
轻量级姿态估计技巧综述

极市导读
本文作者总结了目前自己实验过的一些姿态估计的技巧,分为三个部分:数据处理/增强篇、结构篇以及损失函数篇,更有相关复现代码。本文将持续更新,欢迎关注~>>加入极市CV技术交流群,走在计算机视觉的最前沿
数据处理&增强篇
1. 正确的归一化
将坐标值归一化到(-0.5, 0.5)之间,公式为:
由于目标检测的关系,姿态估计的对象大都会在图像的中央,用这样的归一化能很大的加速模型收敛
2. Augmentation by Information Dropping(AID)
2020 COCO Keypoint Challenge 冠军之路
地址:https://zhuanlan.zhihu.com/p/210199401
这是COCO2020 冠军团队的论文。作者认为在姿态估计任务中,模型会使用两种信息:外观信息和约束信息。外观信息是定位关键点的基础,而约束信息则在定位困难关键点时具有重要的指导意义。约束信息包括人体关键点之间固有的相互约束关系(如人体关节的活动度),以及人体和环境交互形成的约束关系。直观上看,约束信息相比于外观信息而言,更复杂多样,对于网络而言学习难度更大,这会使得在外观信息充分的情况下,存在约束条件被忽视的可能性(模型会偷懒,不学习/使用约束信息)。基于此假设,作者引入了信息丢失的正则化手段,通过在训练过程中以一定的概率丢失关键点的外观信息,以此避免训练过程拟合外观信息而忽视约束信息。

结构篇
1. Mish
CoinCheung/pytorch-loss: label-smooth, amsoftmax, focal-loss, triplet-loss, lovasz-softmax. Maybe useful
地址:https://github.com/CoinCheung/pytorch-loss
一个更强的激活函数,直接替换ReLU,使用后有涨点,但由于没有inplace,显存的占用几乎要翻倍,需要自己权衡一下
Mish的作者更新了一个Hard版本用于移动设备,同时也加入了inplace
def hard_mish(x, inplace: bool = False) :
"""Implements the HardMish activation function
Args:
x: input tensor
Returns:
output tensor
"""
if inplace:
return x.mul_(0.5 * (x + 2).clamp(min=0, max=2))
else:
return 0.5 * x * (x + 2).clamp(min=0, max=2)
class HardMish(nn.Module):
"""Implements the Had Mish activation module from `"H-Mish" `_
This activation is computed as follows:
.. math::
f(x) = \\frac{x}{2} \\cdot \\min(2, \\max(0, x + 2))
"""
def __init__(self, inplace: bool = False) -> None:
super().__init__()
self.inplace = inplace
def forward(self, x):
return hard_mish(x, inplace=self.inplace)
近期出了一些轻量级模型的工程化优化的工作,如pplcnet,esnet,rmnet等,大家普遍地使用了hardswish,因此我专门做了实验对比一下hardmish和hardswish
训练了一个我自己魔改出来的轻量模型,结构上是repvgg-like:
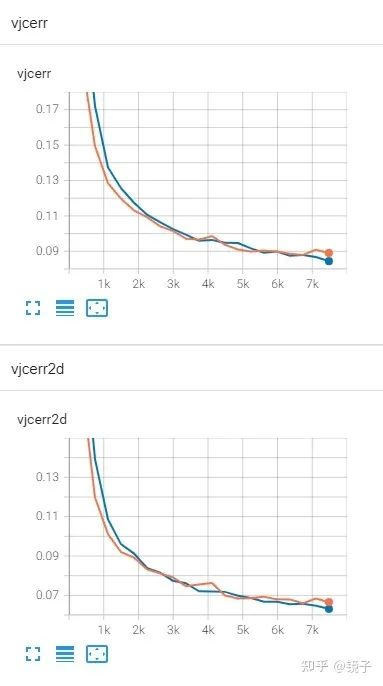
蓝色是hardswish,黄色是hardmish,从我的实验可以看出,在训练初期hardmish损失下降是更快的,但是后续的波动比较大,稳定性不如hardswish。我的实验在4卡上跑了两天,到这里训练也还没有结束,因此不好断定最终收敛时的性能表现,但总体上可以判断的是,这二者的性能是接近的,但hardswish稳定性更胜一筹。
显存的占用上,都开inplace的情况下显存使用基本一样,而从计算量的角度对比如下:
