
一文读懂基于DL的无人驾驶视觉感知系统的应用场景
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
本文来源:智能车情报局
编辑:智车科技
/ 导读 /

基于深度学习的计算机视觉,应用于无人驾驶的视觉感知系统中,主要分为四大块:
动态物体检测(Dynamic Object Detection)
通行空间(Free Space)
车道线检测(Lane Detection)
静态物体检测(Static Object Detection)

检测需求:对车辆(轿车、卡车、电动车、自行车)、行人等动态物体的识别;




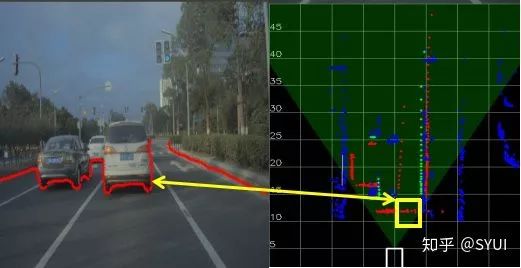

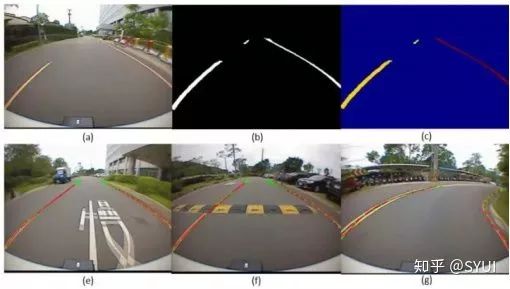


静态物体检测:


本文仅做学术分享,如有侵权,请联系删文。
评论