
旷视 | 大且高质量的数据集用于目标检测
共 4123字,需浏览 9分钟
·
2022-07-09 19:00
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


来源:计算机视觉战队
导读
今天,给大家介绍一个新的大型目标检测数据集Objects365,它拥有超过600,000个图像,365个类别和超过1000万个高质量的边界框。由精心设计的三步注释管道手动标记,它是迄今为止最大的对象检测数据集合(带有完整注释),并为社区创建了更具挑战性的基准。

摘要先前看
Objects365可用作更好的特征学习数据集,用于对位置敏感的任务,例如目标检测和分割。Objects365预训练模型明显优于ImageNet预训练模型:当在COCO上训练90K / 540K迭代时,AP改善了5.6(42 vs 36.4)/ 2.7(42 vs 39.3)。同时,当达到相同的精度时,可以大大减少微调时间(差异的10倍)。Object365的更好的泛化功能也已在CityPersons,VOC Segmentation和ADE中得到验证。我们将发布数据集和所有预先训练的模型。
01

目标检测是计算机虚拟环境中的一项基本任务。PASCAL VOC和COCO为目标检测的快速发展做出了巨大贡献。从DPM这样的传统方法到R-CNN和FPN等基于深度学习的方法,以上两个数据集用作“黄金”基准,以评估算法并推动研究的进行。今天我们分享的将进一步介绍了一种新的大规模、高质量的目标检测数据集Objects 365,主要集中在三个方面:规模、质量和泛化。
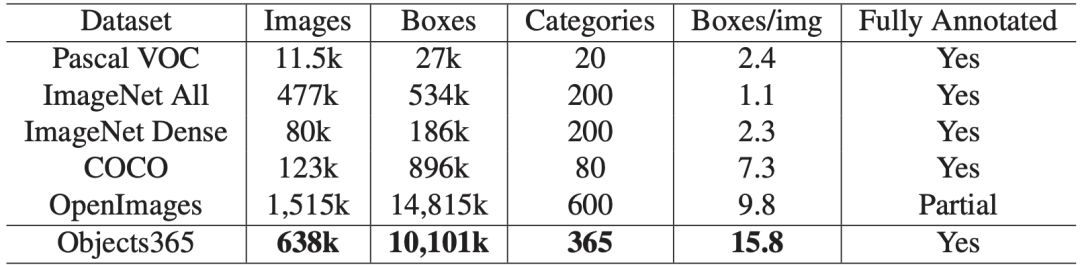
02
接下来我们来看看几处亮点:


