
Ansor论文阅读笔记&&论文翻译
这篇文章介绍了Auto-Scheduler的一种方法Ansor,这种方法已经被继承到TVM中和AutoTVM一起来自动生成高性能的张量化程序。
论文链接:https://arxiv.org/abs/2006.06762 OSDI 2020 前置知识: 需要了解scheduler,推荐一篇文章:https://zhuanlan.zhihu.com/p/94846767 。 在Ansor论文中主要使用了parallel,cache_read,reorder,unroll,vectorize这些scheduler来描述整个算法,但在Ansor的TVM开源代码实现中不仅限于这些scheduler,在看Ansor论文之前建议先了解一下。 在AutoTVM和Ansor之前,要生成高性能的张量化程序需要手动指定模板,这些模板不仅需要指定high-level的scheduler,还需要包含low-level的计算逻辑,因为CPU/GPU/ASIC等等芯片底层对张量的计算方式不同。推荐陈天奇的一个对TVM的报告:https://www.bilibili.com/video/BV1vW411R7Zb?from=search&seid=5300327607655608948 。 个人理解 Ansor具体是怎么做到自动生成张量化程序的呢?首先是要做子图切分,子图切分的规则和TVM的算符融合一致,对于每一个子图主要是通过草图和注释来生成对应的程序。 草图,就是基于上面介绍的那些scheduler和一些推导规则来做的,推导规则是什么?比如对于卷积和矩阵乘法这种计算密集型算子,在CPU上Ansor就给它定义了一个tile规则叫“SSRSRS”,对于矩阵乘法来说"SSRSRS" tile规则就是将原始的三重for循环扩展为。这就是论文中Figure5里面的第一个示例。除了这个tile规则还有还有数据复用算子和简单算子融合,无数据复用的简单算子inline优化,数据复用算子其输入需要做计算分窗和输入的 Cache Read,Cache Write,rfactor等等多种规则。由于GPU和CPU架构不同,所以定义的规则也不完全相同,比如矩阵乘法的多级tiling结构就会从“SSRSRS”改为“SSSRRSRS”以匹配 GPU 的架构。tiling中的前三个空间循环分别绑定到 BlockIdx、虚拟线程(用于减少 bank 冲突)和 ThreadIdx。另外用户也可以自定义规则。 注释,就是在草图的基础上,随机确定GPU thread bind,for 循环的 unroll、vectorize、parallize,Split 的 factor等等生成完成的代码。(并行外循环,矢量化和展开内循环,这个就对应了GEMM优化中的优化的关键思路)虽然生成了完整的代码,但这个代码的性能是由 Evolutionary Search 来保证的。另外,用户也可以自定义注释。 然后如何更有效的遍历搜索空间以及剪枝掉一些无用的搜索空间可以看下原论文的相关介绍。 优缺点 由于Ansor具有超大的搜索空间,在一些主流DNN模型和硬件上都能搜索到性能较好的程序。GPU上可以超越TensorRT,CPU上可以超越TensorflowLite,AutoTVM等。 但Ansor的搜索时间相比于TVM的提升并不是非常大,要将ResNet50搜索到超越TensorRT的性能需要多个小时。 可优化之处思考 搜索时间如何减少? 子图划分的粒度比较细,子图太多会不会使得优化算法陷入局部最优? NC4HW4,Winograd等是否可以添加到推导规则? 论文翻译 为了更好的理解Ansor,我翻译了一下论文,欢迎大家勘误。
Ansor: Generating High-Performance Tensor Programs for Deep Learning
摘要
高性能的张量化程序对于保证深度神经网络的高效执行是至关重要的。然而,在各种硬件平台上为不同的算子都获得高效的张量化程序是一件充满挑战的事。目前深度学习系统依赖硬件厂商提供的内核库或者各种搜索策略来获得高性能的张量化程序。这些方法要么需要大量的工程工作来开发特定于平台的优化代码,要么由于搜索空间受限和无效的探索策略而无法找到高性能的程序。
