
2020 神经网络架构搜索(NAS)最新技术综述

极市导读
近年来有关NAS的优秀的工作层出不穷,分别从不同的角度来提升NAS算法。为了让初学者更好的进行NAS相关的研究,本文从其产生的背景到未来的发展方向,全面而系统的综述了NAS的挑战和解决方案。>>加入极市CV技术交流群,走在计算机视觉的最前沿
【内容速览】你可能感兴趣的内容:
NAS是什么?由什么组成?常用算法是什么?
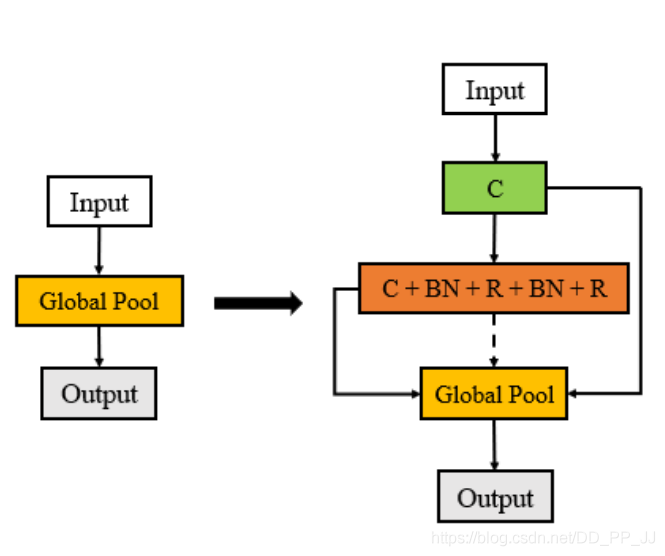
Add操作要比concate操作更加有效。
宽而浅的单元(采用channel个数多,但层数不多)在训练过程中更容易收敛,但是缺点是泛化性能很差。
能根据网络前几个epoch的表现就确定这个网络是否能够取得更高性能的预测器(性能预测)。
根据候选网络结构的表示就可以预测这个模型未来的表现(性能预测)。
分类的backbone和其他任务比如检测是存在一定gap的,最好的方式并不一定是微调,而可能是改变网络架构。
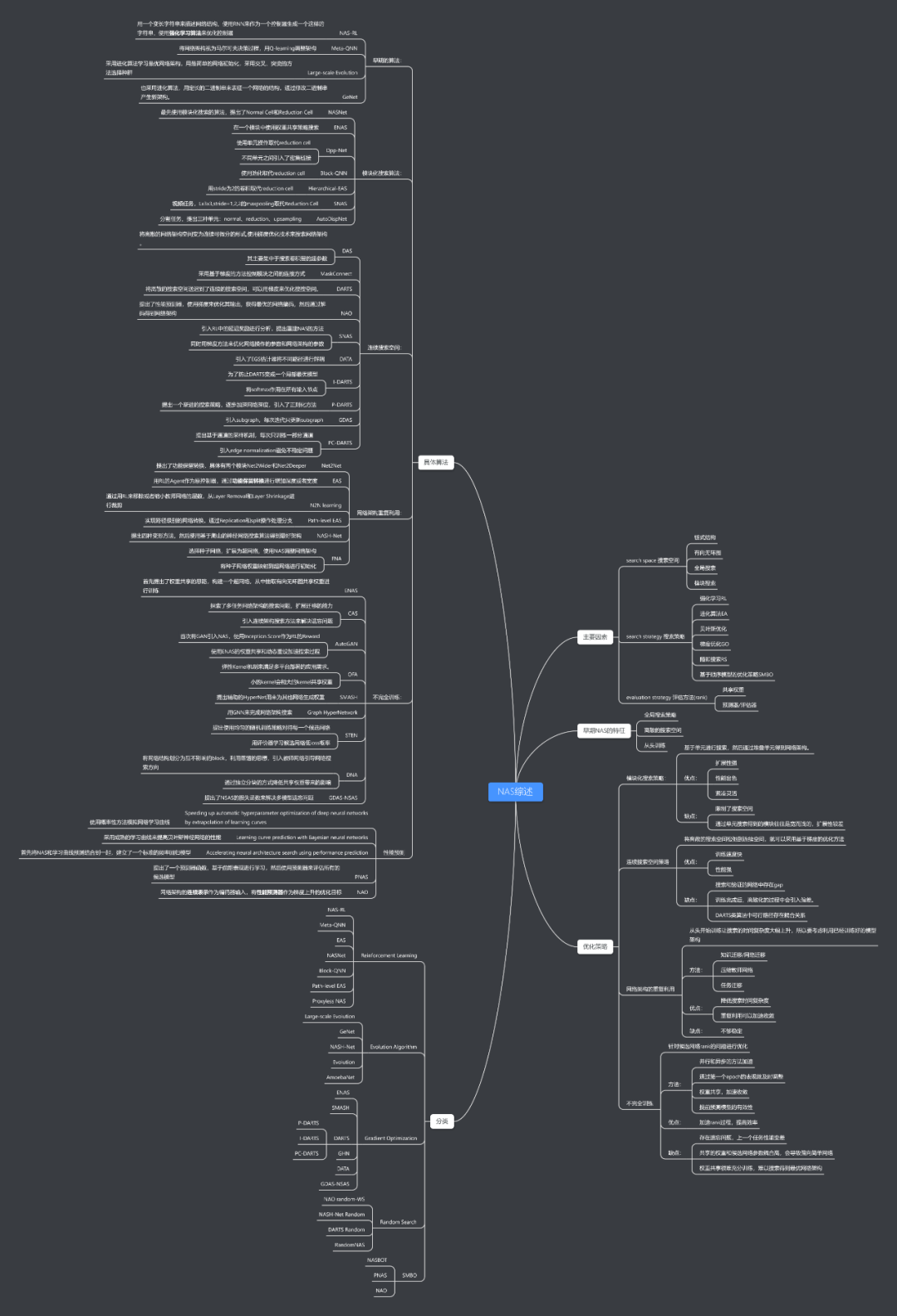
