
女娲算法,杀疯了!
Python涨薪研究所
共 1668字,需浏览 4分钟
·
2021-12-15 19:24

源 / 文/
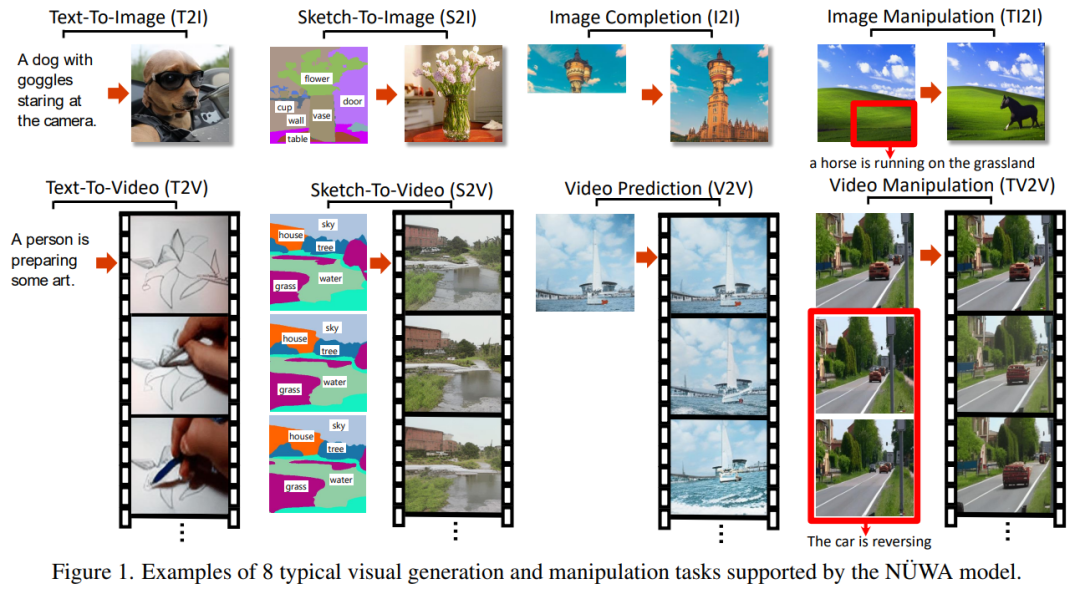
NÜWA 效果
Text-To-Image(T2I)
A dog with gogglesstaring at the camera.


Sketch-To-Image (S2I)
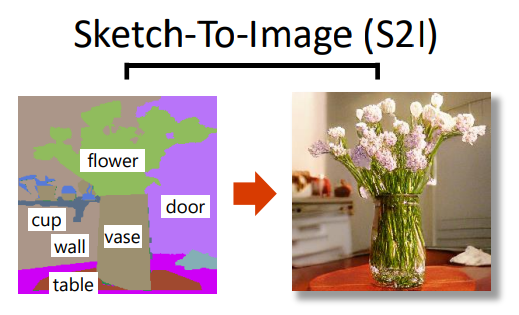
