
女娲算法,杀疯了!

今天分享一个「多模态」算法 NÜWA(女娲)。

论文的开头,就放出了效果,NÜWA 包揽了 8 项经典的视觉生成任务的 SOTA。
论文表示,NÜWA 更是在文本到图像生成中“完虐” OpenAI DALL-E。
碾压各种对比的算法效果,杀疯了!
NÜWA 效果
我们先看下 NÜWA 这算法在 8 项经典的视觉生成任务中的表现。
Text-To-Image(T2I)
文字转图片任务,其实就是根据一段文字描述,生成对应描述的图片。
比如:
A dog with gogglesstaring at the camera.
一只戴着护目镜,盯着摄像机的狗。

还有更多效果:

NÜWA 生成的效果看起来就没那么违和,从论文的效果看,很真实!

效果非常 Amazing。
Sketch-To-Image (S2I)
草图转图片任务,就是根据草图的布局,生成对应的图片。
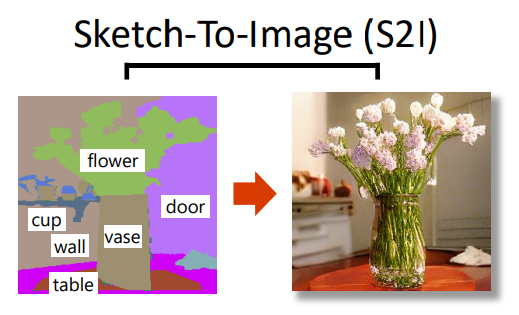
比如:
在一张图片上,画个大致轮廓,就可以自动“脑补”图片。
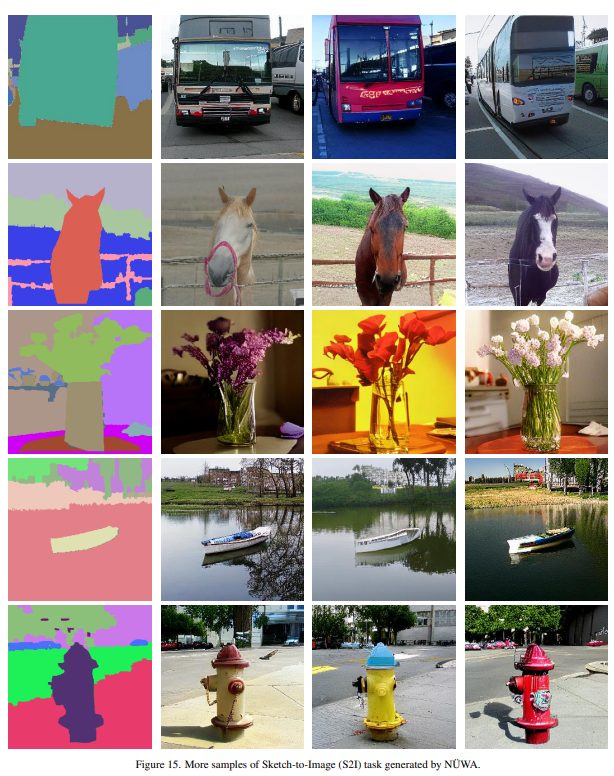
这效果真是开了眼了,真实效果真如论文这般的话,那确实很强。