我们提出了Ansor,一个用于深度学习应用的张量化程序生成框架。与现有的搜索策略相比,Ansor通过从搜索空间的分层表示中采样程序来探索更多的优化组合。然后Ansor使用进化搜索和一个可学习的代价模型对采样程序进行微调,以确定最佳程序。Ansor可以找到现有SOTA方法的搜索空间之外的高性能程序。此外,Ansor利用scheduler同时优化深度神经网络中的多个子图。实验表明,相对于Intel CPU,ARM CPU,NVIDIA GPU,Ansor分别将神经网络的执行性能提高了3.8倍,2.6倍,和1.7倍。
1. 介绍
深度神经网络(DNN)的低延迟推理在自动驾驶[14],增强现实[3],语言翻译[15]和其它的AI应用中发挥着关键作用。DNN可以表示为有向无环图(DAG),其中节点表示算子(例如Conv,Matmul),有向边表示算子之间的依赖关系。现有的深度学习框架(例如TensorFlow,Pytorch,MxNet)将DNN中的算子基于硬件厂商提供的一些高性能内核库(例如,cuDNN,MKL-DNN)来实现以获得高性能。然而,这些内核库需要大量的工程工作来为每个硬件平台和每种算子进行手工调整。为每个目标加速器生成高效的算子实现所需的大量手动工作限制了新算子[7]和专用加速的开发和创新[35]。
鉴于DNN性能的重要性,研究人员和行业从业者已转向基于搜索的编译技术[2, 11, 32, 49, 59]来自动生成张量程序,即张量算子的low-level的实现。对于一个算子或者多个算子组成的子图,用户使用high-level的声明性语言定义计算,然后编译器针对不同的硬件平台搜索定制的程序。
为了找到高性能的张量化程序,基于搜索的方法有必要探索足够大的搜索空间来覆盖所有的张量化程序优化策略。然后现有的方法无法捕获需要有效的优化组合,因为它们依赖预定义的手写模板(例如TVM[12],FlexTensor[59])或者通过评估不完整的程序(例如Halide auto-scheduler)来进行调整,这会组阻止它们覆盖全面的搜索空间。它们用来构建搜索空间的规则也是有限的。
在本文中,我们探索了一种用于生成高性能张量化程序的新搜索策略。它可以自动生成一个大的搜索空间,全面覆盖各种优化策略。因此,它能够找到现有方法遗漏的高性能程序。
实现这一目标面临多种调整。首先,它需要自动构建一个大的搜索空间,以针对给定的计算定义覆盖尽可能多的张量化程序。其次,我们需要更有效地搜索,而无需在大型的搜索空间中比较不完整的程序,这些程序可能比现有的模板所能覆盖的范围大几个数量级。最后,在优化具有许多子图的整个 DNN 时,我们应该识别和优先考虑对端到端性能至关重要的子图。
为此,我们设计并实现了Ansor,这是一个自动生成张量化程序的框架。Ansor利用分层表示来覆盖大的搜索空间。这种表示将high-level的结构和low-level的细节解耦,从而实现high-level结构的灵活枚举和low-level细节的有效采样。空间是在给定了计算定义后自动构建的,然后Ansor从搜索空间中采样完整的程序,并使用进化搜索和一个可学习的代价模型对采样程序进行微调。为了优化具有多个子图的 DNN 的性能,Ansor 动态优先的处理 DNN 中更有可能提高端到端性能的子图。
我们在标准的深度学习Benchmark以及基于搜索调优的框架给出的Benchmark上进行了评估。实验结果表明,Ansor将DNN 在 Intel CPU、ARM CPU 和 NVIDIA GPU 上的执行性能分别提高了3.8 倍、2.6倍和1.7倍。对于大多数计算定义,Ansor找到的最佳程序在现有基于搜索的方法的搜索空间之外。结果还表明,与现有的基于搜索的方法相比,Ansor 搜索更有效,在更短的时间内生成了更高性能的程序,尽管它的搜索空间更大。Ansor可以在降低一个数量级的时间内获得目前SOTA框架(指的应该是类似TVM的可以自动调优的框架)相当的性能。此外Ansor可以自动扩展到新运算符,只需要这个运算符的数学定义,无需手动编写模板。
总结一下,这篇论文做出了以下贡献:
一种为计算图生成张量程序的大型空间分层搜索机制。 一种基于可学习的代价模型的进化策略,用来微调张量化程序的性能。 一种基于梯度下降的调度算法,在优化 DNN 的端到端性能时对重要子图进行优先排序。 Ansor 系统的实现和综合评估表明,上述技术在各种 DNN 和硬件平台上都优于最先进的系统。
2. 背景