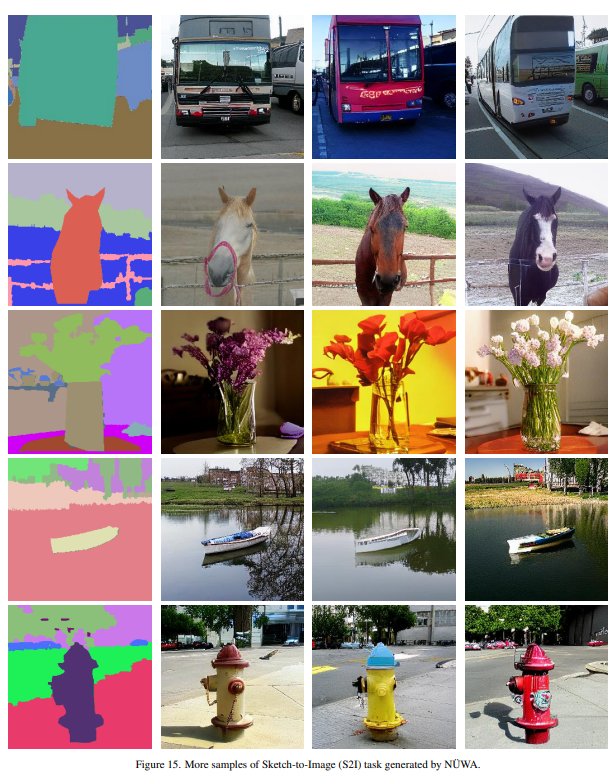

Image Completion (I2I)

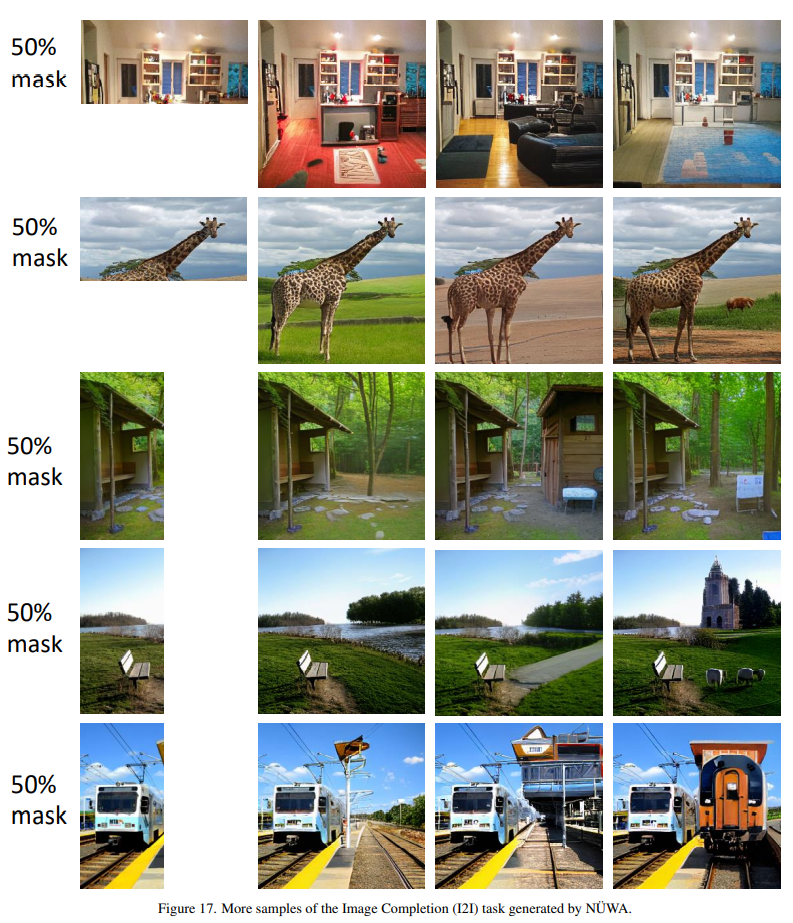
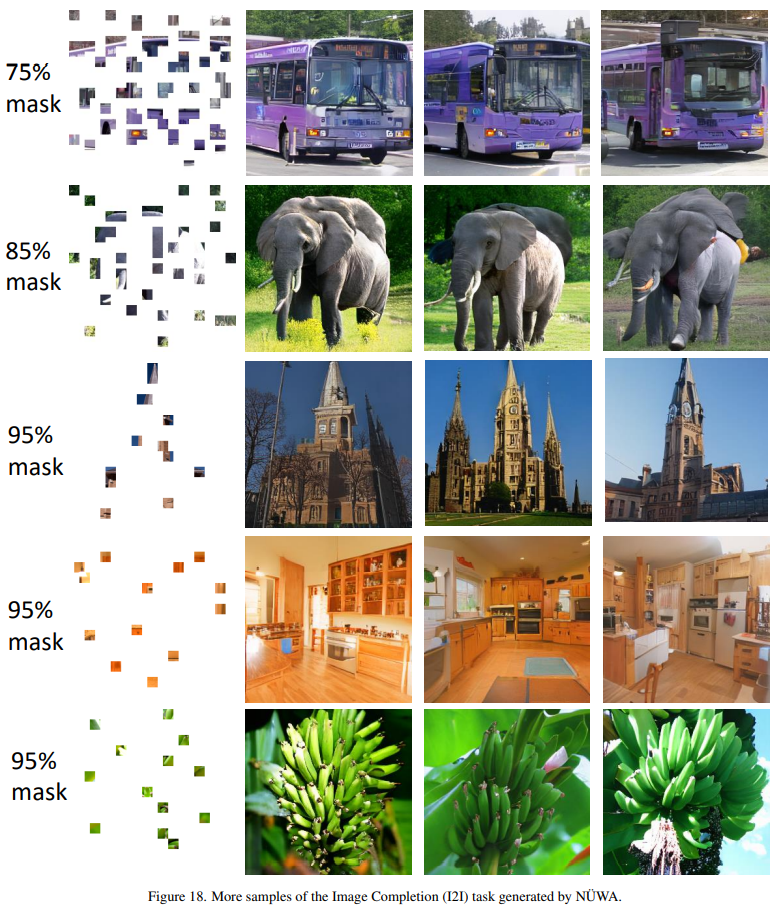
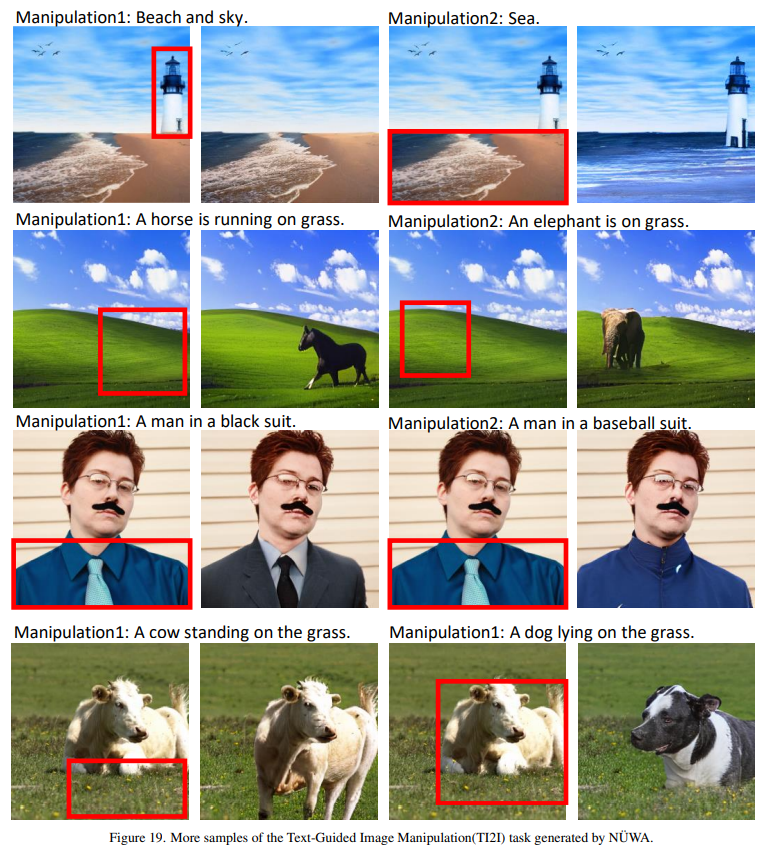
Image Manipulation (TI2I)