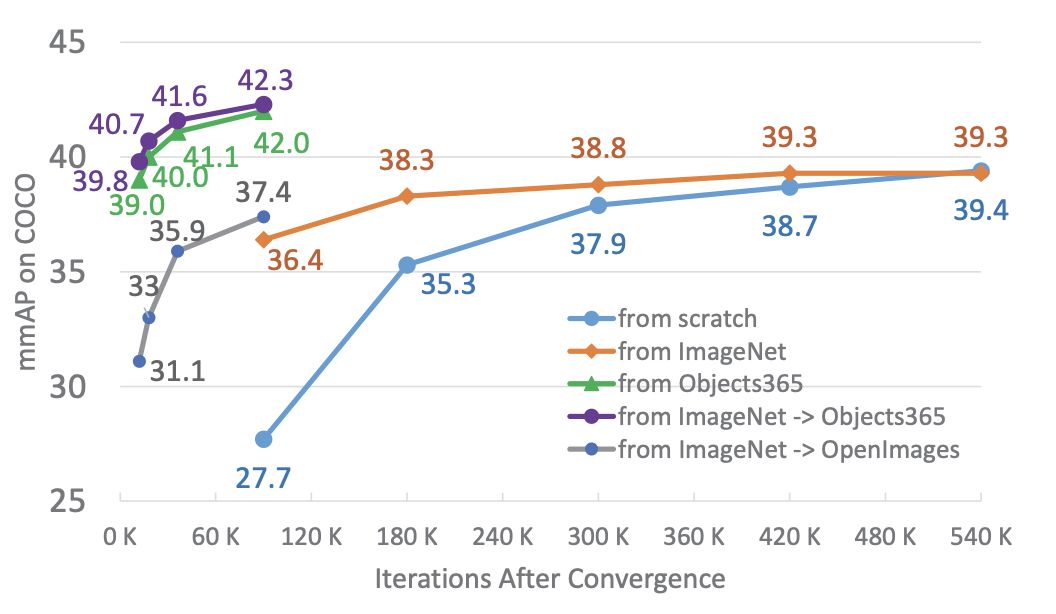
新的Objects365数据集直接解决了上述两个问题,并为特性学习提供了更好的选择。如下图所示,Objects 365预训练的特性可以显著优于基于ImageNet,即使是有足够长的训练时间(540K迭代)的特性。
此外,利用Objects365特征,可以在一个数量级的训练时间内获得类似的结果。
03
Annotation Pipeline
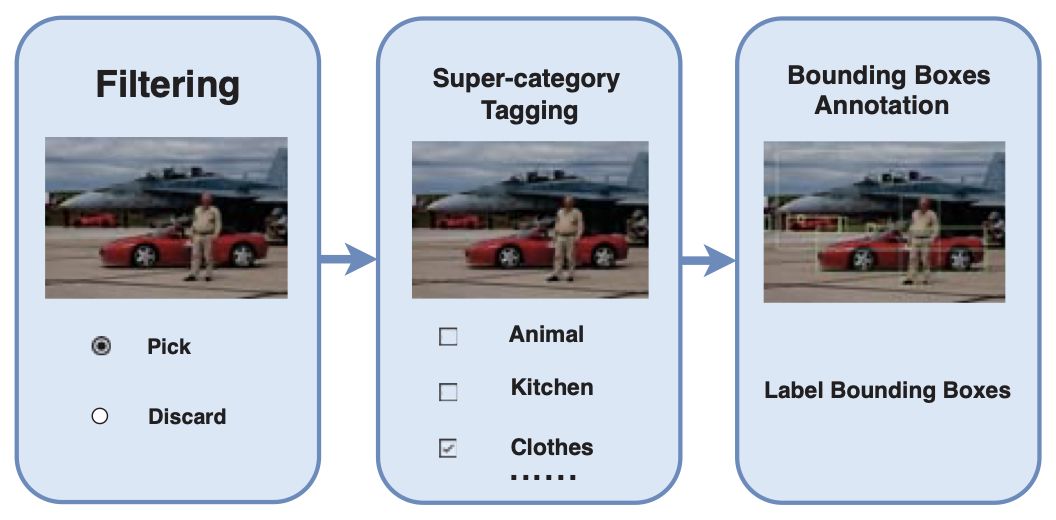
注解者几乎不可能记住并注释所有365个类别。此外,少数图像应该被拒绝,因为图标图像或图像没有365个目标类别。在已有的ImageNet和COCO等数据集的激励下,以及*中对可扩展多类注释的讨论,我们按照以下三个步骤设计了我们的注释流程。
* Jia Deng, Olga Russakovsky, Jonathan Krause, Michael S Bernstein, Alex Berg, and Li Fei-Fei. Scalable multi-label annotation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 3099–3102. ACM, 2014
第一步执行两类分类。如果图像是非标志性的,或者在11个超级类别中至少包含一个目标实例,那么它将被传递到下一个步骤;在第二步中,包含11个超级类别的图像级标记将被标记,可以用多个标签标记图像;在第三步中,将分配一个注释器将目标实例标记在一个特定的超级类别中。属于超级类别的所有目标实例都应与目标名称一起用边框标记。
如上图所示,基于所建议的注释流程,每个注释器只需熟悉一个超级类别中的目标类别,而不是所有365个对象类别。这不仅提高了标注效率,而且提高了标注质量。
Classification Rule
它为标签中的歧义情况定义了明确的优先顺序和function优先原则。例如,在上图左边,可以将对象视为“龙头”或“茶壶”。根据我们的分类规则,我们使用function优先原则,在这种情况下,对象将被标记为“TAP”。

Bounding Box Rules

由于注解器的多样性,对边框的注释有时可能不一致。当边界框存在歧义时,我们定义了以下规则。
注释器必须覆盖最大的边框,这不会导致定义目标类别的模糊性。例如,我们需要将时钟的装饰部分包含在上图左边图形中,因为装饰部分属于时钟,不会导致对目标类别的误解。对于上图中的右边图形,注释器需要标记小的边界框,因为时钟的外部区域将导致另一个类别为“塔”。
Statistics