这个算法,可以用在很多有意思的场景。
Image Completion (I2I)
图像补全,如果一副图片残缺了,算法可以自动“脑补”出残缺的部分。

好家伙,是不是又有一些大胆的想法了?
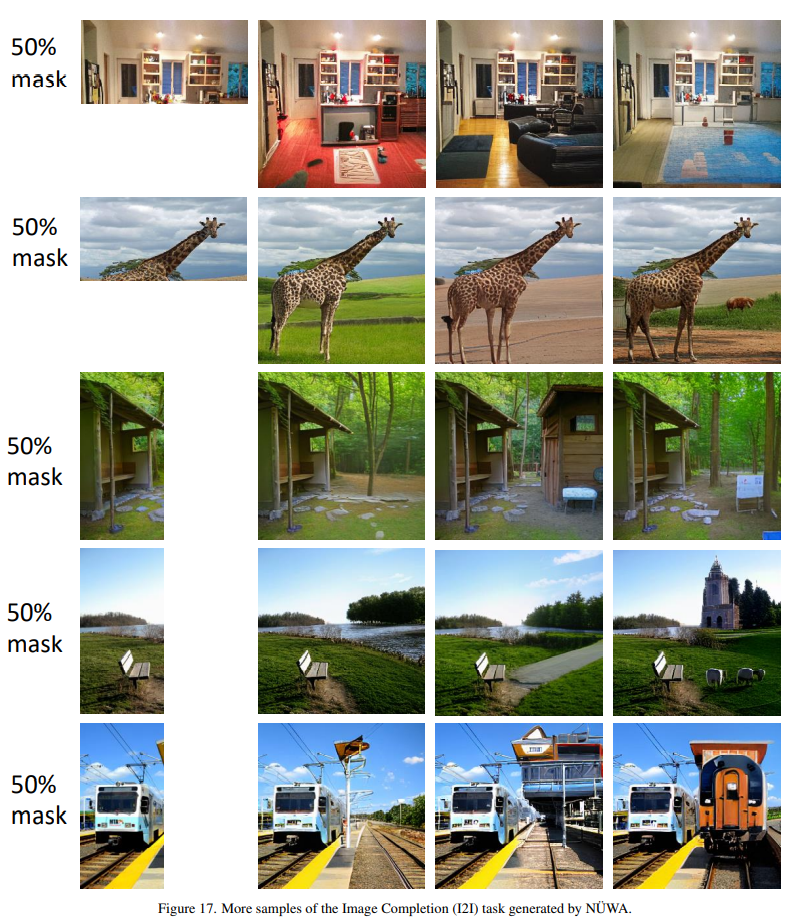
这个遮挡还算可以,还有更细碎的。
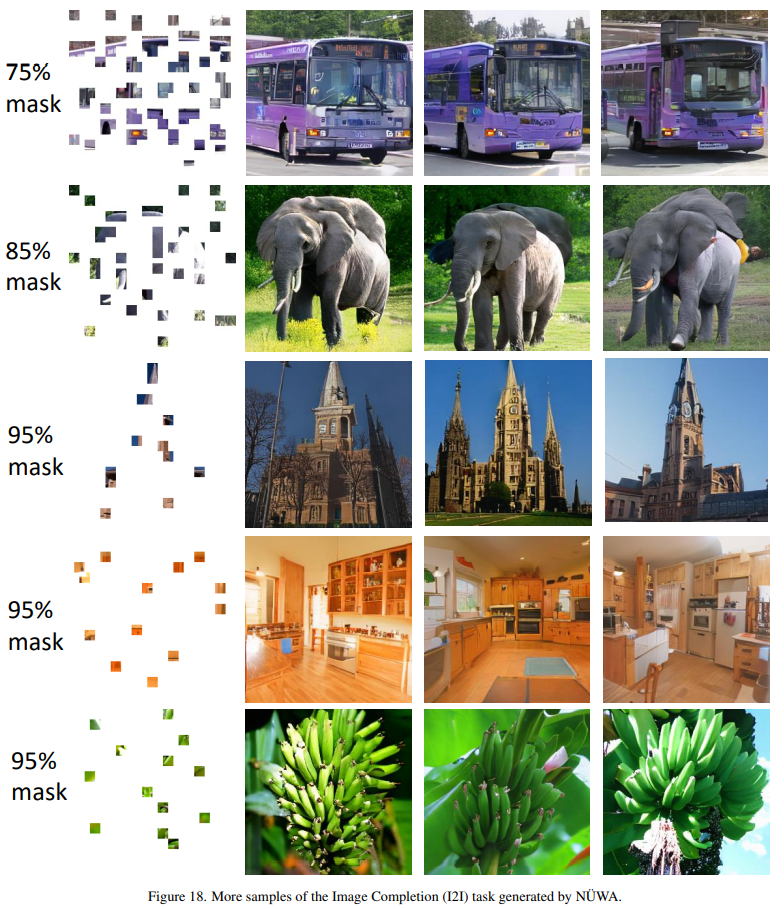
图片碎成这样,还能“脑补”出画面,我很期待代码。
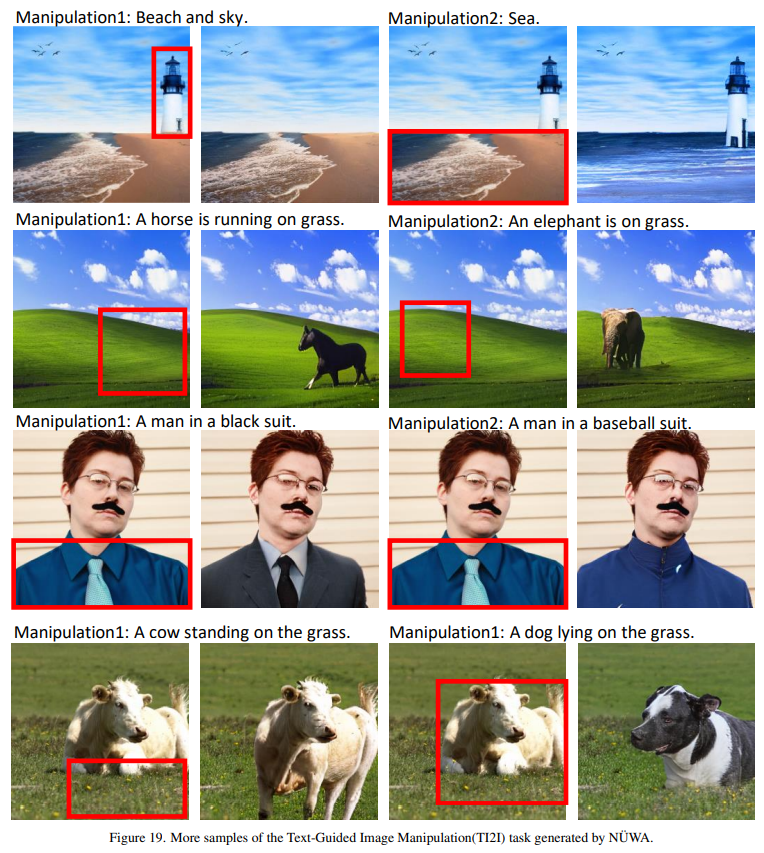
Image Manipulation (TI2I)
图片处理,根据文字描述,处理图片。
比如:
有一副草原的图片,然后增加一段描述:
a horse is running on the grassland
一匹马奔跑在草原上,然后就可以生成对应的图片。

