
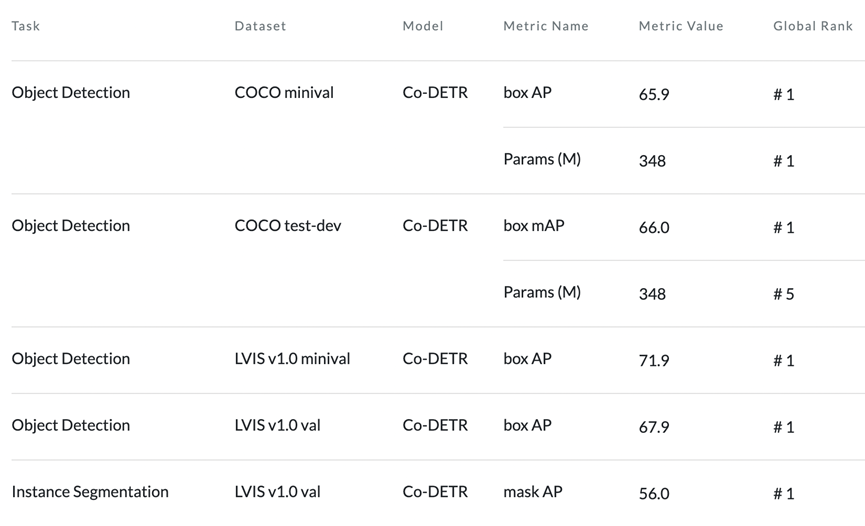
Co-DETR突破目标检测大模型上限
商汤基模型团队提出了一种适用于DETR检测器的训练框架Co-DETR,可以在不改变推理结构和速度的情况下大幅提升模型性能。这是第一个在COCO上达到66.0AP的检测器,仅使用304M参数的ViT-L。Co-DETR在目标检测的多个重要benchmark上取得了全线第一的成绩。此外,本研究在长尾分布的LVIS数据集上也取得了大幅领先,在val和minival验证集上分别比之前的SOTA方法高+2.7AP和+6.1AP。
论文名称:DETRs with Collaborative Hybrid Assignments Training

排名查看链接:https://paperswithcode.com/paper/detrs-with-collaborative-hybrid-assignments

概述
稀疏的监督信号会对检测器的学习能力造成什么影响?DETR检测器的收敛慢问题是稀疏的监督使得学习不充分导致的吗?
当前的DETR检测器中,为了实现端到端的检测,使用的标签分配策略是二分匹配,使得一个ground-truth只能分配到一个正样本。
在这种情况下,只有非常少部分的稀疏的query作为正样本,接收到回归的监督。这种稀疏的监督信号具体会对检测器学习能力的哪些方面造成影响目前是未知的。此外,也没有相关的量化指标可以来衡量这种影响究竟有多大。
为了进一步探究这些问题,我们首先可视化了Deformable-DETR+R50 encoder输出的特征图。
由图可以看出,Deformable-DETR特征的可视化一团糟,基本无法看出其与原图中物体的任何联系。此外,在特征图的边缘还会出现一些奇怪的高激活pattern。

然而,与上文的二分匹配相反,在传统的检测器(如Faster-RCNN、ATSS)中,一个ground-truth会根据位置关系分配到多个anchor(为了方便阐述,本文将anchor、proposal、point等先验统称为anchor)作为正样本。