1. 背景 2. NAS介绍 3. 早期NAS的特征 3.1 全局搜索 3.2 从头搜索 4. 优化策略 4.1 模块搜索策略 4.2 连续的搜索空间 4.3 网络架构重复利用 4.4 不完全训练 5. 性能对比 6. 未来的方向 7. 结语 8. 参考文献
1. 背景
早期NAS算法的特点。 总结早期NAS算法中存在的问题。 给出随后的NAS算法对以上问题提出的解决方案。 对以上算法继续分析、对比、总结。 给出NAS未来可能的发展方向。
2. NAS介绍
identity 卷积层(3x3、5x5、7x7) 深度可分离卷积 空洞卷积 组卷积 池化层 Global Average Pooling 其他
search space 如何定义搜索空间 search strategy 搜索的策略 evaluation strategy 评估的策略
3. 早期NAS的特征
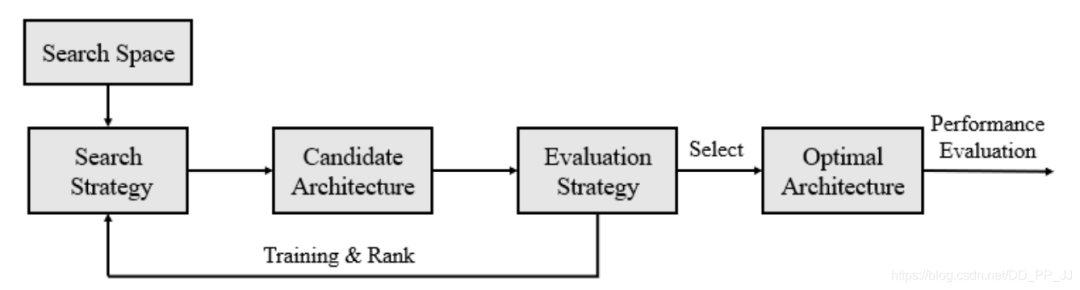
找一些预定义的操作集合(eg 卷积、池化等)这些集合构成了Search Space搜索空间。 采用一定的搜索策略来获取大量的候选网络结构。 在训练集训练这些网络,并且在验证集测试得到这些候选网络的准确率。 这些候选网络的准确率会对搜索策略进行反馈,从而可以调整搜索策略来获得新一轮的候选网络。重复这个过程。 当终止条件达到(eg:准确率达到某个阈值),搜索就会停下来,这样就可以找到准确率最高对应的网络架构。 在测试集上测试最好的网络架构的准确率。