这惊人的理解力。
这让我想起来了 P 图吧大神,恶搞的作品。
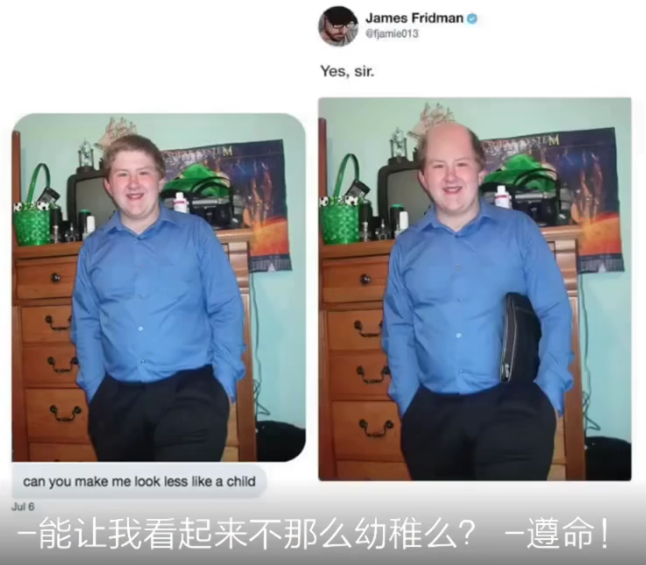
有了这个算法,咱也可以试一试了,哈哈。
Video
这还不算完,除了上述的生成图片的四种效果,NÜWA 还可以生成视频!
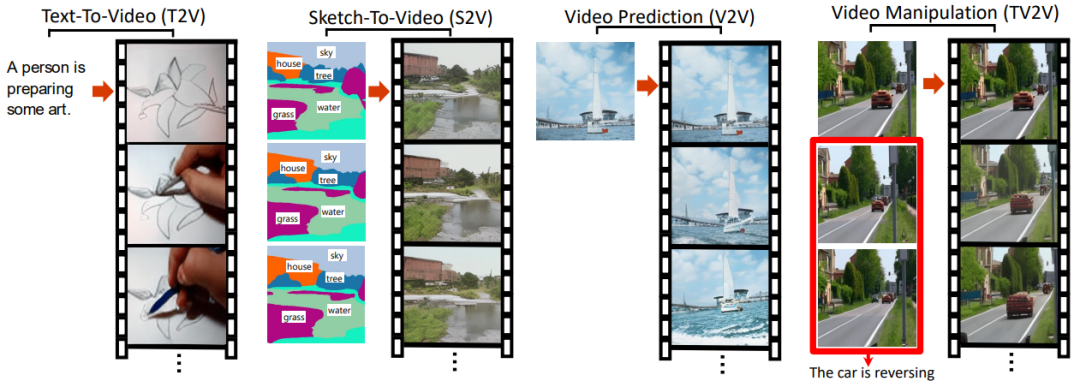
对应的四种视频生成任务:
Text-To-Video (T2V) Sketch-To-Video (S2V) Sketch-To-Video (S2V) Video Manipulation (TV2V)
既可以玩图片又可以玩视频。