a horse is running on the grassland
Video
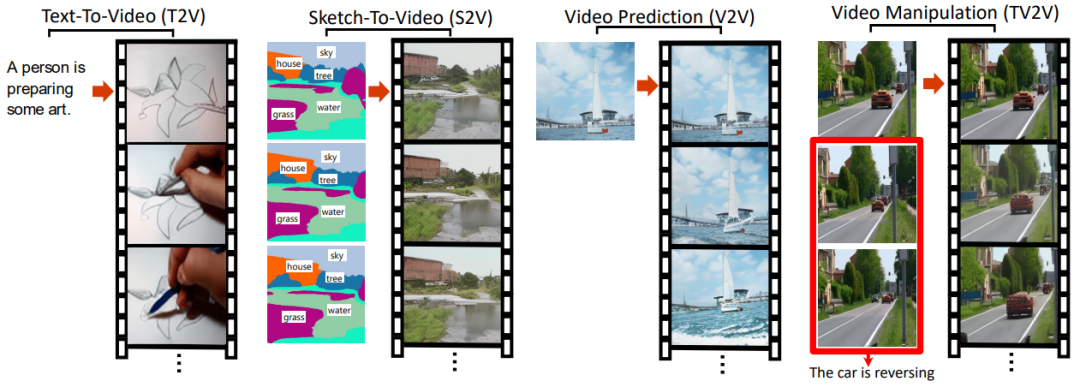
Text-To-Video (T2V) Sketch-To-Video (S2V) Sketch-To-Video (S2V) Video Manipulation (TV2V)

NÜWA 原理
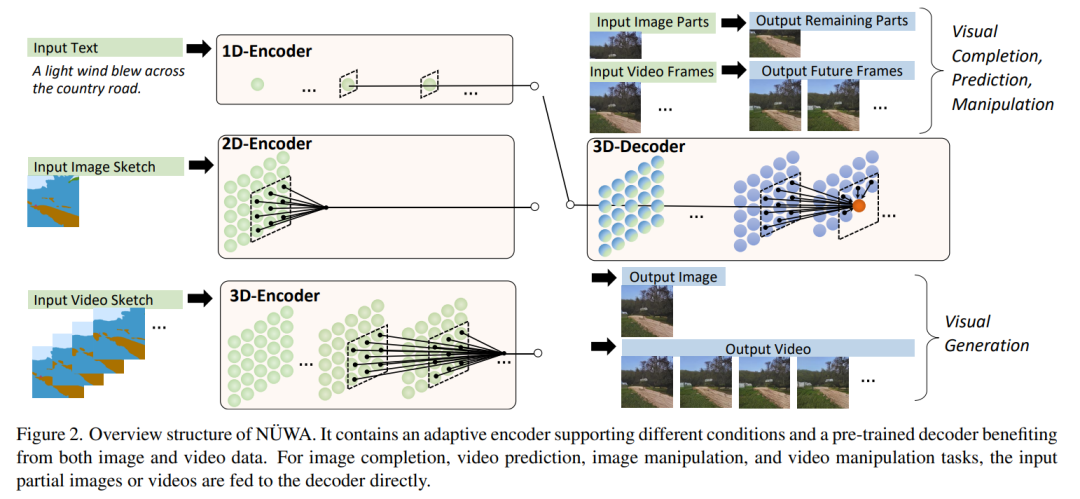
