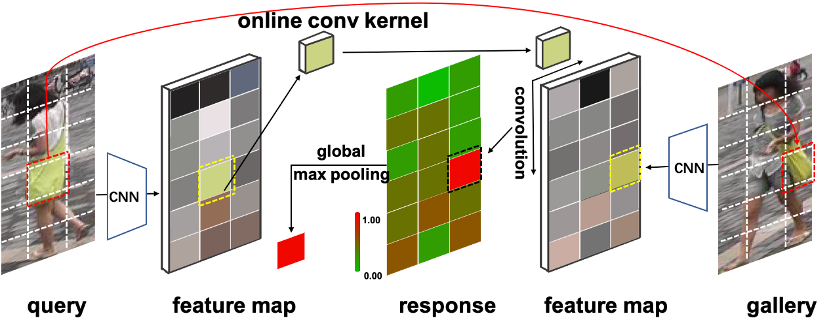
QAConv 训练时的网络结构如图 3 所示,包含骨干网络、QAConv 模块、类别记忆模块、全局最大池化(GMP)、BN-FC-BN 度量学习模块和损失函数。
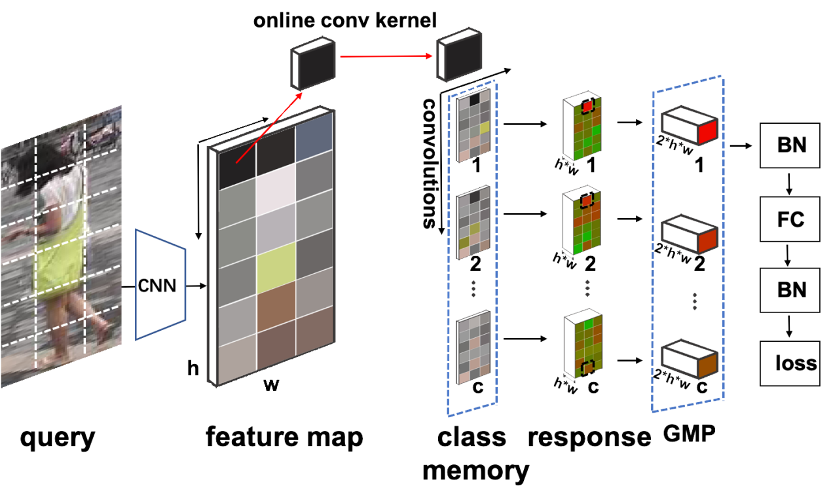
在 BN-FC-BN 模块之后,我们采用了一个 sigmoid 函数将相似度分数映射到 [0,1] 区间,并计算二值交叉熵损失。由于负样本对比正样本对多得多,为了平衡样本分布同时在线挖掘难例样本,我们也采用了 focal loss 来加权损失。
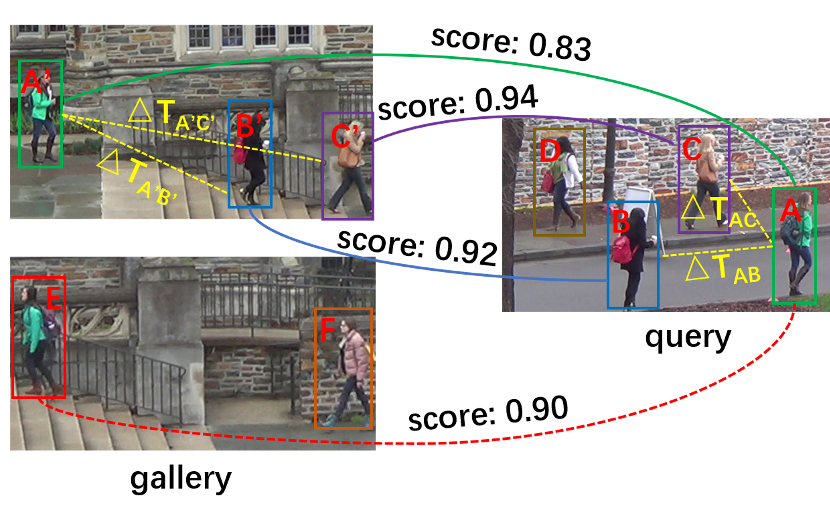
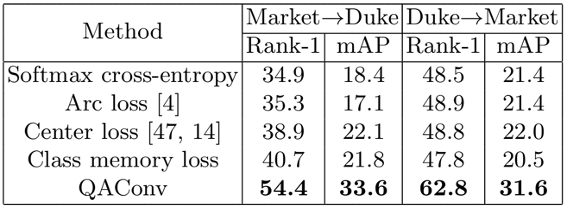
END
评论