深度学习生态系统正在拥抱快速增长的硬件平台多样性,包括CPU,GPU,FPGA和ASICs。为了在这些平台上部署DNN,DNN使用的算子需要高性能的张量化程序。所需的算子通常包含标准算子(例如matmul,conv2d)和机器学习研究人员发明的新算子(例如capsule conv2d[23],dilated conv2d[57])的混合。
为了在各种硬件平台上部署这些算子时都保持良好的性能已经引入了多种编译器技术(例如TVM[11],Halied[41],Tensor Comprehensions[49])。用户使用high-level的声明式语言以类似于数学表示式的形式定义计算,编译器根据定义生成优化的张量程序。Figure1展示了TVM 张量表达式语言中矩阵乘法的定义,用户主要需要定义张量的形状以及如何计算输出张量中的每个元素。

然而,从high-level定义中自动生成高性能张量程序是极其困难的。根据目标平台的架构,编译器需要在包含各种优化方式(例如tile,向量化,并行等等)的极其复杂和庞大的空间中进行搜索。寻找高性能程序需要搜索策略覆盖一个全面的空间并有效的搜索,我们在本节中描述了两种最新且有效的方法,并在第8节中描述了其他相关工作。
Template-guided search 在模板引导的搜索中,搜索空间由手工模板指定。如Figure2 a所示,编译器(例如 TVM)要求用户手动编写用于计算定义的模板。该模板使用一些可调参数(例如,tile size和unrolling factor)定义了张量化程序的结构。然后编译器为特定的输入形状设置和特定的硬件目标搜索这些参数的最佳值。这种方法在常见的深度学习算子上取得了良好的性能。然而,开发模板需要大量的工程努力。例如,TVM代码库中包含手工模板的代码已经超过了15000行。随着新算子和新硬件平台的出现,这个数字还在继续增长。此外,开发高质量的模板需要张量运算符和硬件方面的专业知识。开发高质量的模板也需要大量的研究工作 [32, 55, 59]。尽管模板设计很复杂,但手动指定的模板也仅能涵盖有限的程序结构,因为手动枚举所有算子的所有优化选择是令人望而却步的。这种方法通常需要为每个运算符定义一个模板。Flex-Tensor [59] 提出了一个覆盖多个算子的通用模板,但它的模板仍然是为单算子设计的,它没有包括涉及多个算子的优化(例如,算子融合)。优化具有多个算子的计算图的搜索空间应该包含不同的组合这些算子的方式。基于模板的方法无法实现这一点,因为它无法在搜索过程中分解固定的模板并重新组合它们。
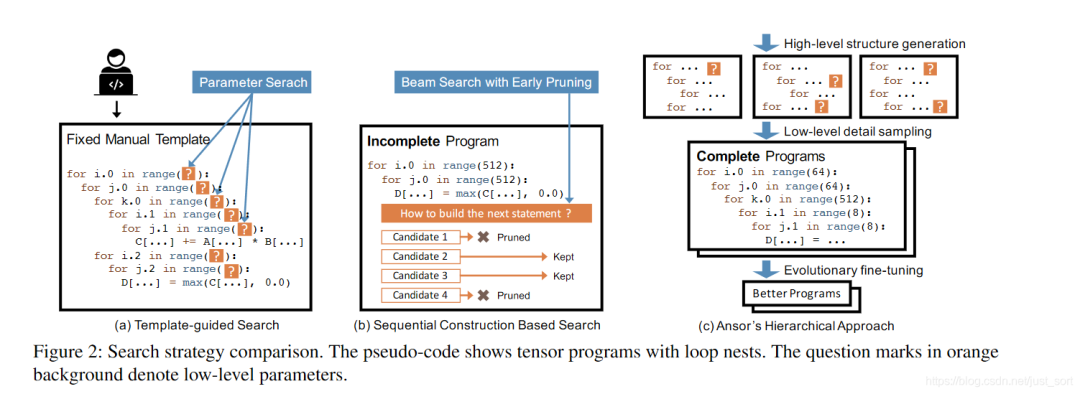
Sequential construction based search. 这种方法通过将程序构造分解为固定的决策序列来定义搜索空间。然后编译器使用诸如波束搜索 [34] 之类的算法来搜索好的决策(例如,Halide auto-scheduler [2])。在这种方法中,编译器通过依次unfold计算图中的所有节点来构造张量化程序。对于每个节点,编译器就如何将其转换为low-level张量化程序做出一些决策(即决策 computation location、storage location、tile size等)。当所有节点都unfold后,就构建了一个完整的张量化程序。这种方法对每个节点使用一组通unfold规则,因此它可以自动搜索而无需手动模板。由于每个决策的可能选择数量很大,为了使sequential过程可行,这种方法在每个决策后只保留前 k 个候选程序。编译器基于一个可学习的代价模型评估并比较候选程序的性能以选择前k个候选程序,而其他候选程序被丢弃。在搜索过程中,候选程序是不完整的,因为只有部分计算图被展开或只做出了一些决策。Figure2 b 显示了这个过程。
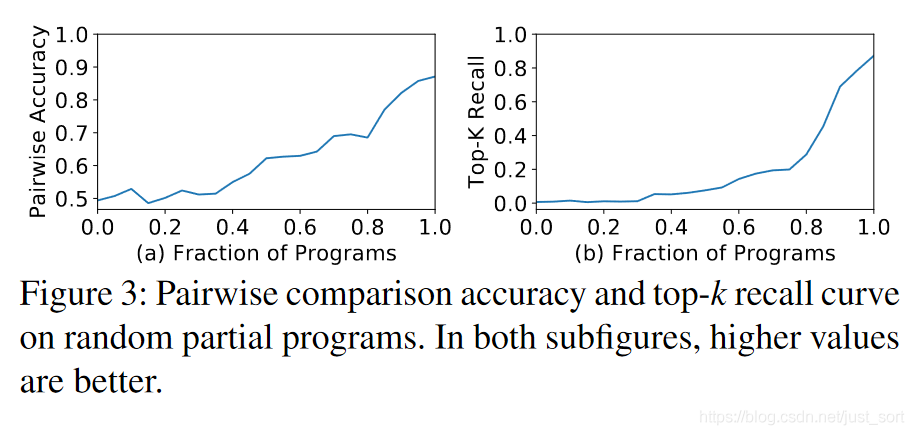