hardmish
deploy macs: 127.173792
mnn_inference: 9.927172660827637
mnn_inference: 9.442970752716064
mnn_inference: 9.6360182762146
mnn_inference: 9.197959899902344
mnn_inference: 11.279244422912598
hardswish
deploy macs: 126.910368
mnn_inference: 11.386265754699707
mnn_inference: 11.019973754882812
mnn_inference: 8.461620807647705
mnn_inference: 9.613375663757324
mnn_inference: 11.782505512237549
relu
deploy macs: 126.646944
mnn_inference: 9.963874816894531
mnn_inference: 11.411187648773193
mnn_inference: 9.003558158874512
mnn_inference: 8.894507884979248
mnn_inference: 10.858681201934814
可以看出hardmish的计算量是高于hardswish的,因此综合来看使用hardswish是更高性价比的选择。
附上hardswish的pytorch实现:
def hard_sigmoid(x, inplace=False):
return nn.ReLU6(inplace=inplace)(x + 3) / 6
def hard_swish(x, inplace=False):
return x * hard_sigmoid(x, inplace)
class HardSwish(nn.Module):
def __init__(self, inplace=False):
super(HardSwish, self).__init__()
self.inplace = inplace
def forward(self, x):
return hard_swish(x, inplace=self.inplace)
2. RepVGG
工业界非常solid的一个工作,利用重参化技巧,可以将多分支的卷积操作合并成一次卷积操作,且真正做到计算结果完全一致。在我实际的项目中,通过调整各阶段模块数和width得到的小模型,在推理速度一样的情况下精度能甩shufflenet和mobilenet很多。
更多细节可以去看作者的文章:
丁霄汉:RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021)
https://zhuanlan.zhihu.com/p/344324470
3. OKDHP和NetAug
OKDHP的全称是Online Knowledge Distillation for Efficient Pose Estimation,总体的思路是为要训练的轻量模型增加几个分支,每个分支都学跟原来模型一样的东西,每个分支可以跟原来的模型一样,也可以不一样,这样相当于同时训练了多个小模型,将结果进行集成。由于集成学习的思想,我们知道小模型集成后的结果往往是好于单个模型的,因此我们可以把集成的结果当成蒸馏中教师网络的输出,让小模型去逼近集成的结果。

传统的蒸馏学习需要先训练一个大网络,训练完毕后作为教师,然后让小网络逼近教师的输出,蒸馏的对象可以是feature也可以是logits。而这里通过集成得到了一个更强的网络,我们可以比作是集成得到了一个学习能力更强的学霸学生,让普通学生跟这个学霸学习,尽管大家都是一样的起点,但学霸能力更强,所以普通学生还是可以从他身上学到一点东西。也可以看成是几个普通学生每次学完后开会互相讨论一下,总结经验教训,然后大家都去学习这个总结后的结果。
这篇文章第一次看后的感觉说实话不是很惊艳,就是虽然相信它能涨点,但又感觉提升会很有限,而且为此要付出成倍的显存感觉很鸡肋,所以一直懒得动手做实验。直到最近看了NetAug这篇工作后突然感觉理论上通透了,OKDHP很像是NetAug的一个特殊子集,增加分支其实就是在对网络进行增强,小模型由于能力弱欠拟合,所以需要网络增强技术来辅助学习。
