
干货!机器学习中,如何优化数据性能

来源:AI科技大本营 本文约2000字,建议阅读5分钟 本文主要通过优化数据结构以及一些使用中的注意点来提高在大数据量下数据的处理速度。

头图 | 下载于视觉中国
本文主要通过优化数据结构以及一些使用中的注意点来提高在大数据量下数据的处理速度。
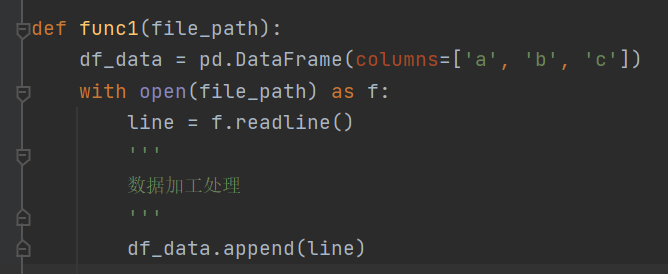


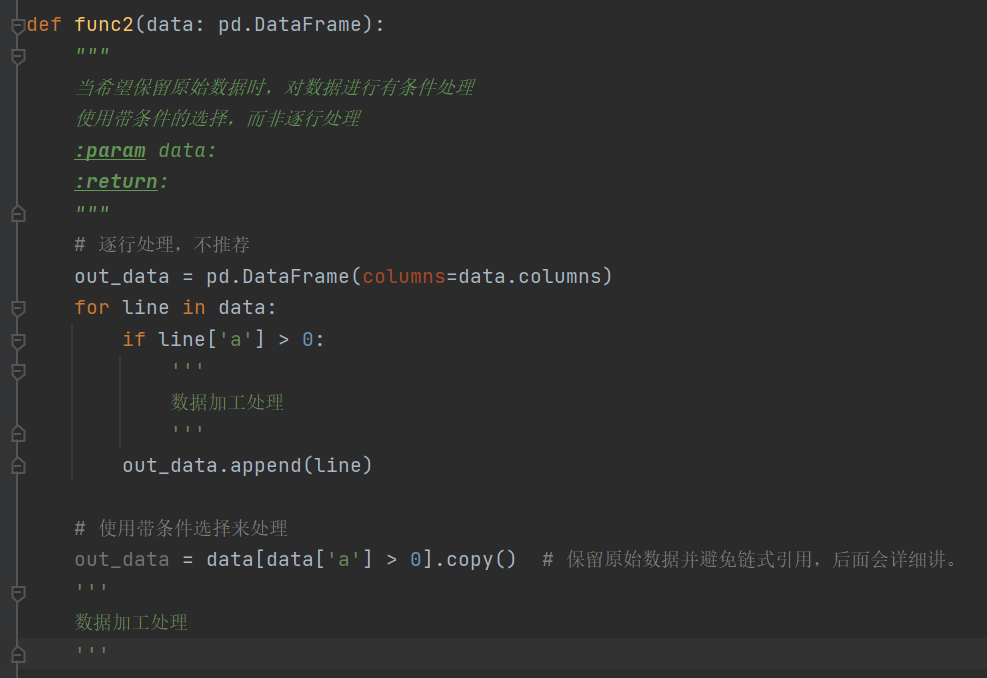
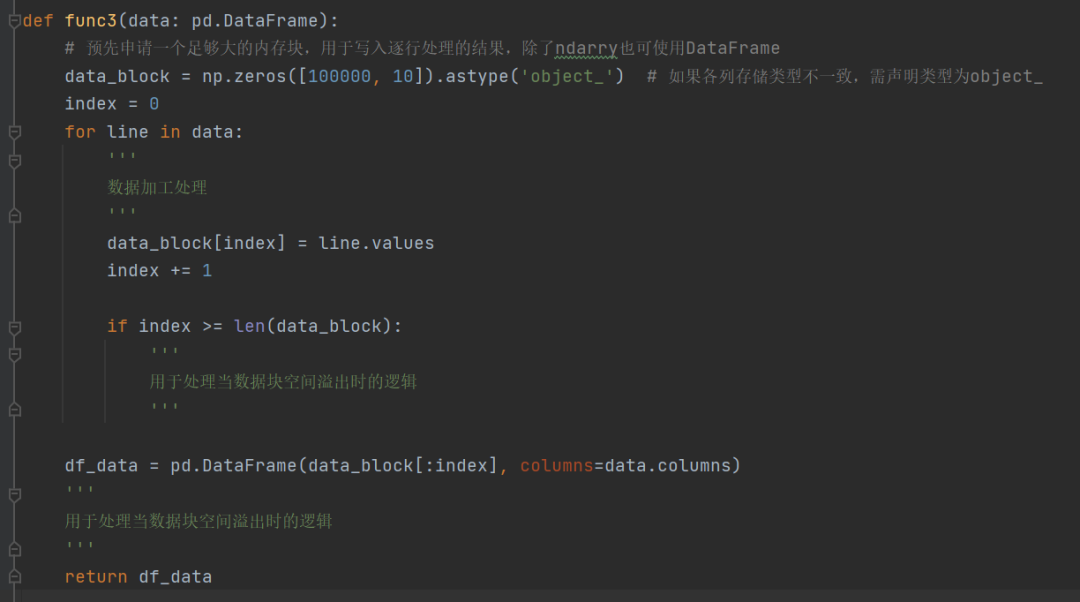
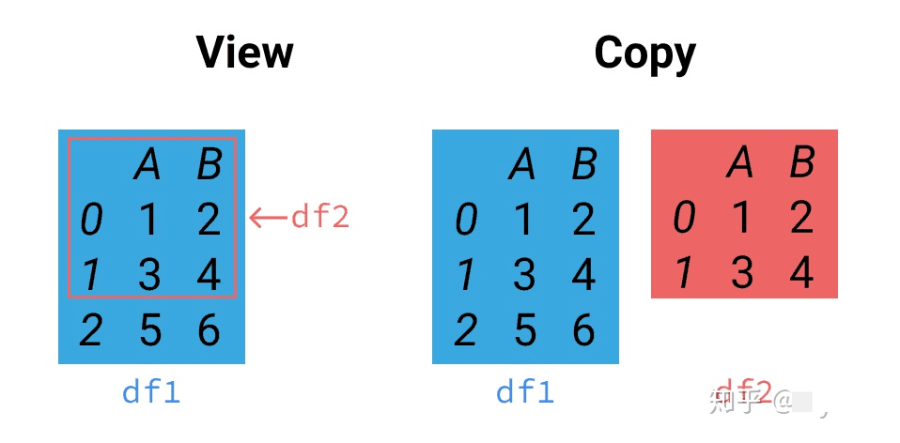
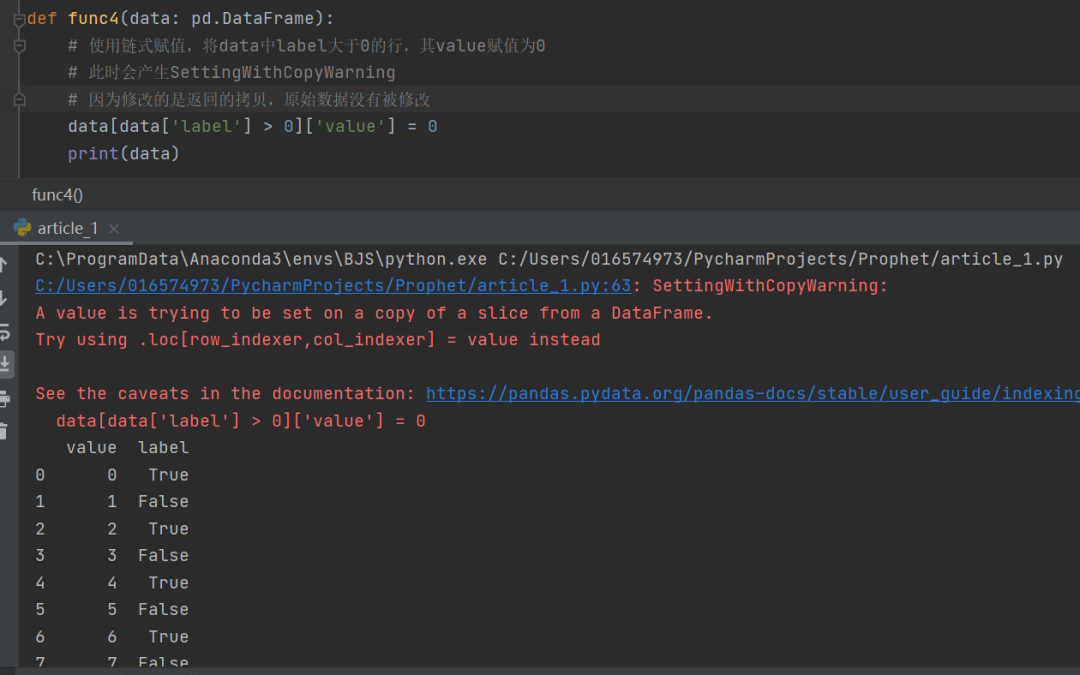