考虑到anchor在特征图上密集排列,一个点可能对应多个不同大小和长宽比的anchor,以及不同大小的物体会匹配到不同尺度的anchor。那么这种一对多的分配方式就能够提供dense且尺度敏感的监督信息,由此我们猜想,这种标签分配方式能够为特征图上的更多区域提供位置监督,就能让检测器的特征学习得更好。
为了比较这两种不同的标签分配方法在特征图上的差异,我们直接把Deformable-DETR的decoder换成了ATSS head,使用相同的可视化方法进行了比较。
如图所示,ATSS的特征图可视化中高激活区域很好地覆盖了图片中的前景部分,而背景部分则基本没有激活。结合这些可视化结果,我们认为正是这两种分配方式的差异使得DETR模型中的encoder特征表达能力减弱了。
除了可视化,我们也构造了一个衡量特征图和attention discriminability的指标,目的是为了把可视化的结果进行量化,其具体计算方式如下。简单地说,就是计算出每个尺度特征的L2 norm,进行归一化后再在尺度上进行平均。
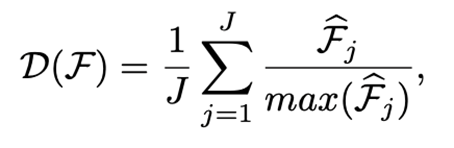
在得到discriminability score后,我们计算出其对于前景和背景的响应程度,使用IoF-IoB曲线进行了定量分析,IoF和IoB的计算方式类似,如下公式。
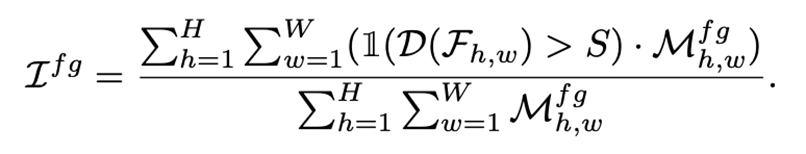
简单地说,就是把目标框内部的像素点都视为前景,框外的为背景,然后就可以得到前景和背景相应的掩码。根据这个掩码和discriminability score就可以进行IoF和IoB的计算。
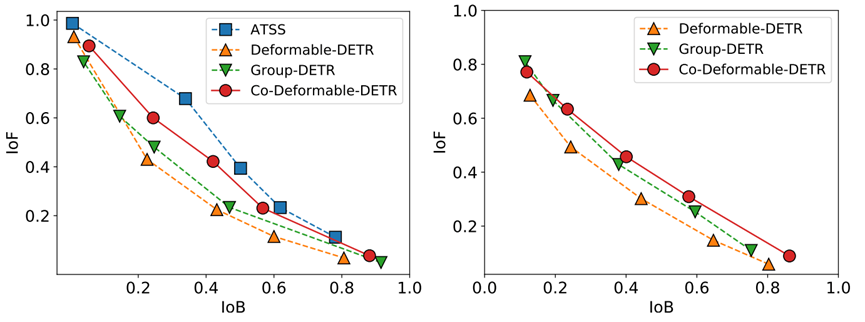