然而,评估不完整程序的最终性能有几个方面的困难:(1)在完整程序上训练的代价模型不能准确预测不完整程序的最终性能。代价模型只能在完整的程序上训练,因为我们需要编译程序并测量它们的执行时间以获得训练标签。直接使用该模型来评估不完整程序的最终性能会导致准确性较差。我们在来自搜索空间的 20,000个随机完整程序上训练我们的代价模型作为案例研究(第 5.2 节),并使用该模型来预测不完整程序的最终性能。不完整的程序是通过只应用完整程序的一小部分循环变换得到的。我们使用两个评价指标进行评估:成对比较的准确性和top-k 程序的recall分数(k=10)。如Figure 3 所示,两条曲线分别从50%和0% 开始,这意味着零信息的随机猜测给出了50%的成对比较准确度和0%的top-k召回率。两条曲线随着程序的完整度增加而迅速增加,这意味着代价模型对于完整程序的性能非常好,但无法准确预测不完整程序的最终性能。(2) 顺序决策的固定顺序限制了搜索空间的设计。例如,某些优化需要向计算图中添加新节点(例如,添加缓存节点,使用 rfactor[46])。不同程序的决策数量变得不同。很难将不完整的程序对齐以进行公平比较。(3) 基于sequential构建的搜索不具有可扩展性。扩大搜索空间需要添加更多的序列构建步骤,但这会导致更严重的累积误差。
Ansor’s hierarchical approach 如Figure2-c所示,Ansor基于分层搜索空间构建,该空间将high-level结构和low-level的细节解耦。Ansor自动构建计算图的搜索空间空间,不需要手动开发模板。然后Ansor从空间中采样完整的程序并对完整的程序进行微调,避免对非完整程序的不准确估计。Figure2展示了Ansor方法与现有方法之间的主要区别。
3. 设计概述
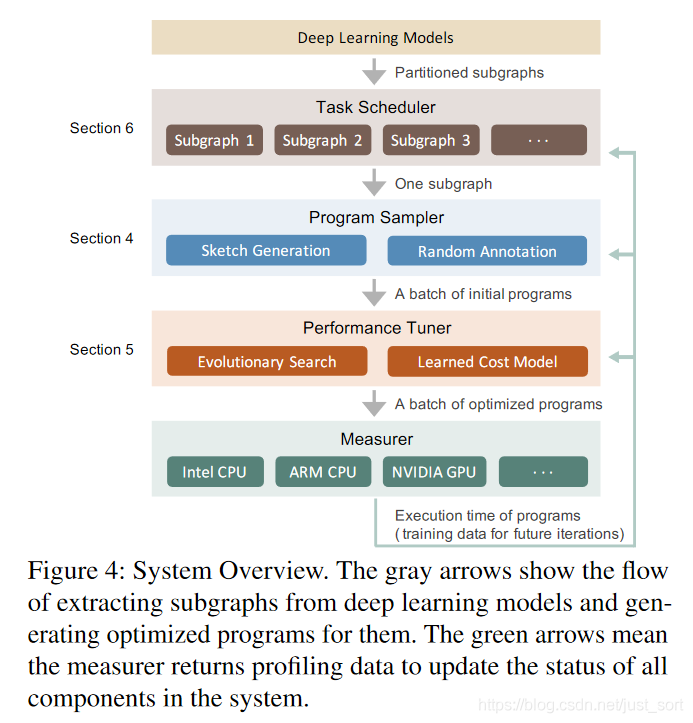
Ansor是一个自动的张量化程序生成框架。Figure 4展示了Ansor的整体架构。Ansor的输入是一组待优化的DNN。Ansor使用Relay[42]的算符融合算法将DNN从流行的模型格式(例如ONNX,TensorFlow PB)转换为小的子图,然后Ansor为这些子图产生张量化程序。Ansor具有三个重要的组件:(1)一个程序采样器,它构建一个大的搜索空间并从中采样不同的程序。(2)微调采样程序性能的性能调试器。(3)一个任务调度器,用于分配时间资源以优化 DNN 中的多个子图。
Program sampler. Ansor 必须解决的一个关键挑战是为给定的计算图生成一个大的搜索空间。为了覆盖具有各种high-level结构和low-level细节的各种张量化程序,Ansor利用具有两个级别的搜索空间的分层表示:草图和注释(第 4 节)。Ansor 将程序的high-level结构定义为草图,并将数十亿个low-level选择(例如,tile size、parallel、unroll annotations)作为注释。这种表示允许Ansor灵活地枚举high-level结构并有效地采样low-level细节。Ansor包含一个程序采样器,它从空间中随机采样程序以提供对搜索空间的全面覆盖。
Performance tuner. 随机采样程序的性能不一定好。下一个挑战是对它进行微调、Ansor使用进化搜索和一个可学习的代价模型迭代式微调(第5节)。在每次迭代中,Ansor使用重新采样的新程序以及来自先前迭代的性能还不错的程序作为初始种群执行进化搜索。进化搜索通过变异和交叉对程序进行微调,执行乱序重写并解决顺序构造的局限性。查询学习到的代价模型比实际测试快几个数量级,因此我们可以在几秒钟内评估数千个程序。
Task scheduler. 使用程序采样器和性能调试器允许 Ansor 为计算图找到高性能的张量化程序。直观地说,将整个DNN视为单个计算图并为其生成完整的张量化程序可能会实现最佳性能。然而,这是低效的,因为它必须处理搜索空间不必要的指数爆炸。通常,编译器将DNN的大型计算图划分为几个小的子图 [11, 42]。由于 DNN 的逐层构造特性,该划分对性能的影响可以忽略不计。这带来了Ansor最终的挑战:在为多个子图生成程序时如何分配时间资源。Ansor中的任务调度器(第 6 节)使用基于梯度下降的调度算法将资源分配给更可能提高端到端DNN性能的子图。
4. 程序采样器
算法搜索的搜索空间决定了它可以提找到的最佳程序。现有方法中考虑的搜索空间受以下因素限制:(1)手动计数(例如TVM)。通过模板手动枚举所有可能的选择是不切实际的,因此现有的手工模板只能启发式地覆盖有限的搜索空间。(2)贪心的早期剪枝(例如,Halide Auto-scheduler)。基于评估不完整程序来贪心的剪枝,避免算法搜索空间中的某些区域。
在本节中,我们介绍了通过解决上述限制来推动所考虑的搜索空间边界的技术。为了解决(1),我们递归应用一组灵活的推导规则来自动扩展搜索空间。为了避免(2),我们在搜索空间中随机采样完整程序。由于随机采样为每个要采样的点提供了均等的机会,因此我们的搜索算法可以潜在地探索所考虑空间中的每个程序。我们不依赖随机抽样来找到最佳程序,因为每个采样程序后来都经过了微调(第 5 节)。