NÜWA 原理
NÜWA模型的整体架构包含一个支持多种条件的 adaptive 编码器和一个预训练的解码器,能够同时使图像和视频的信息。
对于图像补全、视频预测、图像处理和视频处理任务,将输入的部分图像或视频直接送入解码器即可。
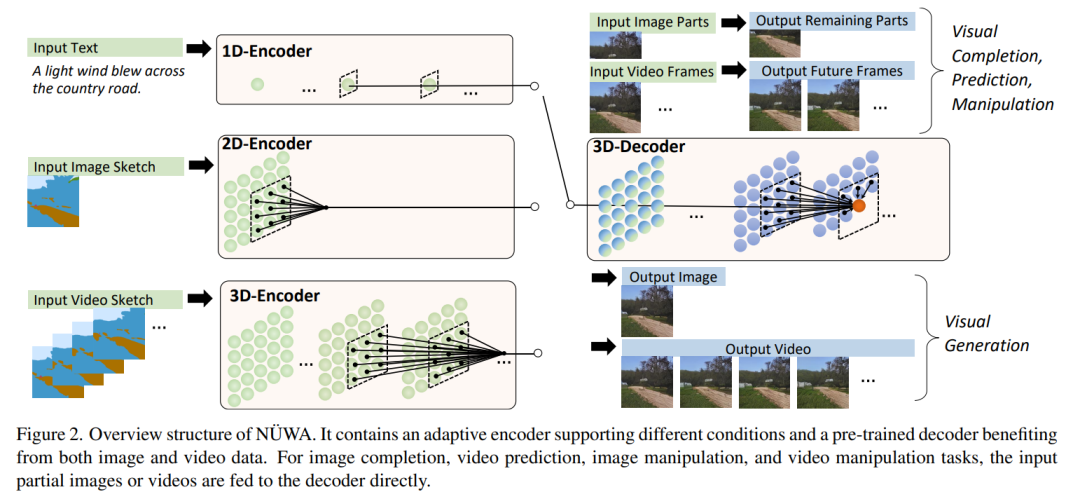
而编码解码器都是基于一个3D Nearby的自注意力机制(3DNA)建立的,该机制可以同时考虑空间和时间轴的上局部特性,定义如下:
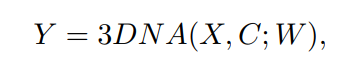
W 表示可学习的权重,X 和 C 分别代表文本、图像、视频数据的 3D 表示。
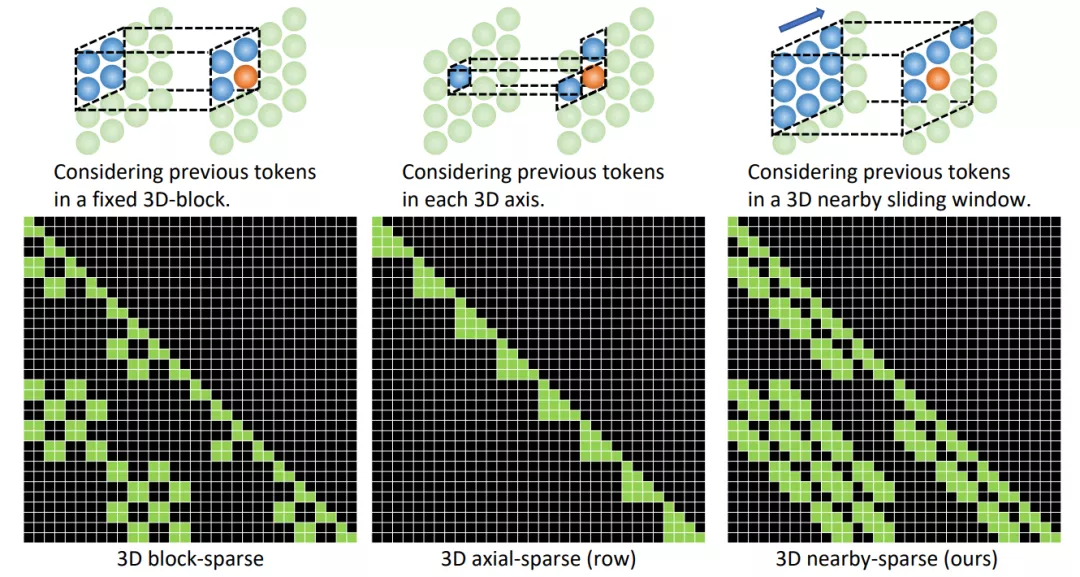
3DNA 考虑了完整的邻近信息,并为每个 token 动态生成三维邻近注意块。注意力矩阵还显示出 3DNA 的关注部分(蓝色)比三维块稀疏注意力和三维轴稀疏注意力更平滑。
更多细节,可以直接看论文:
论文地址:
https://arxiv.org/abs/2111.12417
NÜWA 代码
NÜWA 的代码还没有开源,不过 Github 已经建立。
Github:
https://github.com/microsoft/NUWA
作者表示,很快就会开源:

公司有开源审批流程,代码也得梳理下,所以可以先 Star 上标记下,耐心等等。
微软亚研院和北大联合打造的一个多模态预训练模型 NÜWA,在首届微软峰会上亮相过。
这种应该不会鸽的~
总结
今年算是多模态 Transformer 大力发展的一年,从各种顶会的论文就能看出,各种多模态。