NetAug也是一篇很不错的工作,不过我觉得最重要的还是论证了网络增强和正则化在大模型和小模型上的意义,看完后虽然感觉很有道理但并不想实际去跑实验(因为感觉太花里胡哨了),所以提起劲儿把一直搁置的OKDHP跑了一下,这里贴一下我的实验结果吧。
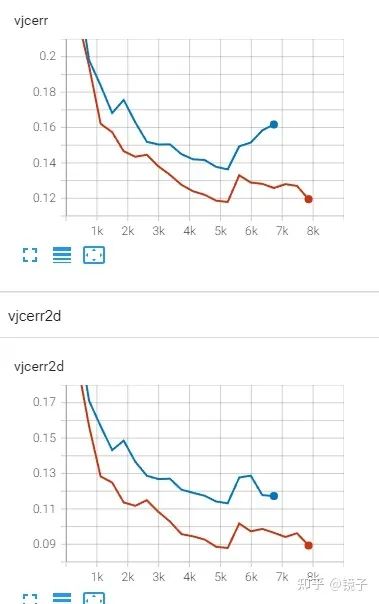
蓝色是一个轻量级模型,红色是把原模型复制了两份后得到了一个三分支的集成模型,三个分支分别计算坐标损失,以及求每个分支与集成得到的feature的损失,这里的损失我用的KL散度,求之前记得过softmax不然会出现Nan。我没有用作者提出的FAU,因为论文里的实验对比FAU聚合的特征只比Mean完的结果高0.3%,所以简单起见我直接对三个分支的feature相加求平均了。

验证集上的结果是单个初始模型所在分支的结果,而非集成后的指标,所以能看到网络增强+蒸馏确实是可以让小模型学得更好的。
作者的文章解读:
兰青:ICCV 2021 | 利用在线知识蒸馏进行高效2D人体姿态估计
https://zhuanlan.zhihu.com/p/399742423
在NetAug文中有论证蒸馏跟网络增强是正交关系,二者的收益是可以叠加的,OKDHP主要收益来源应该还是在于蒸馏,要更好地利用网络增强的收益,还应该在计算损失时,分别用几个头部来聚合不同分支的结果(以三分支为例的话,可以分组成1+2,1+3,2+3,1+2+3等形式,把不同分支的特征concat传入头部计算损失),感觉上这样应该还能再提升一波,等以后有空我会再验证一下。
损失函数篇
1. DSNT
anibali/dsntnn: PyTorch implementation of DSNT (github.com)
地址:https://github.com/anibali/dsntnn
比起主流的预测heatmap再使用argmax获得最大响应点的方法,作者提出用soft-argmax方法,直接从featuremap计算得到近似的最大响应点,从而模型可以直接对坐标值进行回归预测。
该方法的好处是:
可以极大节约显存,减少了很多代码量(省去了高斯热图的生成) 计算速度很快(省去argmax) 训练过程全部可微分 能取得还不错的效果
但是从近年的新论文实验对比,基于坐标回归的方法,先天缺少空间和上下文信息,这限制了方法的性能上限
补充:
DSNT这种regression-based method对移动端非常友好,在移动设备上为了提高fps往往特征图会压到14x14甚至7x7,这个尺度下heatmap根本用不了 另一个好处是可以比较方便地混合使用2d和3d训练数据,由于每一轴上的坐标都是通过将特征图求和压缩到一维再求期望得到的,因此可以很容易地用2d数据监督3d特征图(2d只比3d少算一次回归)
2. Bone Loss
这个技巧我是从Weakly-Supervised Mesh-Convolutional Hand Reconstruction in the Wild(CVPR2020 Oral)这篇文章里看到的,第一眼就感觉intuitively make sense,实验过后发现确实可以大大加速网络的收敛。
计算公式如下:
其中J_2D是模型预测的关键点,Y_2D是GroundTruth,该公式约束了每个关键点之间的空间关系,同时相当于约束了每根骨头的长度,直觉上就能感觉到能帮助学习到骨头长度关系,避免预测出一些诡异的不存在的姿态。
这是在我的数据集上的实验结果,从上向下分别是baseline,使用了AID,增加了bone loss后,L2 loss的变化
PS:该实验使用的是DSNT,使用了余弦退火学习率衰减

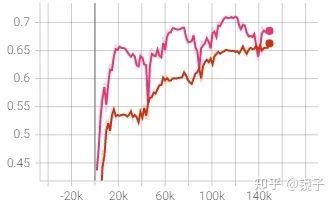
一开始我以为Bone Loss只能在2D坐标点上使用,这其实大大限制了它的使用场景,毕竟目前主流的方法还是基于Heatmap的。后来我做了实验对比后发现,在Heatmap方法上仍然是适用的,由下图对比可以看到,相同的模型和训练参数,仅仅增加了Bone Loss后的收敛速度,真的爽
下图用的metric是joint accuracy:
把我实现的版本传到了github,非常简单但是实用,分享给有需要的小伙伴,如果乐意的话可以给我一个star~
https://github.com/674106399/JointBoneLoss