为了采样可以覆盖一个大的搜索空间的程序,我们定义了一个具有两个级别的分层搜索空间:草图和注释。我们将程序的high-level结构定义为草图,并将数十亿个low-level选择(例如,tile size、parallel、unroll annoations)作为注释。在顶层,我们通过递归应用一些推导规则来生成草图。在底层,我们随机注释这些草图以获得完整的程序。这种表示从数十亿个低级选择中总结了一些基本结构,实现了high-level结构的灵活枚举和low-level细节的有效采样。
虽然 Ansor 同时支持CPU和GPU,但我们在4.1和4.2中解释了CPU的采样过程作为示例。然后我们在4.3中讨论了GPU的过程有何不同 。
4.1 草图的生成
如Figure4所示,程序采样器接受一个子图作为输入。图 5 中的第一列展示了输入的两个示例。输入具有三种等价形式:数学表达式、通过直接展开循环索引获得的相应朴素程序以及相应的计算图(有向无环图,或 DAG)。
为了给具有多个节点的 DAG 生成草图,我们按拓扑顺序访问所有节点并迭代构建结构。对于计算密集型且具有大量数据重用机会的计算节点(例如,conv2d、matmul),我们为它们构建基本的tile和fusion结构作为草图。对于简单的逐元素节点(例如 ReLU、逐元素添加),我们可以安全地内联它们。请注意,新节点(例如,缓存节点、布局变换节点)也可能在草图生成期间引入 DAG。
我们提出了一种基于推导的枚举方法,通过递归地应用几个基本规则来生成所有可能的草图。这种方法将DAG作为输入并返回一个草图的列表。我们定义状态,其中S是当前为DAG部分生成的草图,i是当前工作的节点的索引。DAG中的节点是从输出到输入按照拓扑序进行排列的。推导是从初始的naive程序和最后一个节点开始,或者说初始状态可以写成=(native程序,最后一个节点的索引)。然后我们尝试将所有推导规则递归地应用于状态。对于每个规则,如果当前状态满足应用条件,我们将规则应用到然后获得,其中。这样工作节点的索引i就会单调减少,当i变成0的时候状态就是终止状态。在枚举过程中,可以将多个规则应用于一个状态以生成多个后续状态。一个规则也可以产生多个可能的后续状态,所以我们维护一个队列来存储所有中间状态。当队列为空时,该过程结束。在草图生成结束时,所有处于终止状态的的生成草图列表。一般来说子图生成的草图数量会小于10。

Derivation rules. Table1列出了我们给CPU使用的推导规则。这里先声明一些述语,比如**IsStrictInliable(S, i)**表示子图S中的节点i是否是element-wise的OP(比如ReLU,这种OP可以被内联优化,论文说的是inlined)。HasDataReuse(S, i) 表示S中的节点i是否是计算密集型算子并且是否有大量的算子内数据重用的机会(例如卷积,矩阵乘法)。HasFusibleConsumer(S, i) 表示是否S中的节点i只有一个消费者j并且j可以被融合进节点i(例如matmul+bias_add,conv2d+relu)。HasMoreReductionParallel(S, i) 表示S中的节点i是否在空间维度上几乎无法并行但在reduction维度上有足够的并行机会(例如计算二维矩阵乘法,)。我们对计算定义进行静态分析以获得这些述语的值。分析是通过解析数学表达式中的读写模式自动完成的。接下来,我们介绍每个推导规则的功能。

规则1是简单的跳过一个节点,如果它不是严格内联的。规则2是对于严格内连的节点总是执行内联操作。由于规则1和规则2的条件是互斥的,i>1的状态总是可以满足其中之一并继续推导。
规则 3、4和5处理具有数据重用的节点的多级tiling和fusion。规则3对数据可重用节点执行多级tiling。对于 CPU,我们使用“SSRSRS”tile结构,其中“S”代表空间循环的一个tile级别,“R”代表reduction循环的一个tile级别。(关于tile这种scheduler可以看一下我之前的介绍:【从零开始学深度学习编译器】二,TVM中的scheduler) 。例如对于Figure5中的Example Input1来讲,i和j都是空间循环,而k是reduction循环。对于矩阵乘法来说"SSRSRS" tile结构讲原始的三重for循环扩展为。虽然我们不置换循环的顺序,但这种多级tiling也可以涵盖一些reorder(上面篇文章也讲了reorder)的情况。例如上面的10级循环可以通过将其它循环的长度设为1来专门用于简单的reorder。“SSRSRS” tile结构对于计算密集型OP是通用的(例如, matmul, conv2d, conv3d) 在深度学习中,因为它们都由空间循环和reduce循环组成。