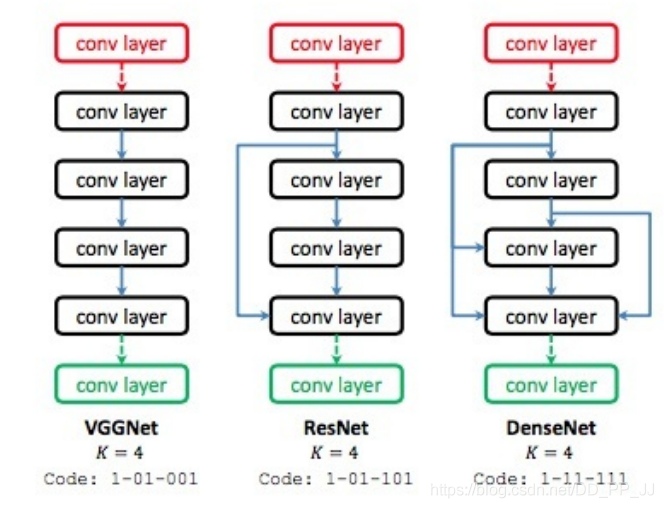
全局搜索策略:早期NAS采用的策略是搜索整个网络的全局,这就意味着NAS需要在非常大的搜索空间中搜索出一个最优的网络结构。搜索空间越大,计算的代价也就越大。 离散的搜索空间:早期NAS的搜索空间都是离散的,不管是用变长字符串也好,还是用二进制串来表示,他们的搜索空间都是离散的,如果无法连续,那就意味着无法计算梯度,也无法利用梯度策略来调整网络模型架构。 从头开始搜索:每个模型都是从头训练的,这样将无法充分利用现存的网络模型的结构和已经训练得到的参数。
3.1 全局搜索
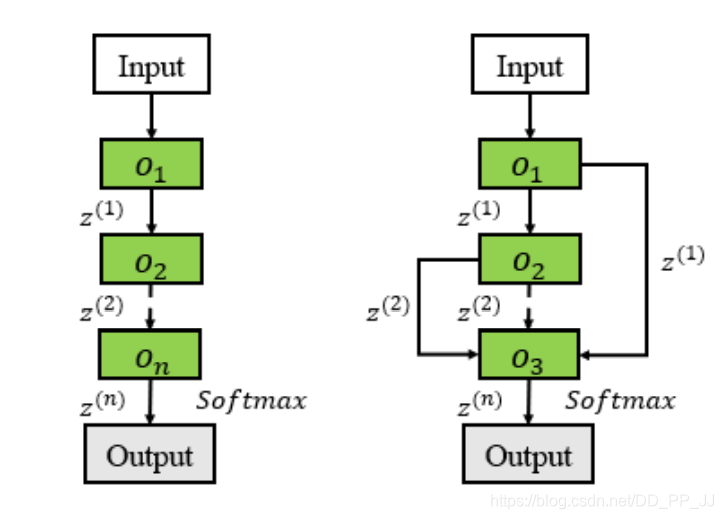
“注记:跳转连接往往可以采用多种方式进行特征融合,常见的有add, concate等。作者在文中提到了实验证明,add操作要比concate操作更加有效(原文:the sum operation is better than the merge operation)所以在NAS中,通常采用Add的方法进行特征融合操作。
