
使用Python+OpenCV实现姿态估计
OpenCV
什么是Mediapipe?
使用Mediapipe的最先进的ML模型
-
人脸检测 -
多手跟踪 -
头发分割 -
目标检测与追踪 -
Objectron:3D对象检测和跟踪 -
AutoFlip:自动视频裁剪管道 -
姿态估计
姿态估计
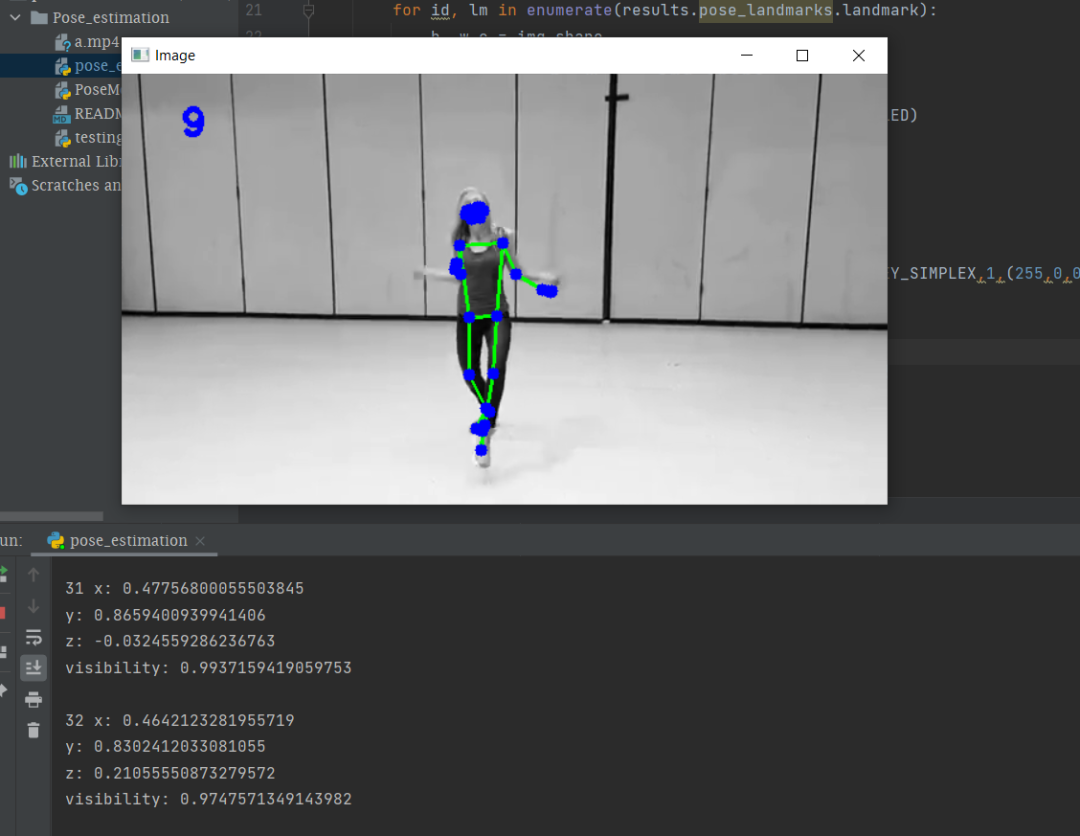
import cv2
import mediapipe as mp
import time
mpPose = mp.solutions.pose
pose = mpPose.Pose()
mpDraw = mp.solutions.drawing_utils
#cap = cv2.VideoCapture(0)
cap = cv2.VideoCapture('a.mp4')
pTime = 0
while True:
success, img = cap.read()
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = pose.process(imgRGB)
print(results.pose_landmarks)
if results.pose_landmarks:
mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS)
for id, lm in enumerate(results.pose_landmarks.landmark):
h, w,c = img.shape
print(id, lm)
cx, cy = int(lm.x*w), int(lm.y*h)
cv2.circle(img, (cx, cy), 5, (255,0,0), cv2.FILLED)
cTime = time.time()
fps = 1/(cTime-pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (50,50), cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)
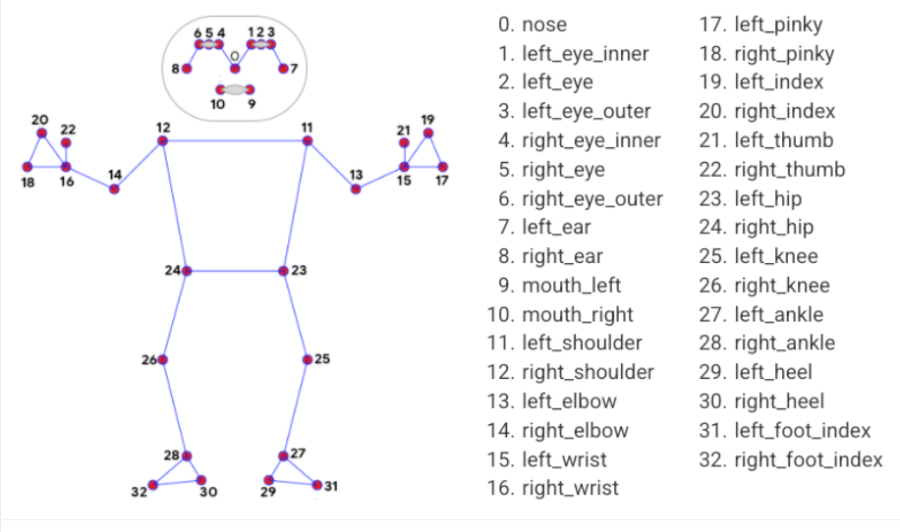
姿势界标
-
x和y:这些界标坐标分别通过图像的宽度和高度归一化为[0.0,1.0]。 -
z:通过将臀部中点处的深度作为原点来表示界标深度,并且z值越小,界标与摄影机越近。z的大小几乎与x的大小相同。 -
可见性:[0.0,1.0]中的值,指示界标在图像中可见的可能性。
import cv2
import mediapipe as mp
import time
class PoseDetector:
def __init__(self, mode = False, upBody = False, smooth=True, detectionCon = 0.5, trackCon = 0.5):
self.mode = mode
self.upBody = upBody
self.smooth = smooth
self.detectionCon = detectionCon
self.trackCon = trackCon
self.mpDraw = mp.solutions.drawing_utils