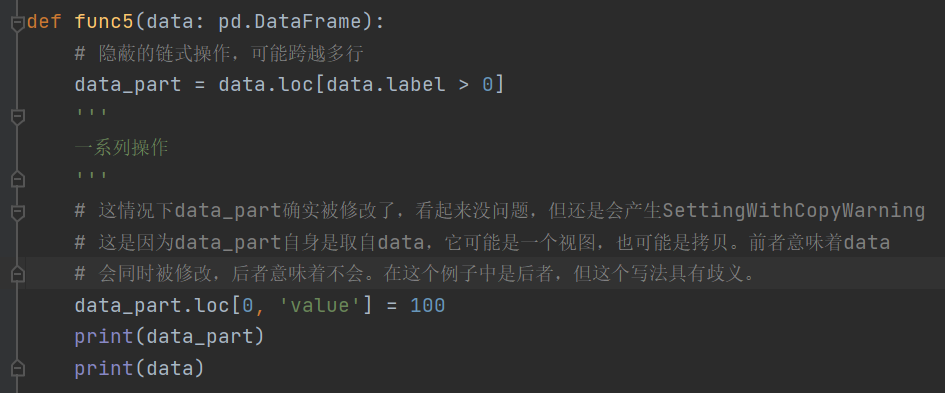

参考资料:
https://numpy.org/doc/stable/reference/generated/numpy.append.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.append.html
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#indexing-label
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#indexing-view-versus-copy
https://zhuanlan.zhihu.com/p/41202576
编辑:王菁
校对:林亦霖
评论