3.2 从头搜索
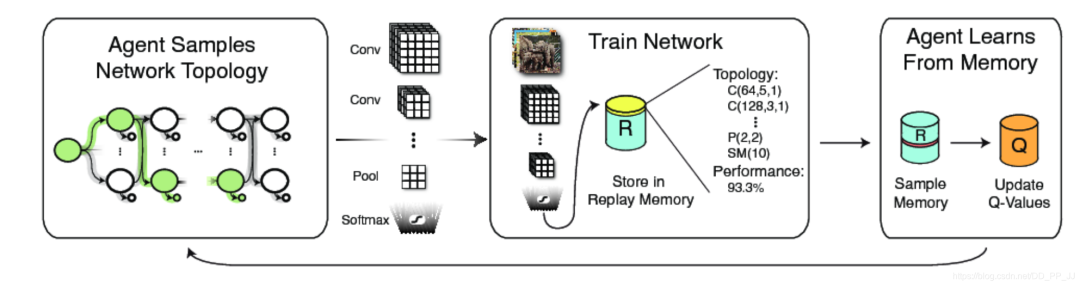
4. 优化策略
4.1 模块搜索策略
Normal Cell也就是正常模块,用于提取特征,但是这个单元不能改变特征图的空间分辨率。 Reduction Cell和池化层类似,用于减少特征图的空间分辨率。
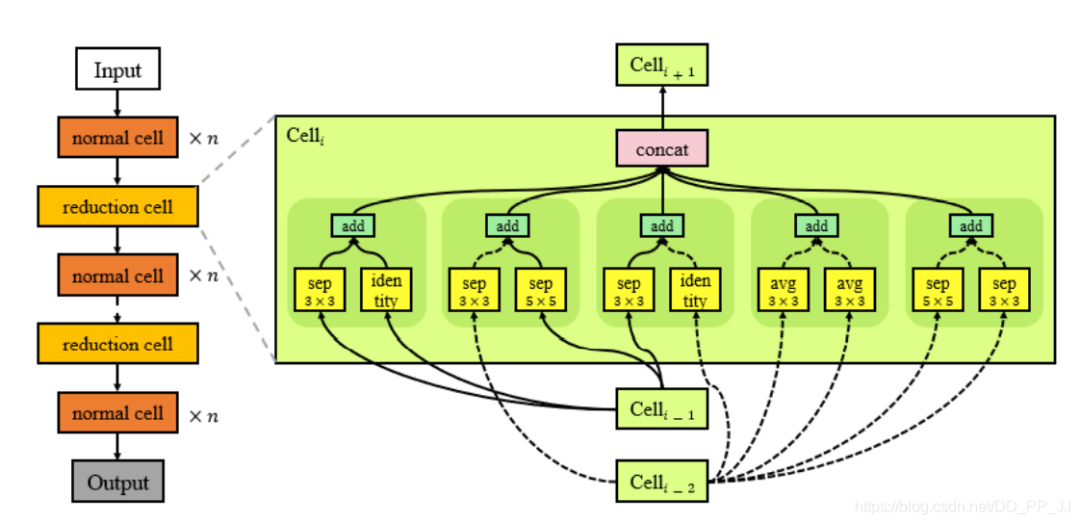
使用单元操作来取代reduction cell(reduction cell往往比较简单,没有必要搜索,采用下采样的单元操作即可,如下图Dpp-Net的结构)下图Dpp-Net中采用了密集连接。
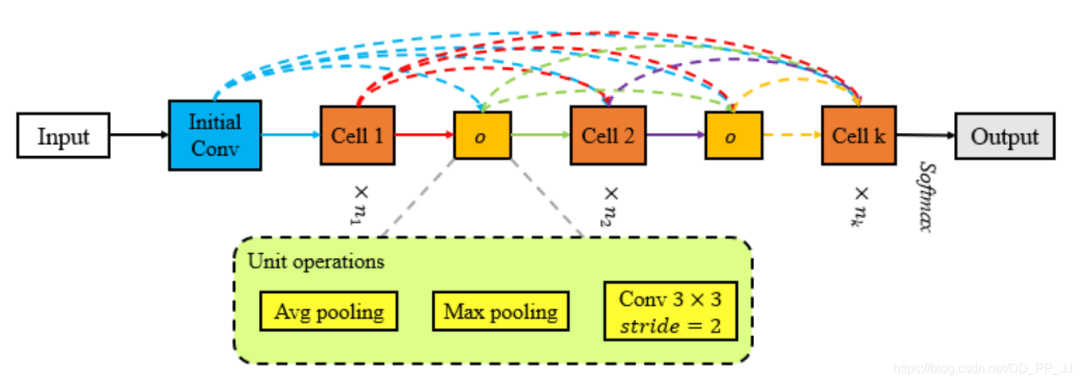
Block-QNN中直接采用池化操作来取代Reduction cell Hierarchical-EAS中使用了3x3的kernel size, 以2为stride的卷积来替代Reduction Cell。 Dpp-Net采用平均池化操作取代Reduction Cell。同时采取了Dense连接+考虑了多目标优化问题。 