
实操教程|使用Python+OpenCV实现姿态估计

极市导读
本文详细介绍了如何使用Mediapipe和OpenCV实现姿态估计,附有相关代码及视频。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
什么是OpenCV?
计算机视觉是一个能够理解图像和视频如何存储和操作的过程,它还有助于从图像或视频中检索数据。计算机视觉是人工智能的一部分。
计算机视觉在自动驾驶汽车,物体检测,机器人技术,物体跟踪等方面发挥着重要作用。
OpenCV
OpenCV是一个开放源代码库,主要用于计算机视觉,图像处理和机器学习。通过OpenCV,它可以为实时数据提供更好的输出,我们可以处理图像和视频,以便实现的算法能够识别诸如汽车,交通信号灯,车牌等物体以及人脸,或者甚至是人类的笔迹。借助其他数据分析库,OpenCV能够根据自己的需求处理图像和视频。
可以在这里获取有关OpenCV的更多信息 https://opencv.org/
我们将与OpenCV-python一起使用的库是Mediapipe
什么是Mediapipe?
Mediapipe是主要用于构建多模式音频,视频或任何时间序列数据的框架。借助MediaPipe框架,可以构建令人印象深刻的ML管道,例如TensorFlow,TFLite等推理模型以及媒体处理功能。
使用Mediapipe的最先进的ML模型
-
人脸检测 -
多手跟踪 -
头发分割 -
目标检测与追踪 -
Objectron:3D对象检测和跟踪 -
AutoFlip:自动视频裁剪管道 -
姿态估计
姿态估计
通过视频或实时馈送进行人体姿态估计在诸如全身手势控制,量化体育锻炼和手语识别等各个领域中发挥着至关重要的作用。
例如,它可用作健身,瑜伽和舞蹈应用程序的基本模型。它在增强现实中找到了自己的主要作用。
Media Pipe Pose是用于高保真人体姿势跟踪的框架,该框架从RGB视频帧获取输入并推断出整个人类的33个3D界标。当前最先进的方法主要依靠强大的桌面环境进行推理,而此方法优于其他方法,并且可以实时获得很好的结果。
姿势地标模型
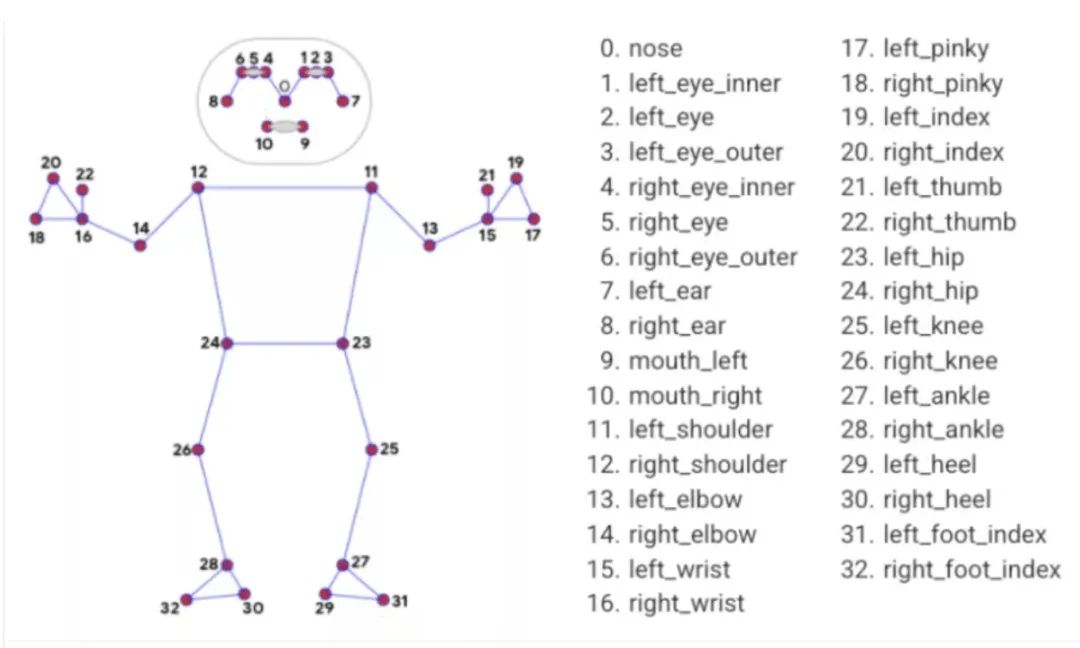
来源:https://google.github.io/mediapipe/solutions/pose.html
现在开始
首先,安装所有必需的库。
– pip install OpenCV-python– pip install mediapipe
下载任何类型的视频,例如跳舞,跑步等。
我们将利用这些视频进行姿势估计。我正在使用下面的链接中提供的视频。
https://drive.google.com/file/d/1kFWHaAaeRU4biZ_1wKZlL4KCd0HSoNYd/view?usp=sharing
为了检查mediapipe是否正常工作,我们将使用上面下载的视频实现一个小的代码。
import cv2import mediapipe as mpimport timempPose = mp.solutions.posepose = mpPose.Pose()mpDraw = mp.solutions.drawing_utils#cap = cv2.VideoCapture(0)cap = cv2.VideoCapture('a.mp4')pTime = 0while True:success, img = cap.read()imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)results = pose.process(imgRGB)print(results.pose_landmarks)if results.pose_landmarks:mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS)for