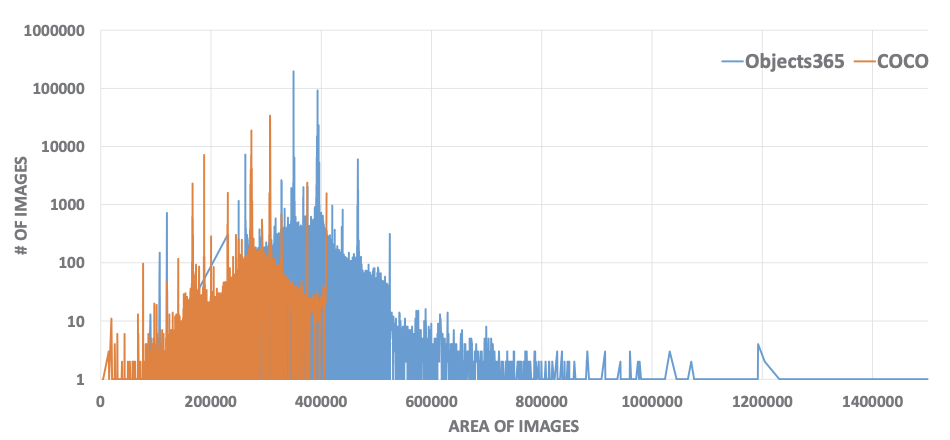
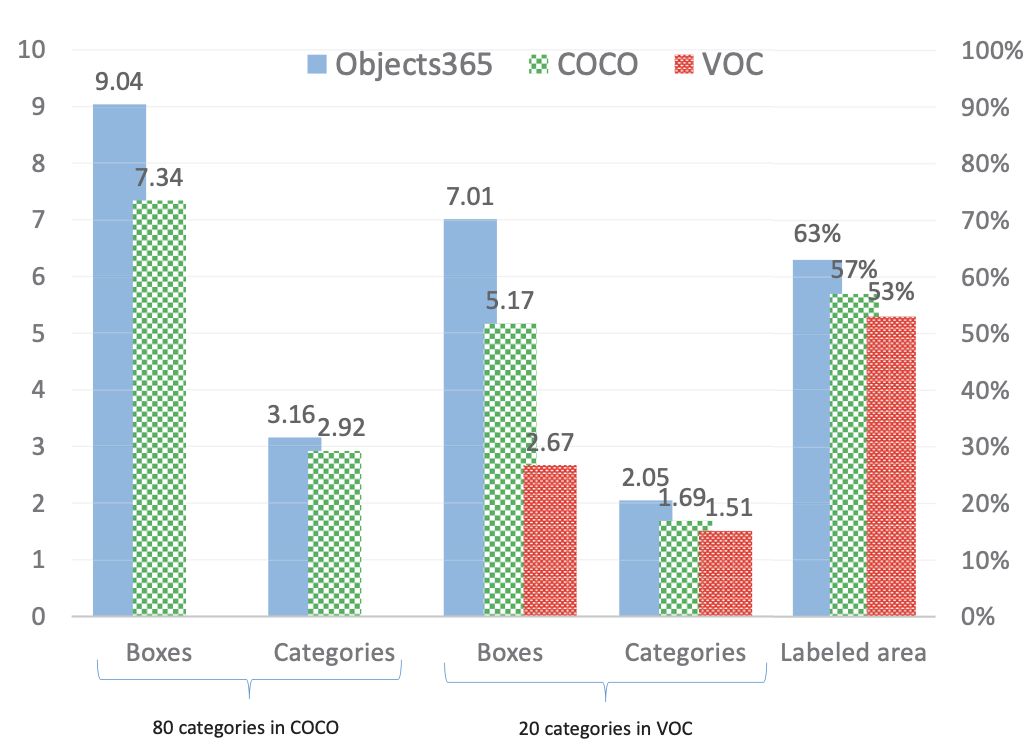
Quality
为了验证Objects 365数据集的质量,三个训练有素的注释者被要求对200个随机选择的图像进行标记。总共有3250个边框,基于注释器的细化。92%的实例在原始注释中进行注释。注释回忆与CoCO和OpenImage的比较见下表。

对于注释的精度,如果目标类别错误或注释边界框不准确,则考虑假正。Objects365的精度明显高于COCO,分别为91.7%和71.9%。
04
Results of the baseline algorithms on the Objects365 dataset


Diagnosis results on Objects365 and COCO
A comparison of different learning rate strategies for fine- tuning on the COCO benchmark