在视频任务:SNAS使用了Lx3x3,stride=1,2,2的maxpooling取代Reduction Cell。 在分割任务:AutoDispNet提出了一个自动化的架构搜索技术来优化大规模U-Net类似的encoder-decoder的架构。所以需要搜索三种:normal、reduction、upsampling。
“注记:通过研究这些搜索得到的单元模块,可以得到以下他们的共性:由于现存的连接模式,宽而浅的单元(采用channel个数多,但层数不多)在训练过程中更容易收敛,并且更容易搜索,但是缺点是泛化性能很差。
4.2 连续的搜索空间
中间节点代表潜在的特征表达,并且和每个之前的节点都通过一个有向边操作。对一个离散的空间来说,每个中继节点可以这样表达:
在DARTS中,通过一个类似softmax来松弛所有可能的操作,这样就将离散搜索空间转化为连续的搜索空间问题。
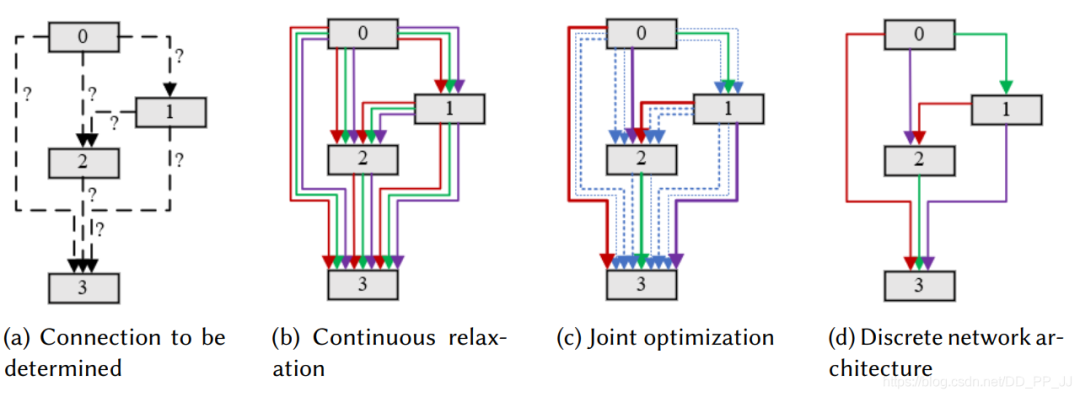
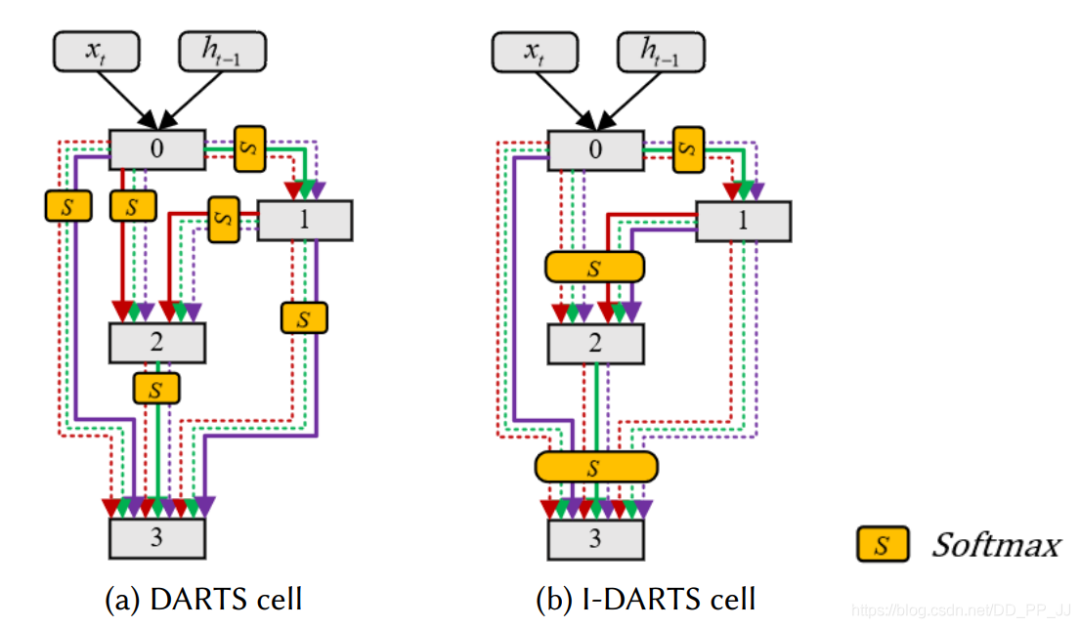
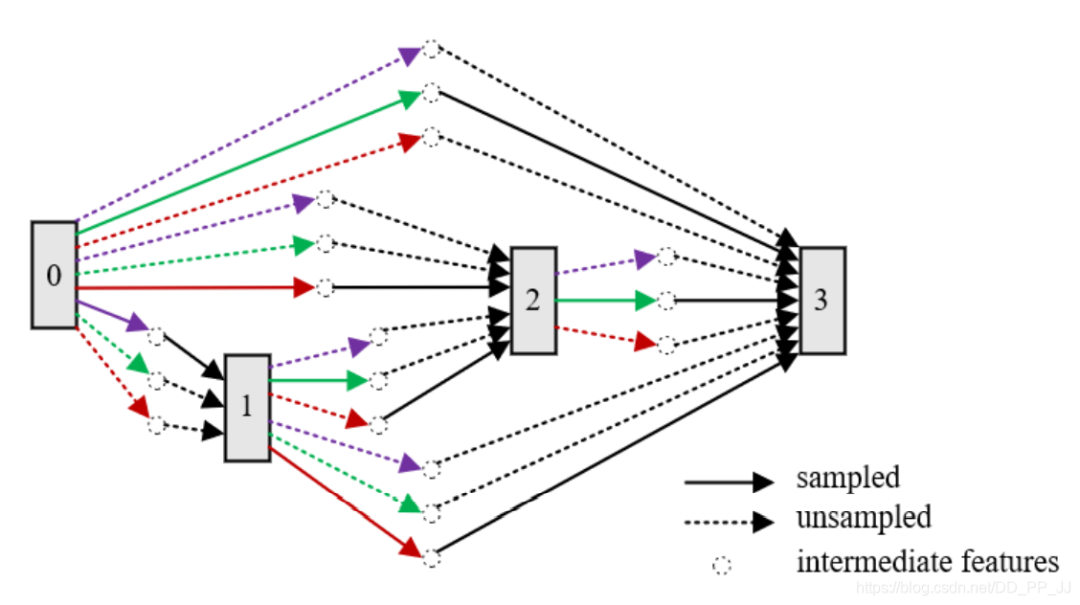
4.3 网络架构重复利用
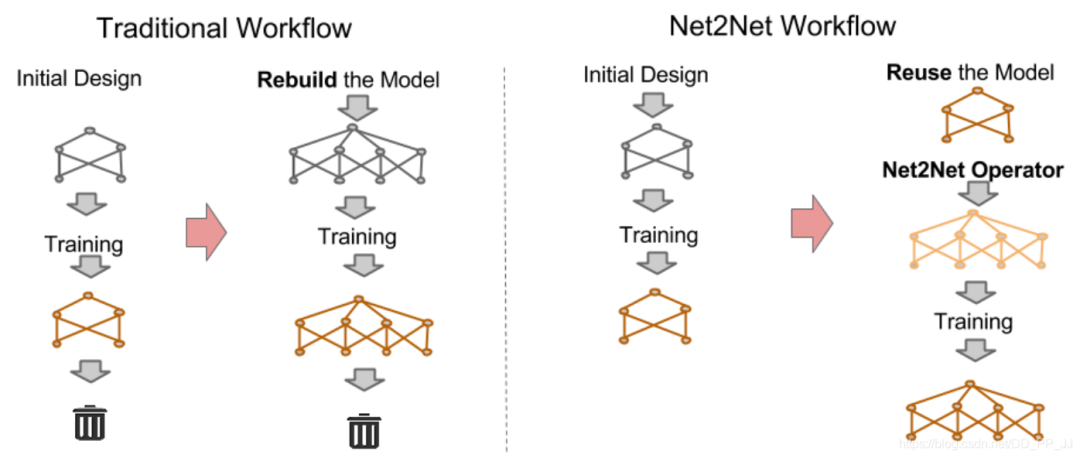