规则 4 执行多级tiling并融合可融合的消费者。例如,我们将element-wise节点(例如 ReLU、bias add)融合到tiling节点(例如 conv2d、mat-mul)中。如果当前数据可重用节点没有可融合的消费者,则规则5将添加一个缓存节点。例如,DAG 中的最终输出节点没有任何消费者,因此默认情况下它直接将结果写入主内存,并且由于内存访问的高延迟而导致效率低下。通过添加缓存节点,我们在 DAG 中引入了一个新的可融合的消费者节点,然后可以应用规则4将这个新添加的缓存节点融合到最终的输出节点中。缓存节点融合后,现在最终输出节点将其结果写入缓存块,当块中的所有数据计算完毕后,缓存块中的结果将立即写入主内存。
规则6可以使用 factor[46] 将reduction循环分解为空间循环以带来更多并行性。
Examples Figure5展示了三个产生草图的例子。草图与 TVM 中的手工模板不同,因为手工模板指定了high-level的结构和low-level的细节,而草图仅定义了高级结构。对于示例输入 1,DAG 中四个节点的排序顺序是 (A,B,C,D)。为了导出 DAG 的草图,我们从输出节点 D(i=4) 开始,并将规则一一应用于节点。具体来说,生成的草图1的推导规则是:
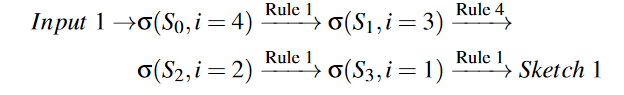
对于示例输入2,五个节点的排序顺序是 (A,B,C,D,E)。类似地,我们从输出节点 E(i=5) 开始并递归地应用规则。生成的草图 2 如下:
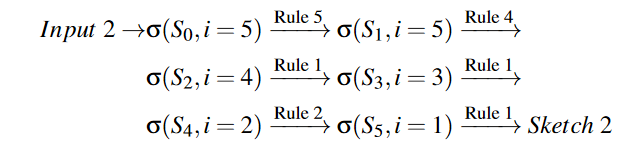
类似地,生成草图三是由以下规则顺序应用:
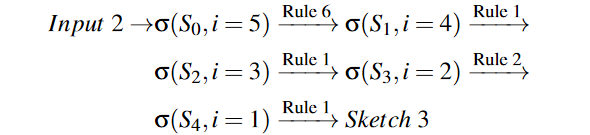
Customization 虽然提出的规则足够实用,可以涵盖大部分算子的结构,但总有例外。例如一些特殊的算法(例如Winograd卷积[30])和加速器内部函数(例如TensorCore[37])需要特殊的tiling结构才会有效。虽然模板推导的搜索方法(TVM)可以为每一个新的案例制作一个新的模板,但它需要大量的设计工作。另一方面,Ansor中基于推导的草图生成足够灵活,可以为新兴算法和硬件生成所需的结构,因为我们允许用户注册新的推导规则并将它们与现有规则无缝集成。
4.2 随机注释
上一节生成的草图是不完整的程序,因为它们只有tiling结构,没有特定的tiling尺寸和循环注释。例如并行,unroll和矢量化。在本节中,我们对草图进行注释,使它们成为用于微调和评估的完整程序。给定生成的草图列表,我们随机选择一个草图,随机填充tile尺寸,并行一些外循环,矢量化一些内循环,并unroll一些内循环。我们还随机改变了程序中一些节点的计算位置,对tile结构进行了微调。本小节中提到的的所有“随机”表示所有有效值的均匀分布。如果某些算法需要自定义注释才会有效(例如特殊的unroling),我们允许用户在计算定义中给出简单的提示以调整注释策略。最后,由于更改常量张量的布局可以在编译时完成,并且不会带来运行时开销,因此我们根据多级tile结构重写常量张量的布局使其尽可能的缓存友好。这种优化是有效的,因为卷积或者全连接层的权重张量是静态张量。
随机抽样的例子如Figure5所示,抽样程序的循环次数可能比草图少,因为长度为1的循环被简化了。
4.3 GPU 支持
对于GPU,我们将多级tiling结构从“SSRSRS”改为“SSSRRSRS”以匹配 GPU 的架构。tiling中的前三个空间循环分别绑定到 BlockIdx、虚拟线程(用于减少 bank 冲突)和 ThreadIdx。我们添加了两个草图推导规则,一个用于通过插入缓存节点来利用共享内存(类似于规则 5),另一个用于跨线程reduction(类似于规则 6)。
5. 性能微调