有部分小伙伴对这个loss有一点疑问,heatmap的矩阵相减是没有物理意义的,所以我实现的版本里求的是两个矩阵的Frobenius范数,来比较矩阵相似度,同时兼容了heatmap和坐标值。
另外有小伙伴反映,在小数据上使用boneloss有掉点的情况,对应的调整是可以把原本的求每个点与所有点的距离,改成只求相连节点之间的距离,只需要把原代码中两层for循环改成直接给两个数组赋值即可。
3. Automatic Weighted Loss
地址:https://github.com/Mikoto10032/AutomaticWeightedLoss
由于模型有多个头部,进行关键点预测、手存在性预测、手势识别等任务(包括使用Bone Loss),因此可以使用Multi-task learning的方法来动态调节每个任务的权重,将不同的loss拉到统一尺度下,这样就容易统一,具体的办法就是利用同方差的不确定性,将不确定性作为噪声进行训练。
注意:这个方法并不总是能带来提升,在一些任务上反而会掉点,建议先在小数据上验证后再使用。
4. L1 Loss
在对坐标进行回归的时候,早些时候的文章大都直接用L2 loss,但随着近些年的发展,大量的实验表明了L1 loss在大部分情况下都会优于L2 loss。
从极大似然估计的角度来看,损失函数的选择实际上是基于对目标分布的假设,如果假设目标为高斯分布,那么就应该用L2 loss,如果假设为拉普拉斯分布,则应该使用L1 loss。具体的公式推导可以看Human Pose Regression with Residual Log-likelihood Estimation这篇paper。
5. RLE
这篇ICCV Oral的解读可以见我的专栏(但是没有上面L1跟拉普拉斯分布对应的公式推导,得去看原文)
镜子:论文笔记及思考:Human Pose Regression with Residual Log-likelihood Estimation(ICCV 2021 Oral)
https://zhuanlan.zhihu.com/p/395521994
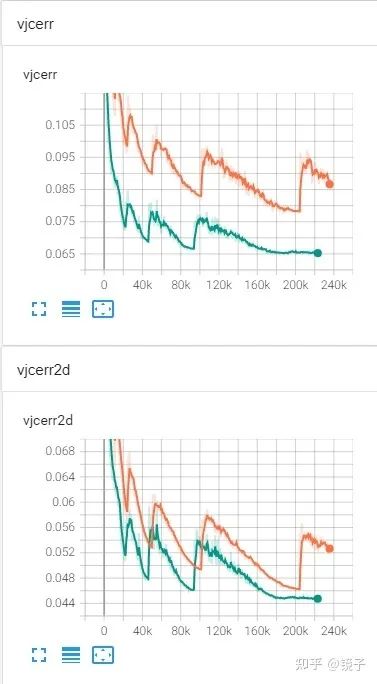
只能说非常厉害,强烈推荐使用,至于有多好用呢,我贴一个还没训练完的RLE跟Integral Pose的对比(RLE结尾阶段epoch的学习率我做了抹平,前面跟原实验保持一致,曲线还是足够说明问题了):
后处理篇
1. DARK
地址:https://github.com/ilovepose/DarkPose
这是COCO2020 亚军团队的论文。基于heatmap的方法往往存在一个分辨率变化的编码-解码过程,即原始图片分辨率较大,需要先缩小后才能输入模型进行预测,得到预测结果后还原到原始分辨率,再得到预测坐标。这个过程就会引入很多误差:
编码过程:GT在缩小后,渲染得到的高斯热图是有误差的 解码过程:预测的heatmap在还原到原始分辨率后,得到的坐标是有误差的
对于第二种误差,已经有人总结过一个标准过程,即将预测的坐标,由最大响应点向第二大响应点的方向,移动0.25个像素。只是这样的一个手工设计的偏移补救措施,就能带来极大的性能提升。
本文假设预测的heatmap是满足二维高斯分布的,因此基于heatmap的一阶导数和二阶导数来计算偏移方向,显然这比由最大响应点向第二大响应点的方向更有说服力。
但在验证中发现,预测的heatmap并不严格遵守高斯分布,会出现多峰情况,因此增加了一个步骤,对预测的heatmap进行平滑处理,使结果符合假设。这一步是为上面提出的解码方法服务的,用于保证解码效果的准确性。
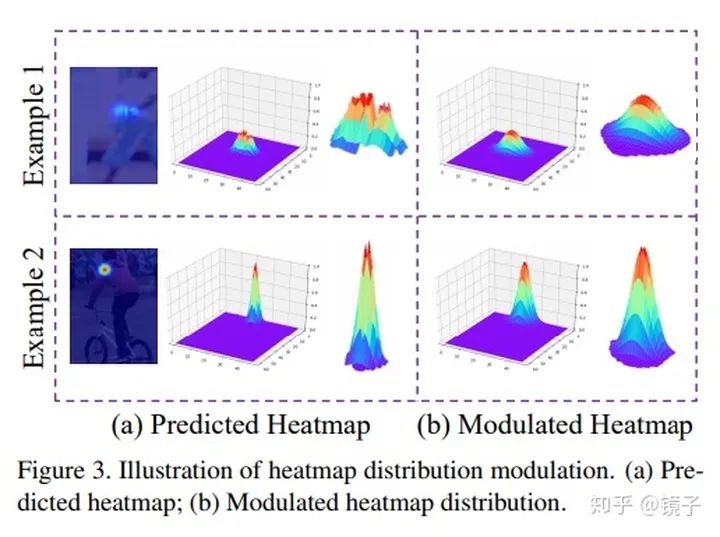

一图胜千言,该方法对DSNT几乎是吊打。在目前SOTA方法上也可以即插即用地产生巨大提升。
2. 指数滑动平均滤波
在实际的部署应用中,轻量级模型的输出不可避免地会出现抖动,一个比较简单的处理方式是添加滑动滤波,用轻微的延迟来换取输出的稳定,具体原理和代码可以看我这篇文章:
镜子:用指数滑动平均滤波来稳定轻量模型的输出
https://zhuanlan.zhihu.com/p/433571477
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
