
基于卷积神经网络(CNN)的仙人掌图像分类
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
今天我们的目标是建立一个分类器,将图像分类为“仙人掌”或“非仙人掌”。


这种分类问题是kaggle挑战的内容之一。目标是建立一个分类器,将图像分类为“仙人掌”或“非仙人掌”。训练集包含17500张图像,而验证集包含4000张图像。具有仙人掌迹象的图像位于名为cactus的文件夹中,反之亦然。以下是训练数据集中的示例。

仙人掌

没有仙人掌
当我们通过用pyplot库绘制其中一些图像时,我们可以观察到它们的大小不同,这对于以后的训练过程是不利的。另请注意,我们已用指示仙人掌和非仙人掌的1和0标记了所有图像。

因此,我们需要将所有图像规格化为相同大小。根据我们的实验,最佳策略是将这些图像裁剪为48 x 48像素大小。以下是一些裁剪的图像。第一行显示原始图像,第二行显示更改的图像。

这种方法的好处是它可以保存图像的所有细节,但是有时会丢失图像的边缘,如果图像太小,我们需要使用黑色背景扩展图像以使其与图像的大小相同。丢失边缘可能是一个大问题,因为我们可能会把仙人掌从原图像中切除了。
卷积神经网络包含3层卷积层和2个完全连接层。每个卷积层都有一个3 x 3的滤波器,该滤波器的步幅为2,输出为64个节点。之后,数据会通过最大池化层,以防止过度拟合并提取有用的信息。
model = Sequential()model.add(Conv2D(64, (3,3), input_shape = X_train.shape[1:]))model.add(Activation(‘relu’))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(64, (3,3)))model.add(Activation(‘relu’))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(64, (3,3)))model.add(Activation(‘relu’))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Flatten())model.add(Dense(64))model.add(Dense(1))model.add(Activation(‘sigmoid’))model.compile(loss=”binary_crossentropy”,optimizer=”adam”,metrics=[‘accuracy’])history = model.fit(X_train, Y_train, batch_size=32, epochs=10, validation_split=0.1, use_multiprocessing=True)model.save(‘model_48_crop’)
以下是模型结构的概述。

模型总结
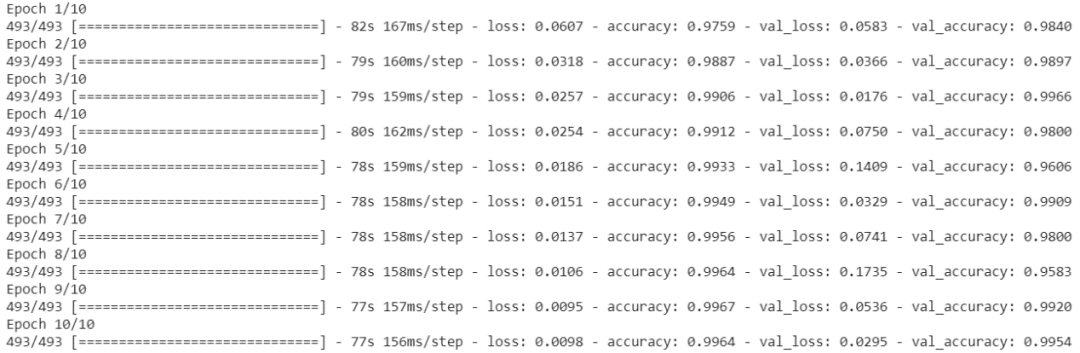
我们用10个epochs对模型进行训练,结果显示出惊人的效果。在下面的代码段中,第一个精度是训练精度,第二个精度是验证精度。请注意,在最终预测之前,我们将训练集的一部分(10%)用作验证集。
现在,我们使用kaggle提供的validation_set作为测试集,以对我们的训练模型进行最终预测。
testdata = pd.read_pickle(“pickled_data_validation/crop_images(48, 48).pkl”)test_images = testdata.loc[:, data.columns != ‘class’]test_images = test_images.to_numpy()test_images = test_images.reshape((len(test_images),48, 48, 3))test_images = test_images/255.0print(test_images.shape)test_labels = testdata[‘class’]test_labels = test_labels.to_numpy()type(test_labels)test_labels = test_labels.reshape((len(test_labels),1))loss, acc = new_model.evaluate(test_images, test_labels, verbose=2)print(‘Restored model, accuracy: {:5.2f}%’.format(100*acc))
这是结果。它达到了近99%的准确率,这是惊人的。

这篇文章的主要目的是与大家分享卷积网络的结构,解决了这类二元分类问题,例如猫和狗的图像分类。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~