程序采样器采样的程序具有良好的搜索空间覆盖率,但质量没有保证。这是因为优化选择,如tiling结构和loop注释,都是随机采样的。在本节中,我们将介绍通过进化搜索和可学习的代价模型微调采样程序性能的性能调优器。
微调是迭代执行的。在每次迭代中,我们首先使用进化搜索根据学习到的成本模型找到一小批性能还不错的程序。然后我们在硬件上测量这些程序以获得实际的执行时间花费。最后,从中获得的分析数据用于重新训练成本模型,使其更加准确。
进化搜索使用随机抽样的程序以及上次评估中的高质量程序作为初始种群,并应用变异和交叉来生成下一代。可学习的代价模型用于预测每个程序的性能,在我们的例子中是一个程序的吞吐量。我们执行固定数量的进化搜索,并选择在搜索过程中的最佳程序。我们利用可学习得代价模型,因为代价模型可以给出相对准确的程序性能估计,同时比实际预测快几个数量级,它使我们能够在几秒钟内比较搜索空间钟数以万计的程序,并挑选出还不错的程序进行实际评估。
5.1 进化搜索
进化搜索 [54] 是一种受生物进化启发的通用元启发式算法。通过对高质量程序进行迭代变异,我们可以生成具有潜在更高质量的新程序。进化从采样的初始代开始。为了产生下一代,我们首先根据一定的概率从当前一代中选择一些程序。选择程序的概率与可学习的代价模型(第 5.2 节)预测的适应度成正比,这意味着具有更高性能的程序被选择的概率更高。对于选定的程序,我们随机应用其中一个进化操作来生成一个新程序。 基本上,对于我们在采样过程中做出的决策(§4.2),我们都设计了相应的进化操作来重写和微调它们。
Tile size mutation 此操作扫描程序并随机选择一个tiled循环。对于这个tiled循环,它将随机选择一个循环将其长度随机除以一个数,并将这个数乘到另外一个循环上。由于此操作使tile 尺寸的乘积等于原始循环长度,因此变异程序始终有效。
Parallel mutation. 此操作扫描程序并随机选择一个已用并行注释的循环。对于此循环,此操作通过融合其相邻循环或者通过一个factor分解此循环来改变并行的粒度。
Pragma mutation. 程序中的某些优化由特定于编译器的编译pragma指定。此操作扫描程序并随机选择一个编译pragma。对于这个 pragma,这个操作会随机将其变异为另一个有效值。例如,我们的底层代码生成器通过提供一个auto_unroll_max_step=N pragma 来支持最大步数的自动展开。我们随机调整数字 N。
Computation location mutation. 该操作扫描程序并随机选择一个不是多级tiled的灵活节点(例如,卷积层中的填充节点)。对于这个节点,操作随机改变它的计算位置到另一个有效的节点。(这里个人理解就是Pad可以提前做,不改变Feature Map大小)
Node-based crossover. 交叉是通过组合来自两个或多个父母的基因来产生新后代的操作。Ansor 中程序的基因是它的重写步骤。Ansor 生成的每个程序都是从最初的简单实现中重写的。Ansor 在草图生成和随机注释期间为每个程序保留完整的重写历史。我们可以将重写步骤视为程序的基因,因为它们描述了这个程序是如何从最初的朴素程序形成的。在此基础上,我们可以通过结合两个现有程序的重写步骤来生成一个新程序。但是,任意组合两个程序的重写步骤可能会破坏步骤中的依赖关系并创建无效程序。因此,Ansor 中交叉操作的粒度基于 DAG 中的节点,因为跨不同节点的重写步骤通常具有较少的依赖性。Ansor 为每个节点随机选择一个父节点,并合并所选节点的重写步骤。当节点之间存在依赖关系时,Ansor 会尝试通过简单的启发式方法来分析和调整步骤。Ansor 进一步验证合并的程序以保证功能的正确性。验证很简单,因为 Ansor 只使用了一小部分循环转换重写步骤,底层代码生成器可以通过依赖分析来检查正确性。
进化搜索利用变异和交叉来重复生成一组新的候选集,并输出一小组具有最高分数的程序。这些程序将在目标硬件上进行编译和测试,以获得真实的运行时间花费。然后使用收集到的测量数据更新代价模型。通过这种方式,可学习代价模型的准确性逐渐提高以匹配目标硬件。因此,进化搜索逐渐为目标硬件平台生成更高质量的程序。