通过IoF-IoB曲线,我们发现一对一的匹配会分别损害encoder特征和decoder中attention的学习。那么在这种情况下能不能让DETR模型既享受到一对一匹配带来的端到端推理能力,又能够像一对多匹配那样feature和attention学得更好?本文将根据可视化和指标分析的结果,从两方面对这些问题进行探索。
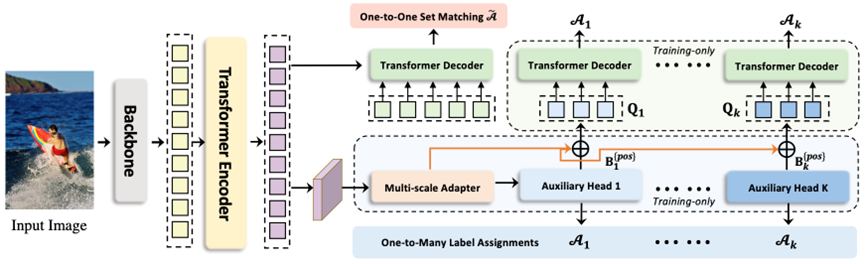
为了能够让DETR检测器利用到一对多匹配的优势,我们基于DETR的训练框架引入了两点改进,分别对应到上文提到的encoder feature learning和decoder attention learning。新加入的模块在训练后不再使用。
(1)在上文的分析中,我们发现在encoder后插入一个传统的ATSS检测头就能让encoder的特征更加显著。
受到这个的启发,为了增强encoder的学习能力,我们首先利用multi-scale adapter,将encoder输出的特征转化为多尺度的特征。
对于使用单尺度特征的DETR,这个adapter的结构就类似于simple feature pyramid。而对于多尺度特征的DETR,这个结构就是恒等映射。之后我们将多尺度的特征送入到多个不同的辅助检测头,这些检测头都使用一对多的标签分配。
由于传统检测器的检测头结构轻量,因此带来的额外训练开销较少。
(2)为了增强decoder的attention学习,我们提出了定制化的正样本query生成。
在上文的分析中,我们发现传统检测器中的anchor是密集排列的,且能够提供dense且尺度敏感的监督信息。
那么我们能不能把传统检测器中的anchor作为query来为attention的学习提供足够的监督呢?当然是可以的,在上一步中,辅助的检测头已经分配好了各自的正样本anchor及其匹配的ground-truth。
我们选择直接继承辅助检测头的标签分配结果,将这些正样本anchor转化为正样本query送到decoder中,在loss计算时无需二分匹配,直接使用之前的分配结果。
与其他引入辅助query的方法相比,这些工作会不可避免地引入大量的负样本query,而我们只在decoder引入了正样本,因此带来的额外训练代价也较小。