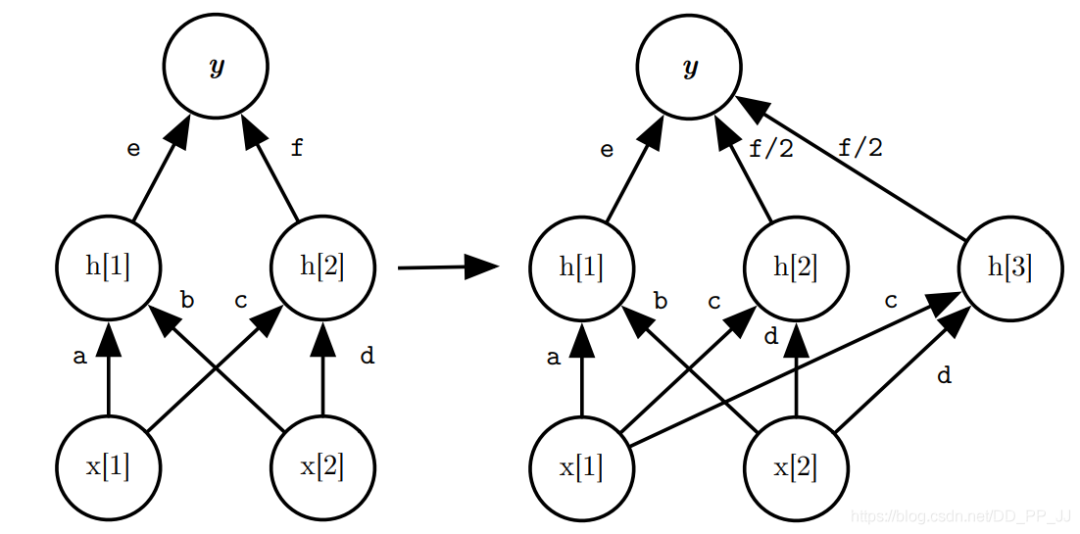

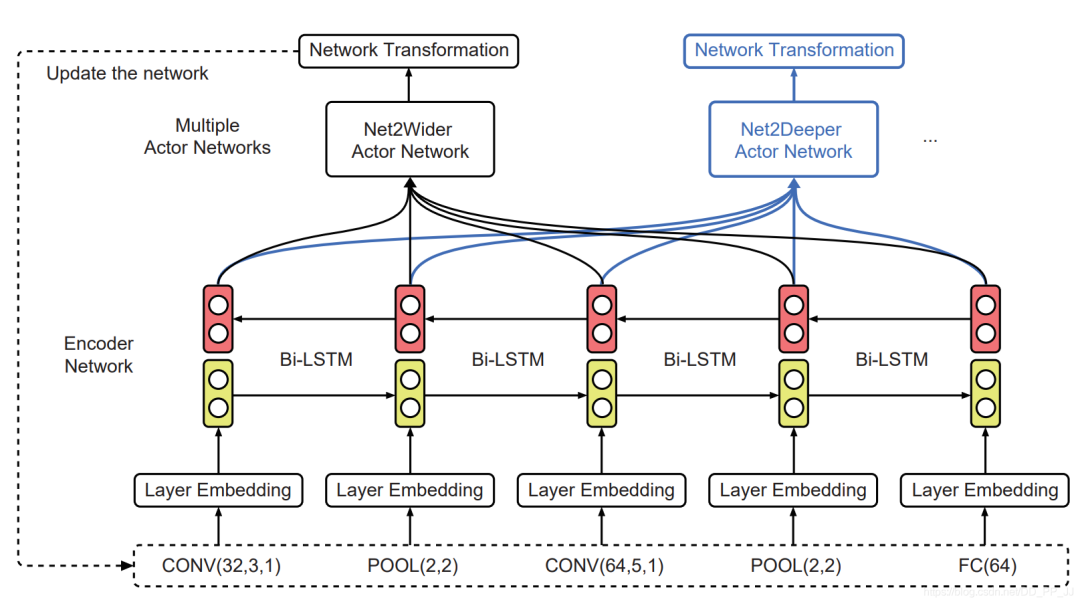
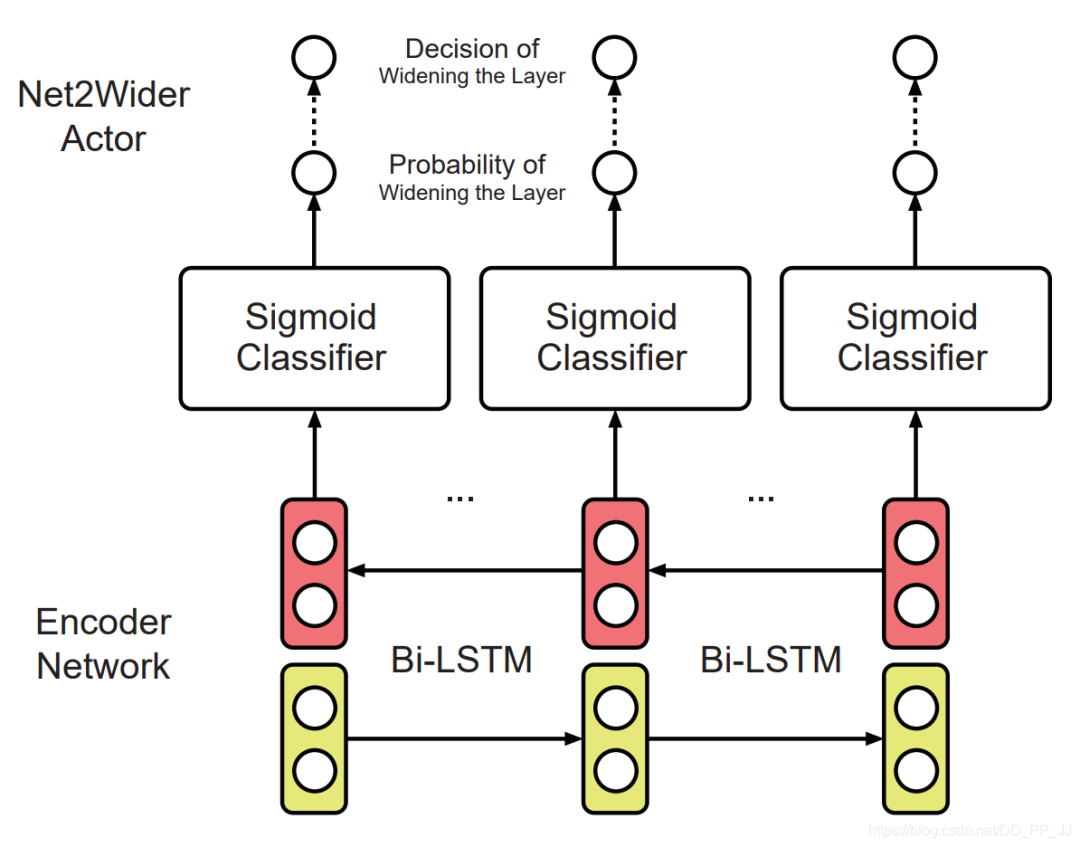
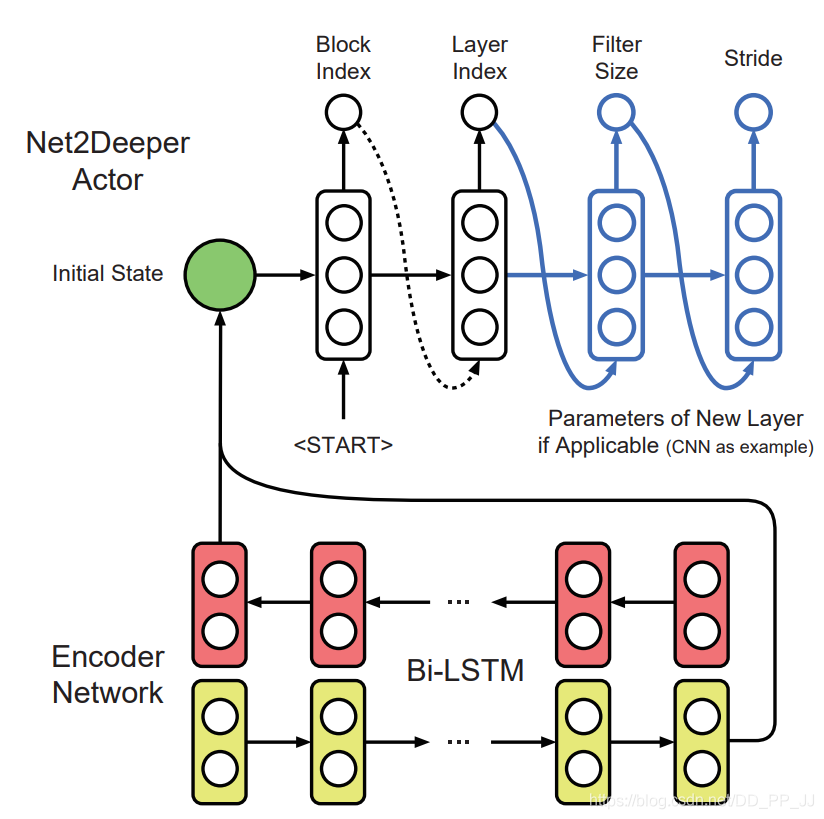
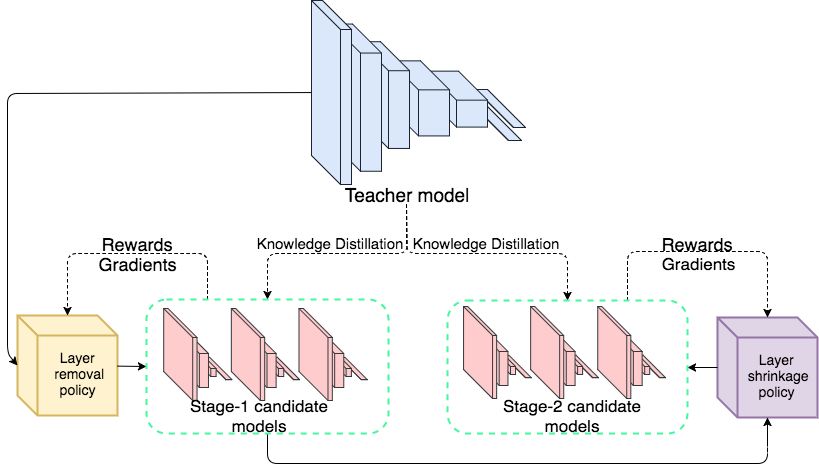
首先使用layer removal操作 然后使用layer shrinkage操作 使用强化学习来探索搜索空间 使用知识蒸馏的方法训练每个生成得到的网络架构。 最终得到一个局部最优的学生网络。
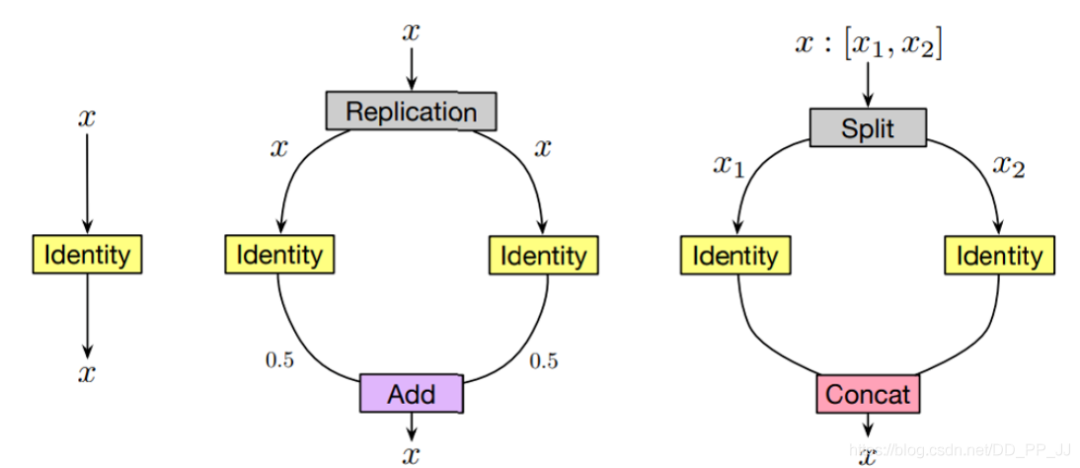
Replication就是将输入x复制两份,分别操作以后将得到的结果除以2再相加得到输出。 Split就是将x按照维度切成两份,分别操作以后,将得到的结果concate到一起。
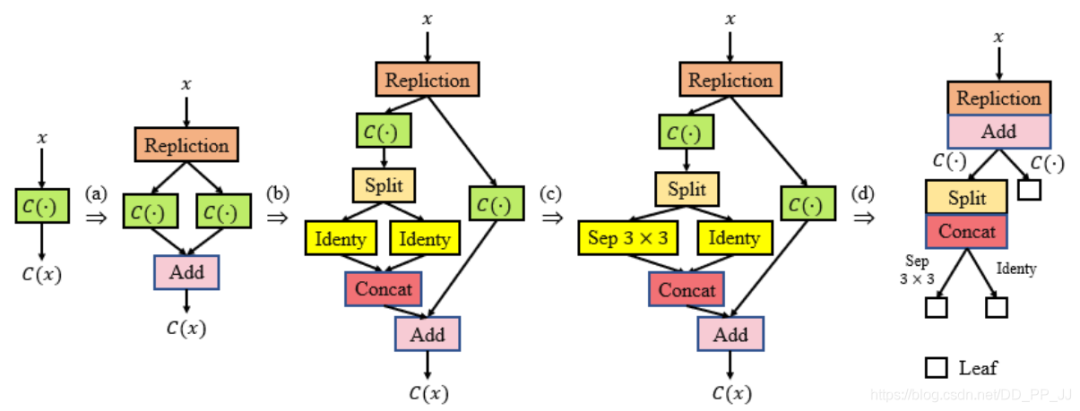
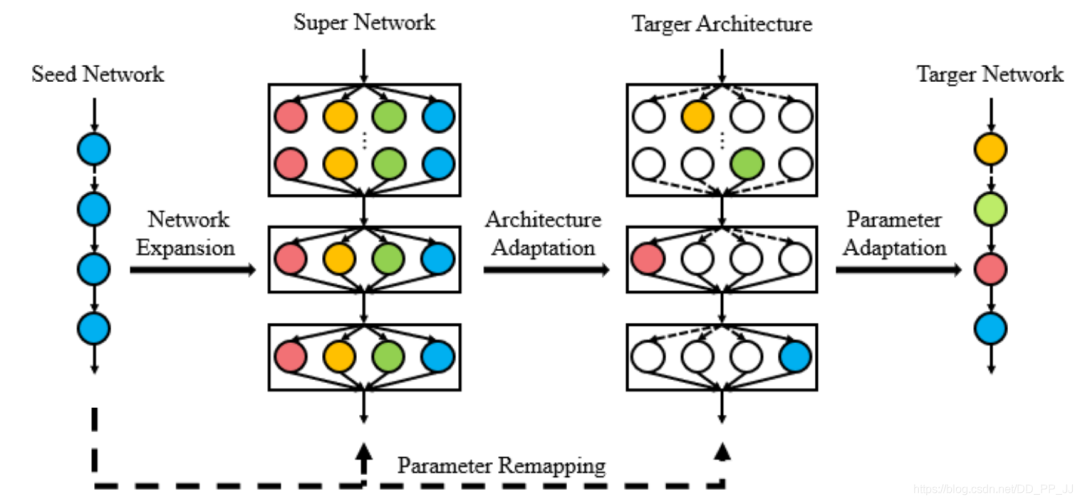