Generalization ability of general object detection results on the COCO dataset
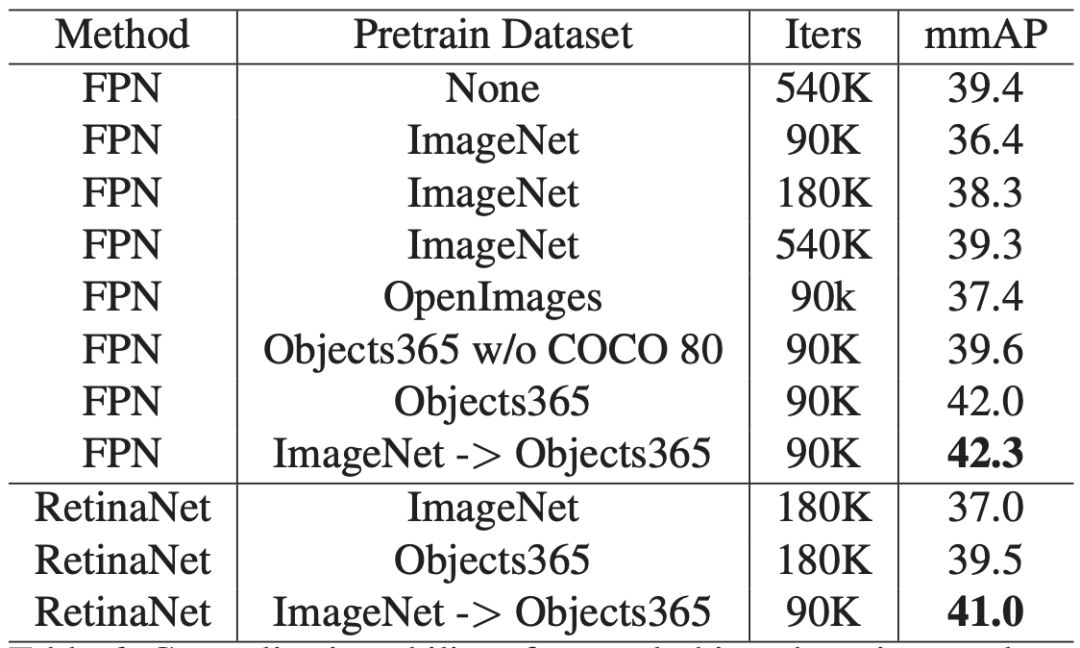
以下是一些列实验验证结果:

An illustration of the results on the Objects365 dataset
Generalization ability of object detection results on the PASCAL VOC dataset. The results are implemented based on FPN with Resnet50 backbone

Generalization ability of semantic segmentation results on the PASCAL VOC dataset. The results are implemented based on PSPNet with Resnet50 backbone

Comparison of the training time for the COCO general detection task. The algorithm is implemented based on the FPN with the Resnet50 backbone. Iterations denotes the number of iterations for the COCO training.

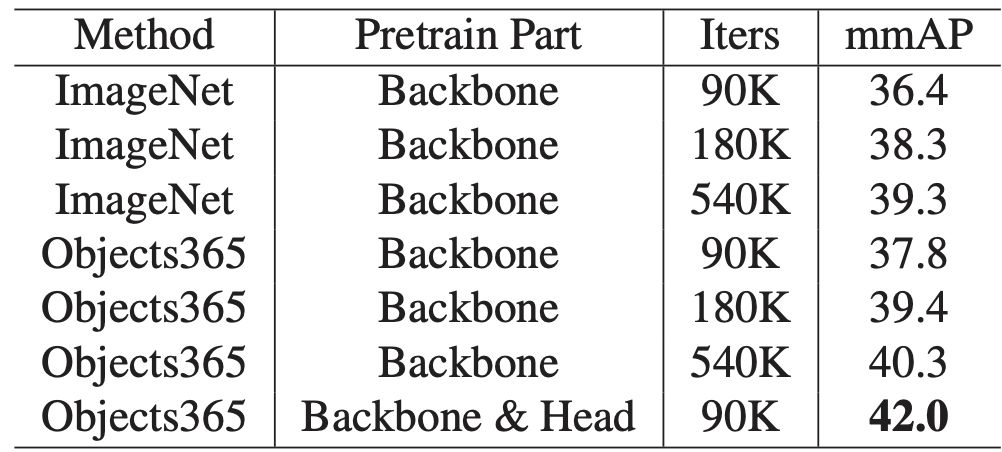
Comparison of the pretraining backbone only against pretraining both the backbone and head on the COCO benchmark. The results are implemented based on FPN with Resnet50 back- bone. “Iters” denotes the number of iterations for the COCO training.
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~