
MPASNET:用于视频场景中无监督深度人群分割的运动先验感知SIAMESE网络
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


人群分割是拥挤场景分析的基础任务,获取精细的像素级分割图是人们非常希望实现的。然而,这仍然是一个具有挑战性的问题,因为现有的方法要么需要密集的像素级注释来训练深度学习模型,要么仅仅从光学或粒子流与物理模型生成粗略的分割地图。在本文中,作者提出了运动先验感知Siamese网络(MPASNET)用于无监督人群语义分割。这个模型不仅消除了注释的需要,而且产生了高质量的分割图。特别地,作者首先分析帧间的相干运动模式,然后对集合粒子采用圆形区域合并策略生成伪标记。此外,作者为MPASNET配备了siamese分支,用于增强不变正则化和siamese特征聚合。在基准数据集上的实验表明,作者的模型在mIoU方面的性能优于目前最先进的模型12%以上。
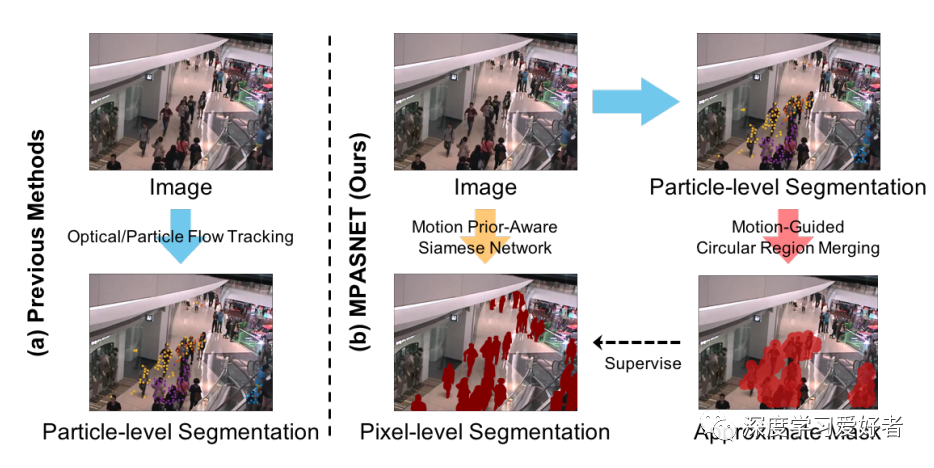
MPASNET与以往方法的比较
据作者所知,这项工作是第一个专注于人群分割的基于无监督深度学习的模型。作者的贡献总结如下:
作者重新讨论了基于运动相似度的方法,并提出了以集体运动粒子为中心的掩模圆形区域合并来产生近似的标注用于深度人群分割。
作者设计了一个端到端的暹罗网络和相关的损耗函数来学习自生成的伪标签。
作者在两个有代表性的数据集上评估了作者的无监督方法,显著优于最先进的方法。
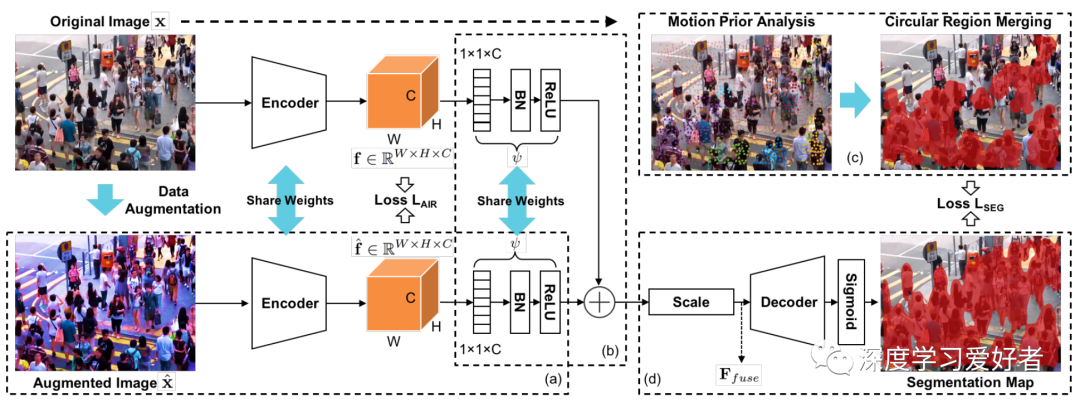