self.mpPose = mp.solutions.pose
self.pose = self.mpPose.Pose(self.mode, self.upBody, self.smooth, self.detectionCon, self.trackCon)
def findPose(self, img, draw=True):
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.results = self.pose.process(imgRGB)
#print(results.pose_landmarks)
if self.results.pose_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, self.results.pose_landmarks, self.mpPose.POSE_CONNECTIONS)
return img
def getPosition(self, img, draw=True):
lmList= []
if self.results.pose_landmarks:
for id, lm in enumerate(self.results.pose_landmarks.landmark):
h, w, c = img.shape
#print(id, lm)
cx, cy = int(lm.x * w), int(lm.y * h)
lmList.append([id, cx, cy])
if draw:
cv2.circle(img, (cx, cy), 5, (255, 0, 0), cv2.FILLED)
return lmList
def main():
cap = cv2.VideoCapture('videos/a.mp4') #make VideoCapture(0) for webcam
pTime = 0
detector = PoseDetector()
while True:
success, img = cap.read()
img = detector.findPose(img)
lmList = detector.getPosition(img)
print(lmList)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)
if __name__ == "__main__":
main()
import cv2
import time
import PoseModule as pm
cap = cv2.VideoCapture(0)
pTime = 0
detector = pm.PoseDetector()
while True:
success, img = cap.read()
img = detector.findPose(img)
lmList = detector.getPosition(img)
print(lmList)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)

个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
评论