“ps: 分类backbone和其他任务是有一定gap的,FNA认为通过微调神经网络带来的收益不如调整网络结构带来的收益)
4.4 不完全训练
NAS-RL采用了并行和异步的方法来加速候选网络的训练 MetaQNN在第一个epoch训练完成以后就使用预测器来决定是否需要减少learning rate并重新训练。 Large-scale Evolution方法让突变的子网络尽可能继承父代网络,对于突变的结构变化较大的子网络来说,就很难继承父代的参数,就需要强制重新训练。
4.4.1 权重共享
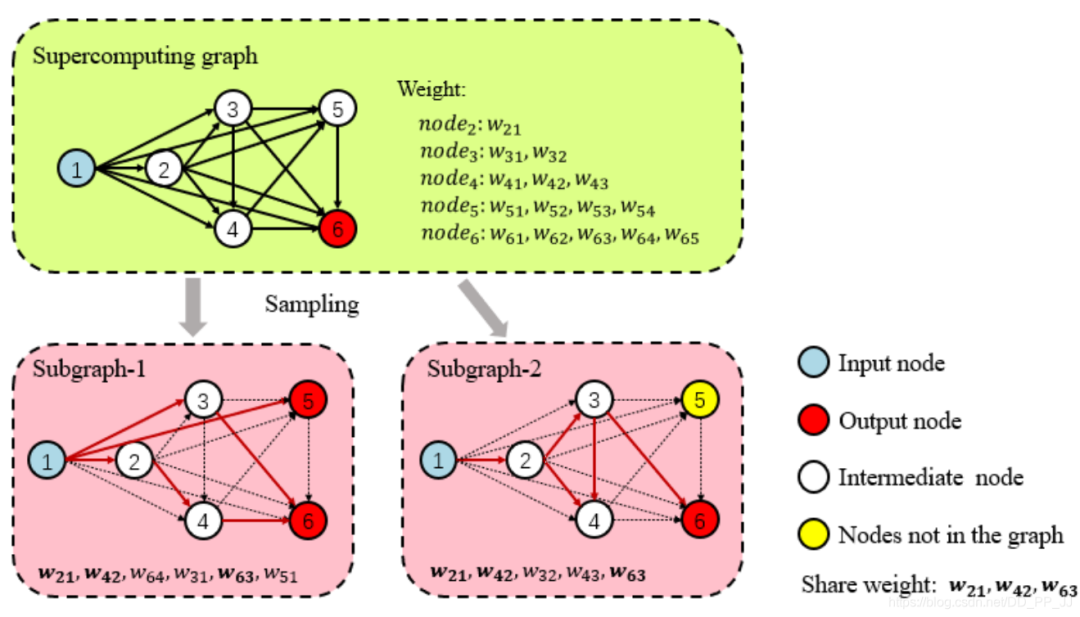
4.4.2 训练至收敛
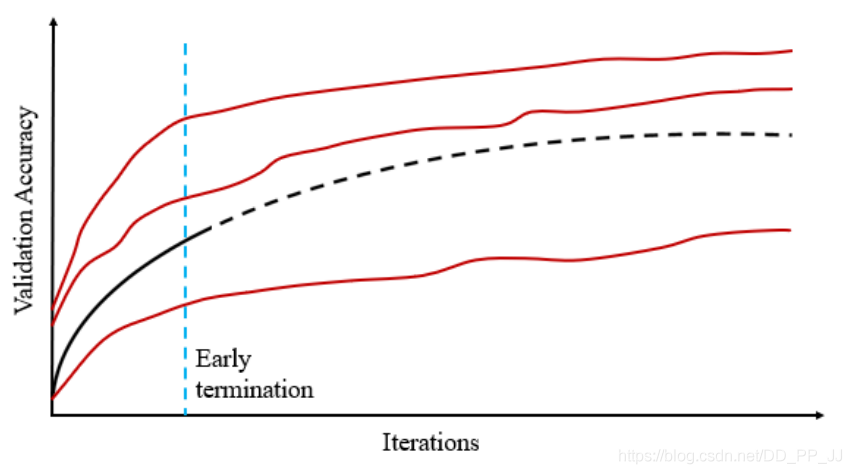
5. 性能对比
reinforcement learning(RL) evolutionary algorithm(EA) gradient optimization(GO) random search(RS) sequential model-based optimization(SMBO)
缺少baseline(通常随机搜索策略会被认为是一个强有力的baseline) 预处理、超参数、搜索空间、trick等不尽相同