提出的MPASNET结构。(a)以增广图像为输入的暹罗分支。(b)暹罗特征聚合。(c)运动引导圆形区域合并的伪标记。(d)分割头。
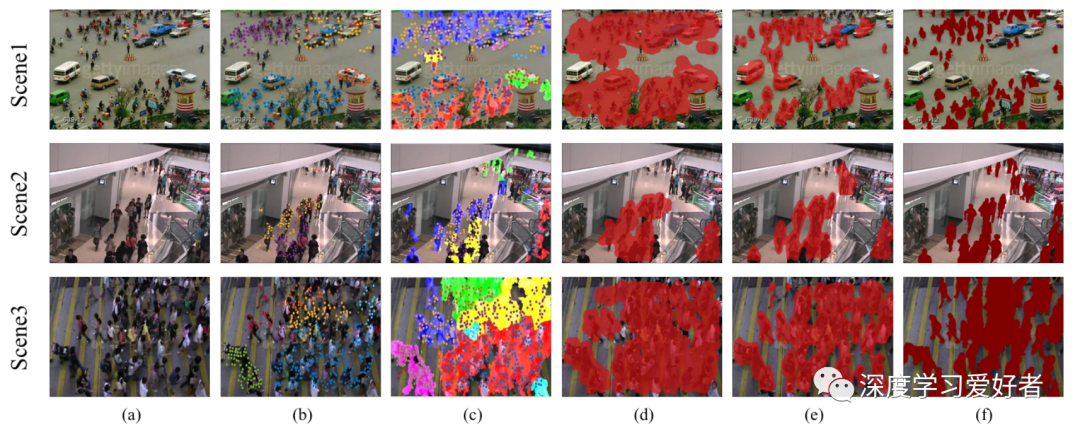
与最新方法的定性比较。(一)原始帧。(b) CM[4]提取的运动粒子。(c) CrowdRL的分割结果。(d) CM合成的圆形区域合并伪标签。(e) MPASNET分割结果。(f)地面真理。作者的方法比其他方法有了明显的改进。
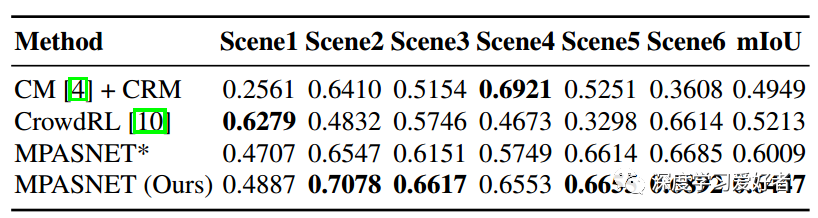
在IoU方面与最新方法的定量比较。MPASNET*表示没有siamese分支的训练MPASNET(即没有augmented - invariant regularization and siamese feature aggregation)。
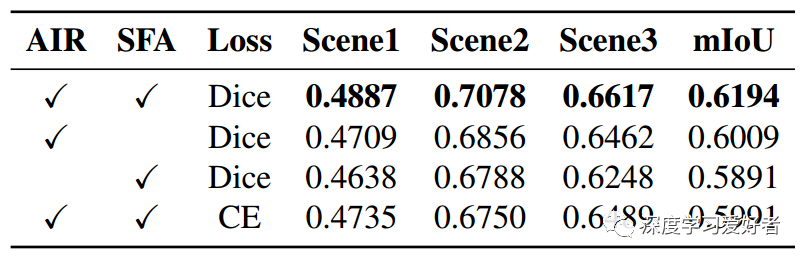
每个成分的影响。AIR:增广不变正则化。SFA:Siamese特性聚合。Dice:Dice损失。CE:交叉熵损失。
在本文中,作者提出了用于无监督深度人群语义分割的MPASNET。与现有的方法不同,作者的模型利用运动先验生成伪标签,无需人工操作,从而学习在缺乏地面真相的情况下生成高质量分割地图。实验表明,与最先进的无监督方法相比,作者的框架取得了实质性的改进。
论文链接:https://arxiv.org/pdf/2101.08609.pdf
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~