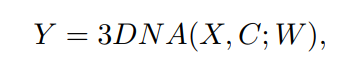
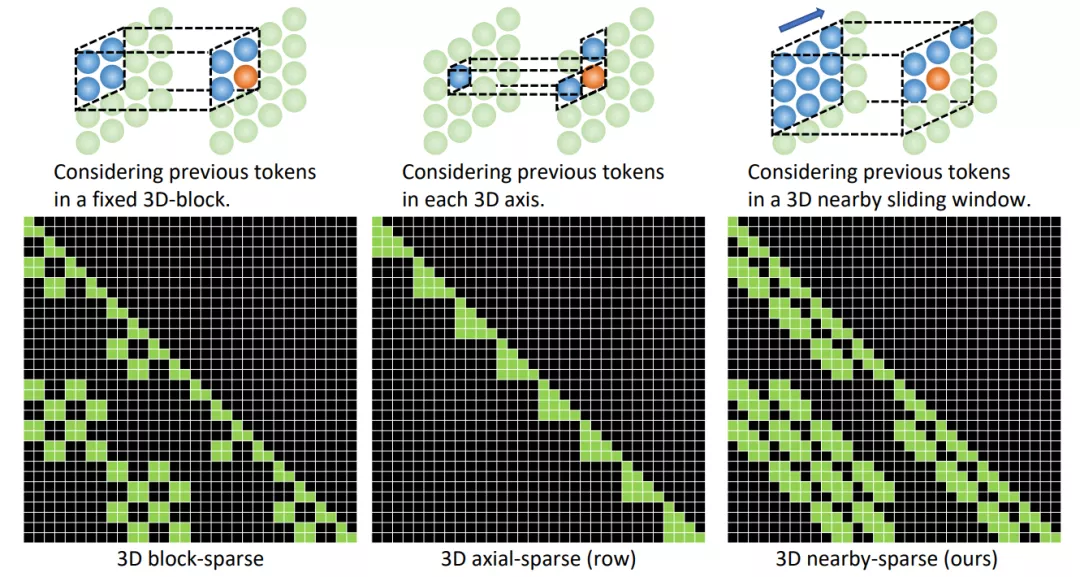
论文地址: https://arxiv.org/abs/2111.12417
NÜWA 代码
Github: https://github.com/microsoft/NUWA
总结
END


顶级程序员:topcoding
做最好的程序员社区:Java后端开发、Python、大数据、AI
一键三连「分享」、「点赞」和「在看」
评论