id, lm in enumerate(results.pose_landmarks.landmark):h, w,c = img.shapeprint(id, lm)cx, cy = int(lm.x*w), int(lm.y*h)cv2.circle(img, (cx, cy), 5, (255,0,0), cv2.FILLED)cTime = time.time()fps = 1/(cTime-pTime)pTime = cTimecv2.putText(img, str(int(fps)), (50,50), cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0), 3)cv2.imshow("Image", img)cv2.waitKey(1)
在上面的内容中,你可以很容易地使用OpenCV从名为“ a.mp4”的视频中读取帧,并将帧从BGR转换为RGB图像,并使用mediapipe在整个处理后的帧上绘制界标。最后,我们将获得具有地标的视频输出,如下所示。
变量“ cTime”,“ pTime”和“ fps”用于计算每秒的读取帧。你可以在下面的输出中看到左角的帧数。
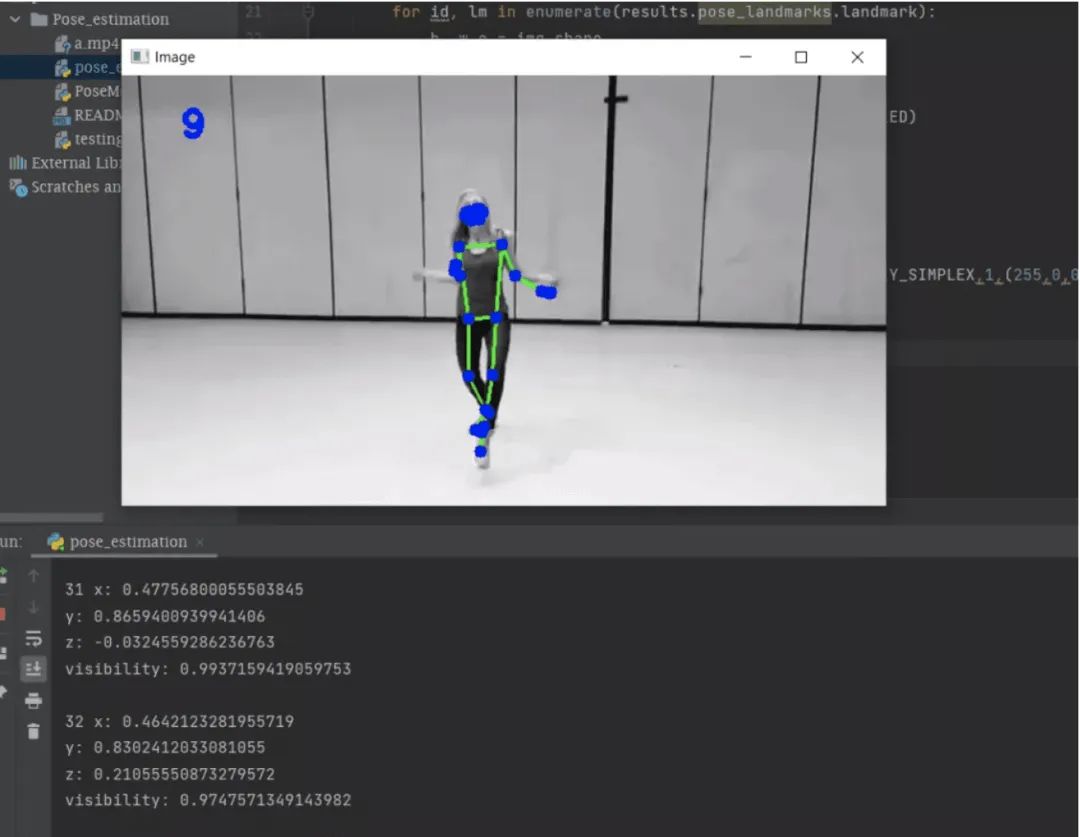
终端部分中的输出是mediapipe检测到的界标。
姿势界标
你可以在上图的终端部分中看到姿势界标的列表。每个地标包括以下内容:
-
x和y:这些界标坐标分别通过图像的宽度和高度归一化为[0.0,1.0]。 -
z:通过将臀部中点处的深度作为原点来表示界标深度,并且z值越小,界标与摄影机越近。z的大小几乎与x的大小相同。 -
可见性:[0.0,1.0]中的值,指示界标在图像中可见的可能性。
MediaPipe运行得很好。
让我们创建一个用于估计姿势的模块,并且将该模块用于与姿态估计有关的任何其他项目。另外,你可以在网络摄像头的帮助下实时使用它。
创建一个名为“ PoseModule”的python文件
import cv2import mediapipe as mpimport timeclass PoseDetector:def __init__(self, mode = False, upBody = False, smooth=True, detectionCon = 0.5, trackCon = 0.5):self.mode = modeself.upBody = upBodyself.smooth = smoothself.detectionCon = detectionConself.trackCon = trackConself.mpDraw = mp.solutions.drawing_utilsself.mpPose = mp.solutions.poseself.pose = self.mpPose.Pose(self.mode, self.upBody, self.smooth, self.detectionCon, self.trackCon)def findPose(self, img, draw=True):imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)self.results = self.pose.process(imgRGB)#print(results.pose_landmarks)if self.results.pose_landmarks:if draw:self.mpDraw.draw_landmarks(img, self.results.pose_landmarks, self.mpPose.POSE_CONNECTIONS)return imgdef getPosition(self, img, draw=True):lmList= []if