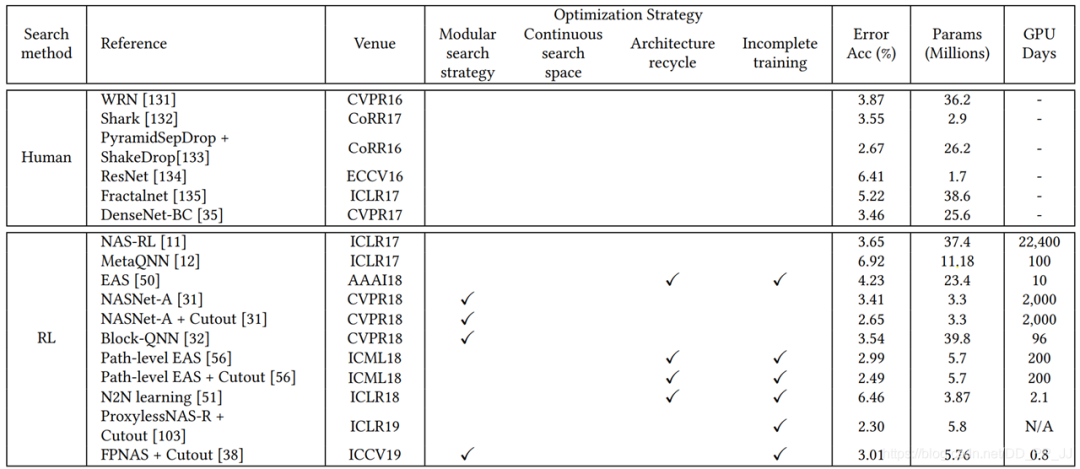
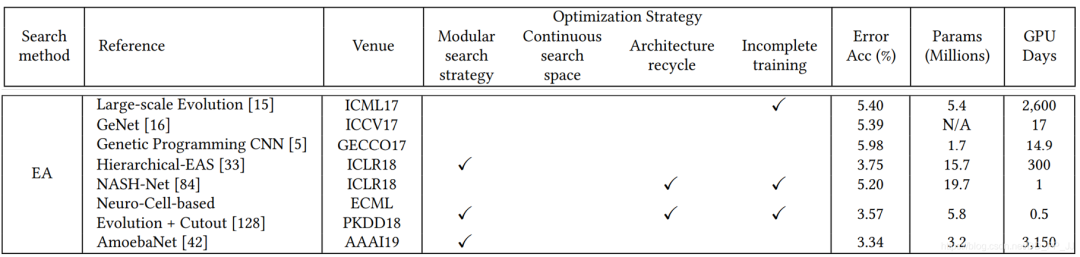
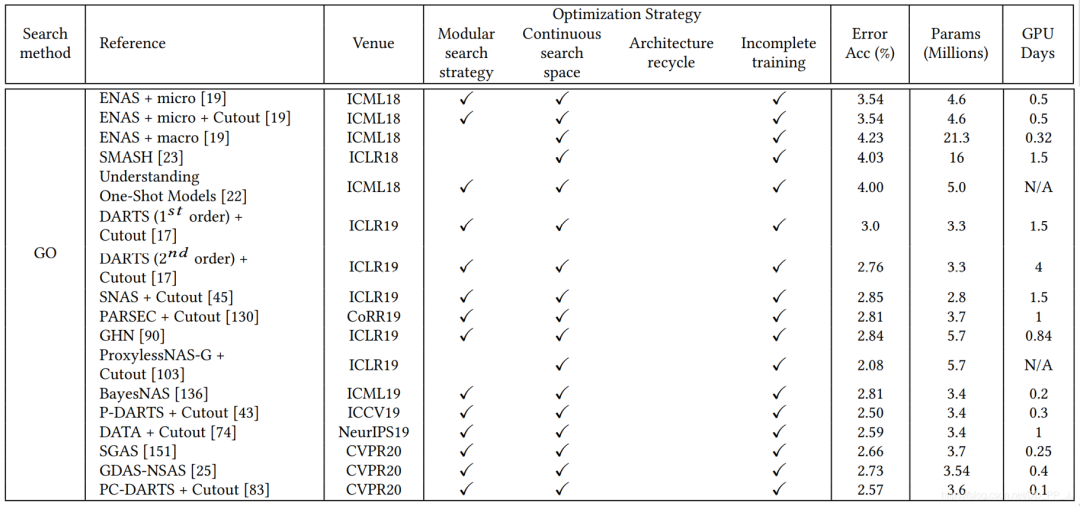
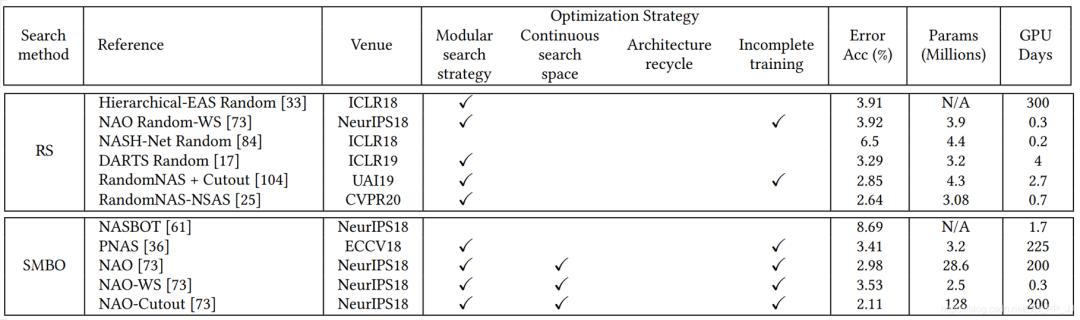
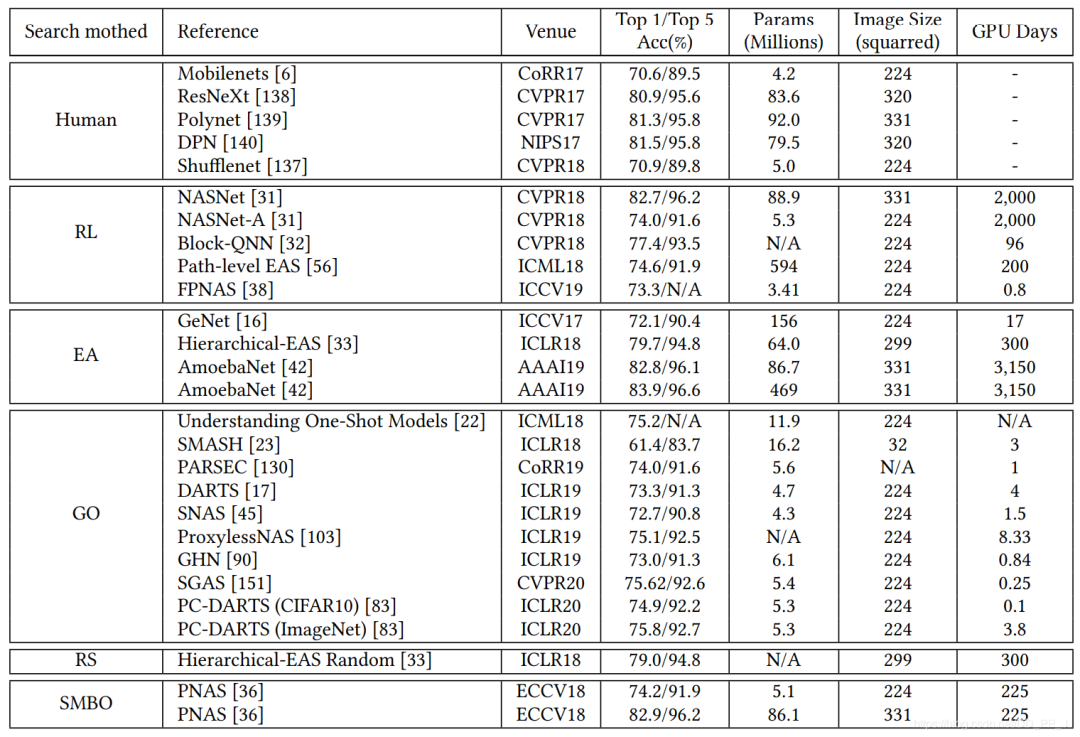
模块化搜索策略应用非常广泛,因为可以减低搜索空间的复杂度, 但是并没有证据表明模块化搜索就一定要比全局搜索最终性能要好。 不完全训练策略也是用很多,让候选网络rank的过程变得非常有效率。 基于梯度的优化方法(如DARTS)与其他策略相比,可以减少搜索的代价,有很多工作都是基于DARTS进行研究的。 随机搜索策略也达成了非常有竞争力的表现,但是相对而言这方面工作比较少。 迁移学习的技术在这里应用比较广泛,先在小数据集进行搜索(被称为代理任务),然后在大的数据集上迁移。 ProxyLessNas也研究了如何直接在大型数据集上直接进行搜索的方法。
6. 未来的方向
7. 结语
8. 参考文献
推荐阅读

评论