与 TVM 和 FlexTensor 中的搜索算法只能在固定的类网格参数空间中工作不同,Ansor 中的进化操作是专门为张量化程序设计的。它们可以应用于一般的张量化程序,可以处理依赖复杂的搜索空间。与Halide auto-scheduler中的unfold规则不同,这些操作可以对程序进行乱序修改,解决顺序限制。
5.2 可学习的代价模型
代价模型对于在搜索过程中快速估计程序的性能是必要的。我们采用类似于相关工作[2, 12]的可学习的代价模型,具有新设计的程序特征。基于可学习的代价模型的系统具有很大的可移植性,因为单个模型设计可以通过输入不同的训练数据来重用于不同的硬件后端。
由于我们的目标程序主要是数据并行张量化程序,它们由多个交错循环嵌套构成,最里面的语句是几个赋值语句,我们训练代价模型来预测循环中最里面的一个非循环语句的得分。对于一个完整的程序,我们对最里面的每个非循环语句进行预测,并将这些预测值加起来作为分数。我们通过在完整程序的上下文中提取特征来为最内层的非循环语句构建特征向量。提取的特征包括算术特征和内存访问特征。提取特征的详细列表在附录 B 中。
我们使用加权平方误差作为损失函数。因为我们最关心的是从搜索空间中识别出性能良好的程序,所以我们更加重视运行速度更快的程序。具体来说,模型f在程序P上吞吐量为y的的损失函数为:
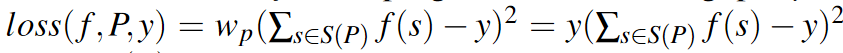
其中S(P)是P中最内层非循环语句的集合。我们直接使用吞吐量作为权重,来训练一个梯度提升决策树 [9] 作为底层模型f。为所有的DAG的所有张量化程序训练一个模型,我们将来自同一个DAG的所有程序的吞吐量归一化到[0, 1]范围内。在优化DNN时,测试的程序的数量通常少于30000。在如此小的数据集上训练梯度提示决策树非常快,因此我们每次都训练一个新模型而不是进行增量更新。
6. Schedule Task
这部分OpenMMLAB的文章已经讲的比较清楚了,就不翻译了,这里直接引用一下:
引用自OpenMMLAB https://zhuanlan.zhihu.com/p/360041136
ANSOR 首先会将计算图切分成多个子图并对这些子图分别进行优化。深度学习网络的总优化次数由 ANSOR 的使用者给定,然后由 Schedule Task 模块来确定如何将这些优化次数分配到不同的子图优化任务上。
为了保证对热点子图的重点优化,ANSOR 会尽量选择优化效果明显的子图进行优化。比如最小化一个 DNN 网络的时延,我们首先给出优化的目标函数:

7. 评估
这里简单介绍一下Ansor的表现,基于论文中的图表。
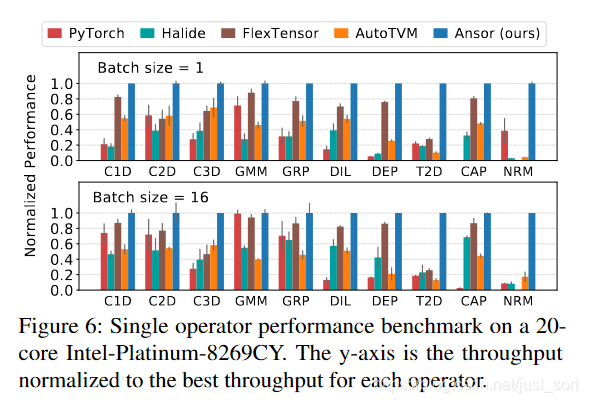
在Figure6中可以看到,在不同的算子和BatchSize设置下,Ansor均取得了最优的性能,Ansor的搜索空间很大是取得性能提示的关键因素。
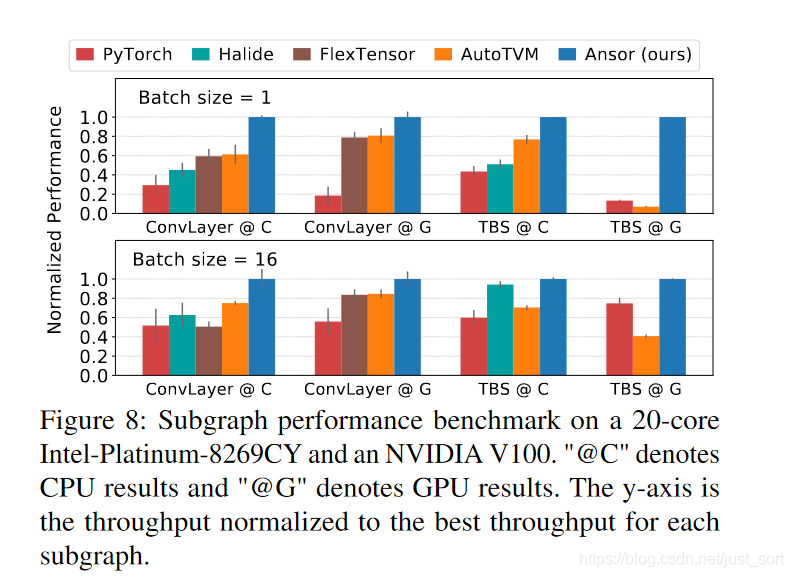
这里ConvLayer是包含Conv+BN+ReLU的子图,而TBS是包含两个矩阵转置,一个Batch矩阵乘和一个Softmax的子图。@C表示CPU的测试结果,@G表示GPU的测试结果。可以看到无论是在CPU还是GPU上,对于这些常见子图的优化,Ansor全面领先。
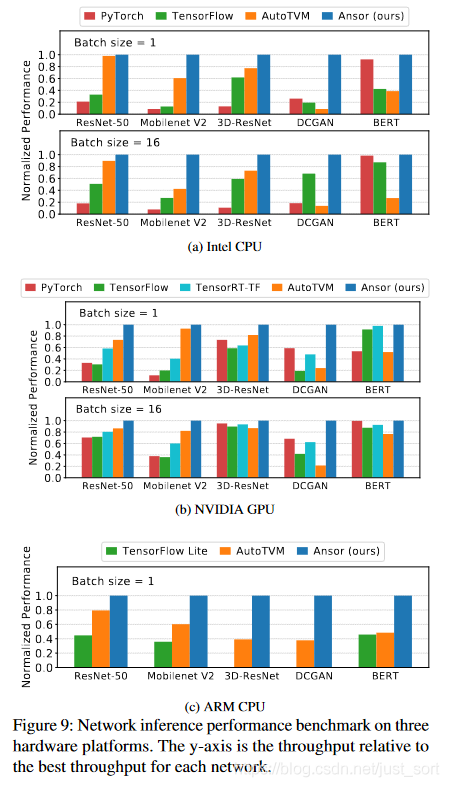
Figure9则展示了一些流行的DNN模型在Intel CPU、Arm CPU以及NVIDIA GPU上的性能测试结果,和业界的主流加速库相比,Ansor也取得较大幅度的性能领先。
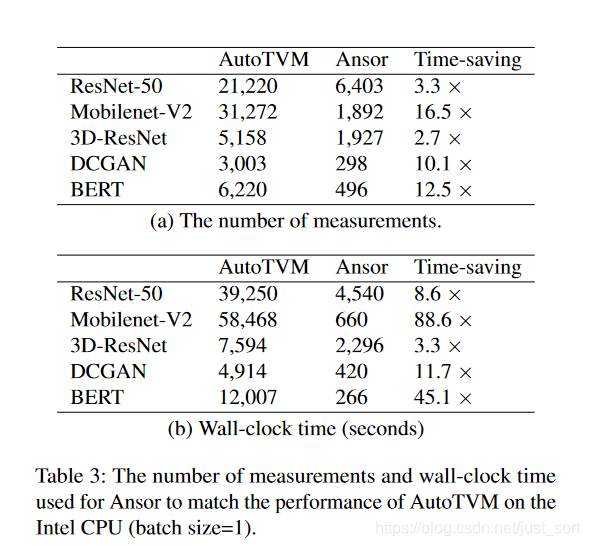
最后相信大家还比较关注的一组数据是Ansor的搜索时间。从Tabel3中可以看出在流行的DNN模型上,Ansor的搜索时间相对于Auto TVM都有提升,即使Ansor的搜索空间更大。
8. 相关工作
略,感兴趣可以看下原论文。
9. 现在和将来的工作
略,感兴趣可以看下原论文。
10. 结论
我们提出了 Ansor,这是一种自动搜索框架,可为深度神经网络生成高性能的张量化程序。通过有效探索大型搜索空间并优先考虑性能瓶颈,Ansor 找到了现有方法搜索空间之外的高性能程序。Ansor 在各种神经网络和硬件平台上的性能优于现有的手工库和基于搜索的框架高达3.8倍。通过自动搜索更好的程序,我们希望 Ansor将帮助缩小不断增长的计算能力需求与有限的硬件性能之间的差距。Ansor已集成到 Apache TVM 开源项目中。