结果
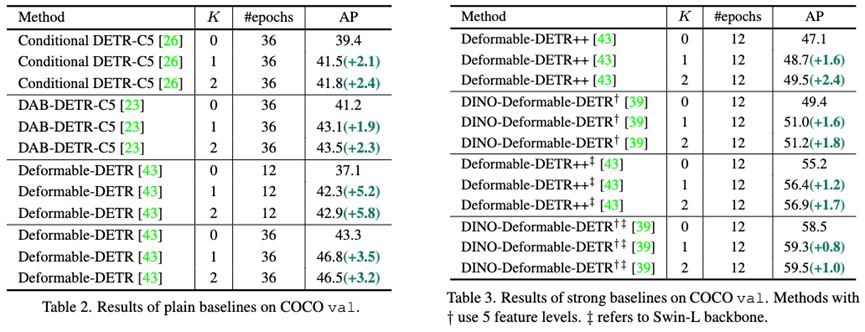
我们首先在多个单尺度和多尺度DETR模型上进行了实验,Co-DETR均能带来较大提升,尤其是SOTA模型DINO-5scale能从49.4涨到51.2,差不多是2个点的增幅。此外我们也在更大的backbone上实验,例如Swin-L,结果显示也能够带来1.7个点的提升。
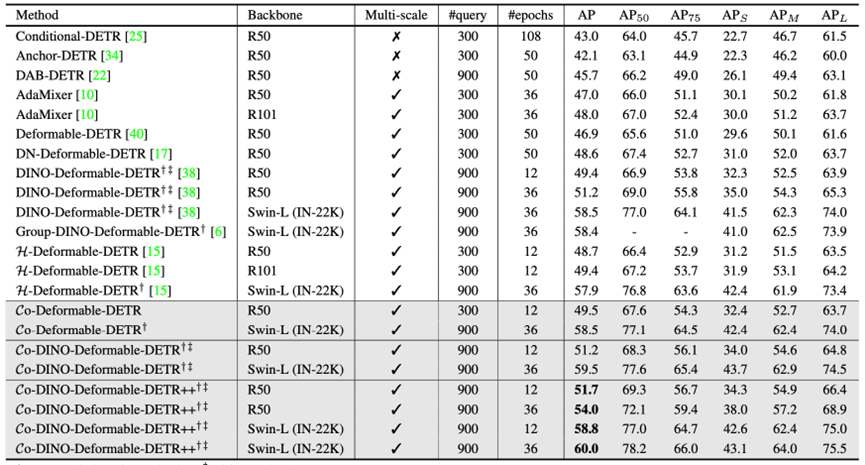
当我们将Co-DETR应用到DINO上时,我们使用了R50和Swin-L作为骨干网络。在相同模型规模的对比下,我们都能够取得最佳的性能表现。
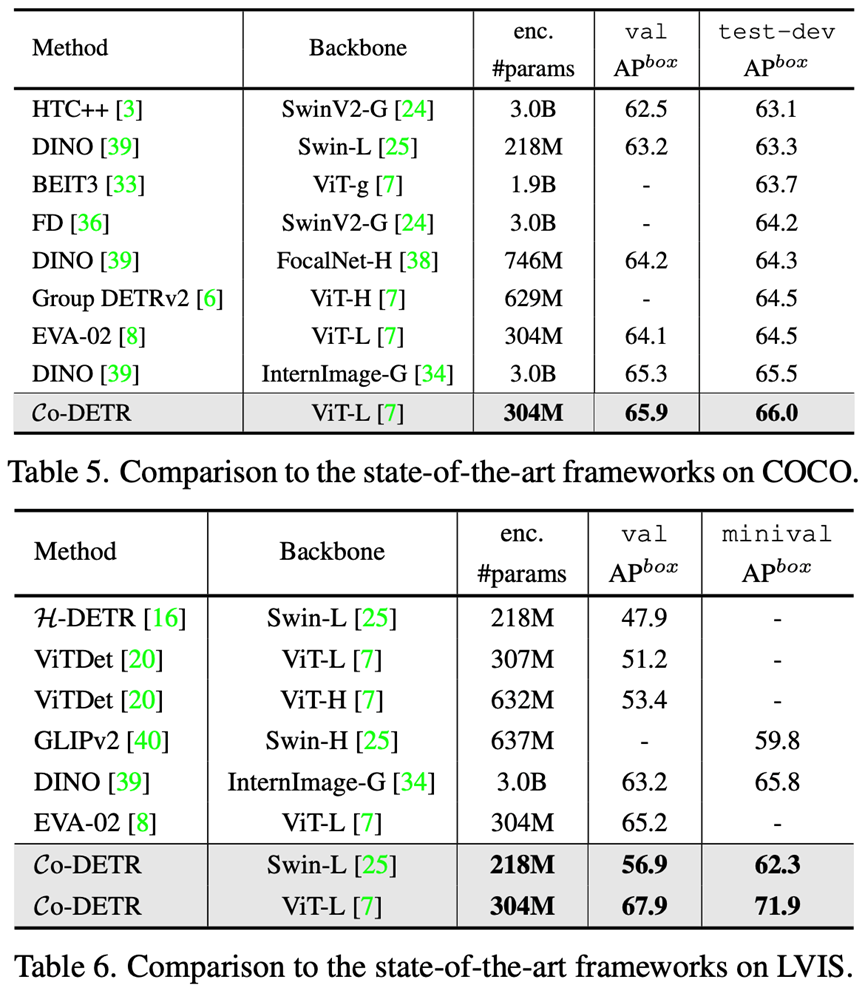
我们还在大模型上对所提出的Co-DETR有效性和scale up能力进行了验证。进行这个验证的原因是,在大模型的巨大参数加持下,许多方法之间的差异都会被直接抹平。我们使用304M参数的ViT-L作为骨干网络,先在Objects365数据集上进行预训练,再在下游进行微调。在COCO数据集进行微调后,Co-DETR在大模型的加持下进一步突破目标检测性能上限,成为第一个到达66.0AP的检测器。
此外,我们也在长尾分布的数据集LVIS上进行了微调,训练过程中只使用检测框进行监督。Co-DETR分别在LVIS val和minival上取得了67.9AP和71.9AP的成绩,分别比之前的SOTA方法高+2.7AP和+6.1AP,取得了非常明显的性能领先。
本研究也在消融实验方面对提出的方法进行了研究,例如选择辅助头的标准、多个不同标签分配策略的辅助头带来的冲突等等。
我们观察到,当使用的不同辅助头的数量变多时,模型的性能会先上升再下降。本研究对此进行了定量分析,指出了是辅助头之间的冲突造成的,并且提出了衡量冲突程度的指标。根据这个指标,我们计算了多种类型的辅助头造成的冲突有多大以及最优的选取策略。