self.results.pose_landmarks:for id, lm in enumerate(self.results.pose_landmarks.landmark):h, w, c = img.shape#print(id, lm)cx, cy = int(lm.x * w), int(lm.y * h)lmList.append([id, cx, cy])if draw:cv2.circle(img, (cx, cy), 5, (255, 0, 0), cv2.FILLED)return lmListdef main():cap = cv2.VideoCapture('videos/a.mp4') #make VideoCapture(0) for webcampTime = 0detector = PoseDetector()while True:success, img = cap.read()img = detector.findPose(img)lmList = detector.getPosition(img)print(lmList)cTime = time.time()fps = 1 / (cTime - pTime)pTime = cTimecv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)cv2.imshow("Image", img)cv2.waitKey(1)if __name__ == "__main__":main()
这是姿态估计所需的代码,在上面,有一个名为“ PoseDetector”的类,在其中我们创建了两个对象“ findPose”和“ getPosition”。
在这里,名为“ findPose”的对象将获取输入帧,并借助名为mpDraw的mediapipe函数,它将绘制身体上的界标,而对象“ getPosition””将获得检测区域的坐标,我们还可以借助此对象高亮显示任何坐标点。
在main函数中,我们将进行测试运行,你可以通过将main函数中的第一行更改为“ cap = cv2.VideoCapture(0)”来从网络摄像头中获取实时数据。
由于我们在上面的文件中创建了一个类,因此我们将在另一个文件中使用它。
现在是最后阶段
import cv2import timeimport PoseModule as pmcap = cv2.VideoCapture(0)pTime = 0detector = pm.PoseDetector()while True:success, img = cap.read()img = detector.findPose(img)lmList = detector.getPosition(img)print(lmList)cTime = time.time()fps = 1 / (cTime - pTime)pTime = cTimecv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)cv2.imshow("Image", img)cv2.waitKey(1)
在这里,代码将仅调用上面创建的模块,并在输入视频或网络摄像头的实时数据上运行整个算法。这是测试视频的输出。

完整的代码可在下面的GitHub链接中找到。
https://github.com/BakingBrains/Pose_estimation
链接到YouTube视频:https://www.youtube.com/watch?v=brwgBf6VB0I
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CNN综述”获取67页综述深度卷积神经网络架构~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
